

原子元素和指标
原子元素:在模型已经定义好能够被模型识别的字段和度量。
指标:由原子元素通过SQL表达式定义。
衍生指标: 由指标通过SQL表达式定义。
解析过程
Headless接收到由Chat发来的SQL查询时,主要通过指标识别-定义拆解-指标替换三个步骤进行解析。
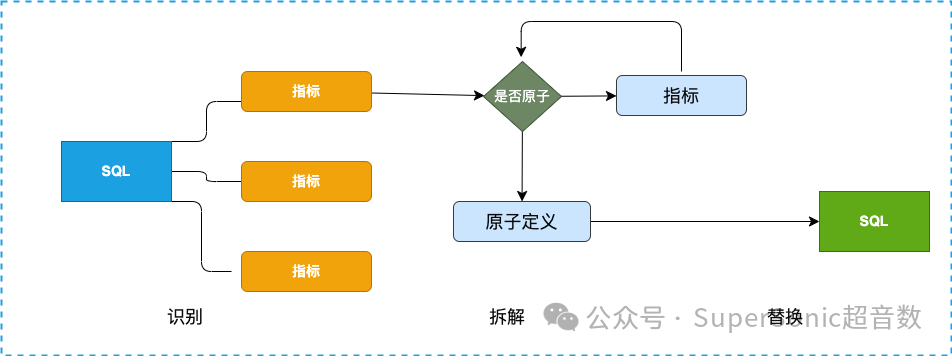
以下通过一个例子进行说明
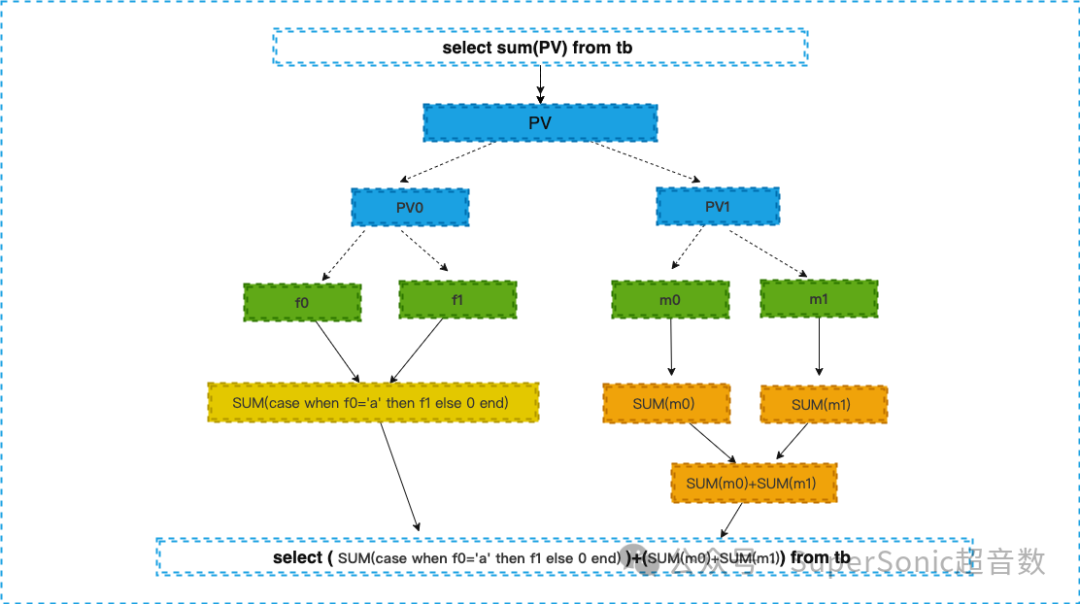
指标 PV=PV0+PV1
PV0=SUM(case when f0='a' then f1 else 0 end)
PV1=m0+m1
其中PV PV0 PV1 为指标,f0,f1 为字段,m0,m1为度量
select sum(PV) from tb--PV是一个指标定义,原始模型中并不存在,直接交由引擎无法查询--解析后变成select ( SUM(case when f0='a' then f1 else 0 end) )+(SUM(m0)+SUM(m1)) from tb--f0,f1,m0,m1都是模型中存在的原始字段,查询可以直接识别
注意事项
1. 指标不可引用自身指标
指标的拆解存在一个循环递归的过程,引用自身指标进行定义会导致无法跳出拆解过程,目前后台界面对此做了限制,不允许引用一个非字段非度量定义的指标。
2. 表达式要符合规范
(1)表达式采用SQL进行定义,因此需要符合通用的SQL表达式语法,否则SQL解析失败,指标将无法正常替换。
(2)表达式引用的字段,度量,指标需要从待选列表中选择,否则解析时无法识别到引用的元素时,指标将无法正常替换。
