

一、显存需求的计算逻辑
参数规模与显存的关系
模型显存占用主要由三部分构成:
-
模型参数:FP16精度下每个参数占2字节,INT8占1字节 -
推理缓存:包括激活值、注意力矩阵等中间变量 -
系统开销:CUDA上下文、框架内存管理等额外消耗
基础计算公式:
其中:
-
精度系数:FP16为2,INT8为1,4bit量化可降至0.5 -
安全系数:建议取1.2-1.5(预留缓存和系统开销)
典型场景计算示例以DeepSeek-7B模型为例
-
FP16模式:7B×2×1.3=18.2GB -
8bit量化:7B×1×1.3=9.1GB -
4bit量化:7B×0.5×1.3=4.55GB
二、模型规模与显卡推荐对照表
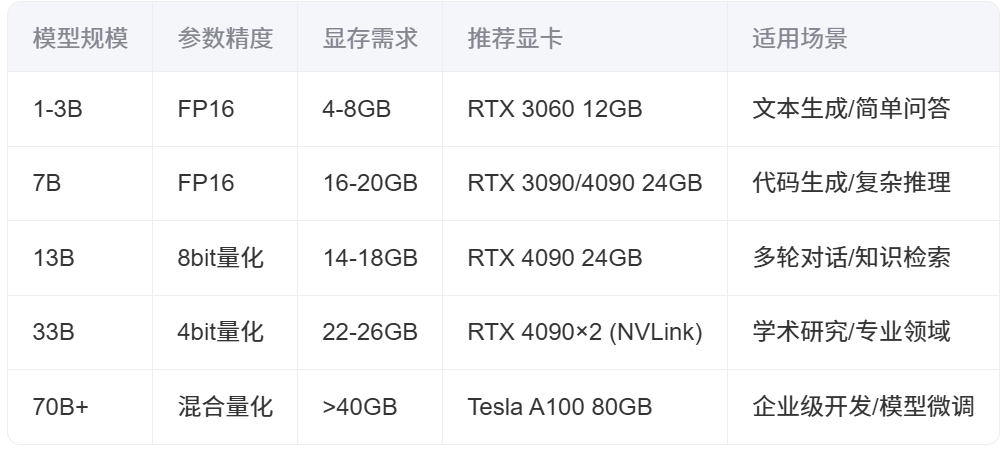
|
量化类型 |
显存压缩率 |
性能损失 |
|
FP32→FP16 |
50% |
<1% |
|
FP16→INT8 |
50% |
3-5% |
|
INT8→INT4 |
50% |
8-12% |
2.框架级优化
-
vLLM:通过PagedAttention技术减少KV Cache碎片化,32B模型显存占用降低40% -
Ollama+IPEX-LLM:在Intel Arc显卡上实现7B模型核显部署,CPU协同加速
3. 硬件采购建议
性价比优先级:
-
显存容量 > 算力(显存不足时算力无法发挥)
-
选择支持Resizable BAR技术的显卡(提升多卡通信效率30%)
-
优先考虑能效比(如RTX 4090的TOPS/Watt比3090高58%)
-
模型轻量化:通过MoE架构和动态路由,670B级模型可压缩至单卡24GB显存内运行 -
硬件平权化:Intel核显通过IPEX-LLM已支持7B模型,未来XeSS技术或实现32B模型消费级部署
-
短期:按“显存公式×1.2”预留冗余,选择支持量化技术的显卡(如RTX 4060 Ti 16GB) -
长期:关注Blackwell架构(RTX 50系列)的4位量化支持,预计2025年底实现70B模型单卡部署
