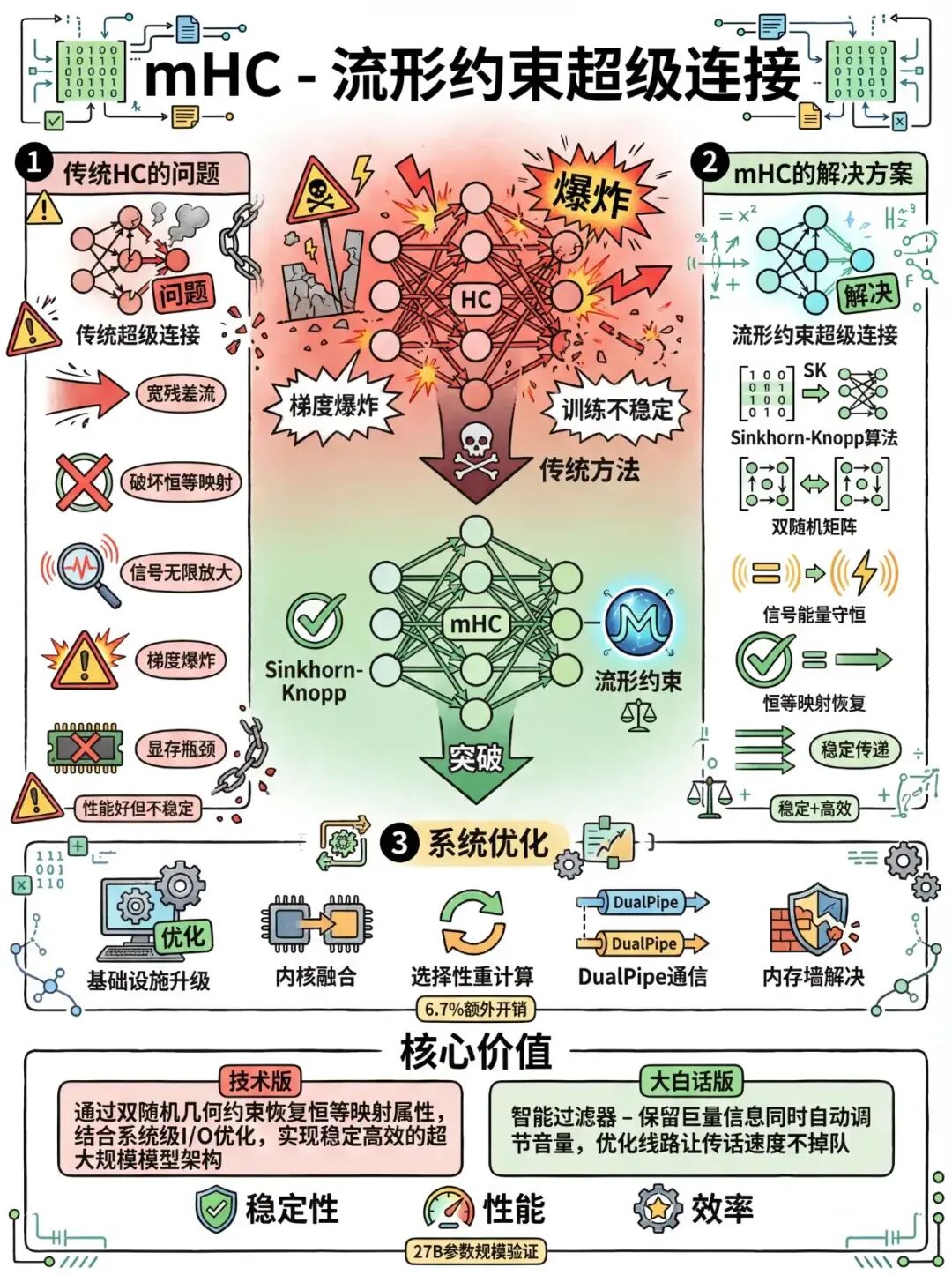
DeepSeek 发布新论文,提出全新 MHC 架构,有何创新与应用前景? 前沿技术 新闻资讯 模型微调 5月7日 编辑 charles 取消关注 关注 私信 2026 年的第一天,我发现 DeepSeek 悄悄干了件狠事。他们发布了一篇论文,梁文锋署名。 这篇论文讲了一个新架构,叫 mHC 流形约束超连接。 别被名字吓跑,这件事情的本质,是在挑战 AI 圈儿过去十年的绝对真理。 要把这事儿聊清楚,得把时间拨回到 2016 年。 那一年,何恺明大神提出了 ResNet 残差网络。 这玩意就像建筑里的钢筋混凝土,成了所有大模型的地基。 十年了,所有人都觉得地基没问题。 大家都在忙着往上盖楼,比谁的楼更高,比谁的装修更豪华。 但 DeepSeek 拿着放大镜蹲在楼下花园里说。 这配方,还能改。 原来的配方有啥问题? 简单说,就是嗓门太大。 训练大模型就像几百人排队玩传话游戏,原来的 ResNet 为了防止传话失真,允许后面的人直接听前面的喊声。 为了保留信息,大家不得不不断提升嗓门的音量。 模型一旦做宽做深,整个房间里全是震耳欲聋的噪音。 这时候别说传话了,负责听话的人都已经被震聋了,训练当场崩溃。 这就是为什么 AI 训练,经常炸机。 DeepSeek 的 mHC 架构,相当于给每个人都发了一个智能调音台,也就是流形约束。 它干了两件事。 1、保真,信息量一点不少,全都传下去。 2、降噪,自动把音量调节到最舒服最清晰的频段。 不管外面如何喧嚣,传到下一层的信号,永远是干净稳定的。 不管外面如何喧嚣,传到下一层的信号,永远是干净稳定的。 效果咋样呢? DeepSeek 在 27B 的模型上做了实测,虽然加上智能调音台,训练时间增加了 6.7%。 但在动辄几千万美元的训练成本面前,多花点时间,换来的是模型性能的显著提升,和绝不炸机的安全感。 这笔帐,只能说算的太精了。 在 AI 这个行业里,最容易走的路就是大力出奇迹。 但最难的路,是回头审视那些大家都习以为常的事物,去优化最底层的数学公式。 这,才是真正的降维打击。 写到这里,我突然有点感动。 在这个全员加速,甚至有点疯狂的 AI 时代。 有太多人喊着要造神,要改变世界,要替代人类。 但 DeepSeek 选择了一条最不性感的路,去拧紧地基里的一颗螺丝。 这种脚踏实地理性的光芒,我觉得才是最美丽,最珍贵,最值得敬佩的。 2026 年,期待 DeepSeek V4。 期待理性的光。