

想让你的AI助手不仅会写代码,还能自主复现顶级论文?这里有一份包含74项“科研必杀技”的开源库,从模型微调到分布式训练,把你的Coding Agent升级为全能科研专家!
📉 痛点:科研路上的“环境配置地狱”
对于计算机专业学生和AI研究员来说,最大的痛苦往往不是提出假设,而是验证假设的过程:
-
• 想复现一篇论文,结果在配置 Megatron-LM 分布式环境上卡了三天; -
• 试图微调 Llama 3,却在 DeepSpeed 和 FSDP 的参数设置中迷失方向; -
• 为了优化推理速度,要在 vLLM 和 TensorRT-LLM 之间反复踩坑……
科学家的时间应该花在思考上,而不是在修修补补基础设施上。 如果你的 AI 编程助手(如 Claude, Cursor)能像一个经验丰富的工程师一样,熟练掌握这些工具,会是怎样的体验?
💡 方案:不仅是代码库,更是AI的“技能树”
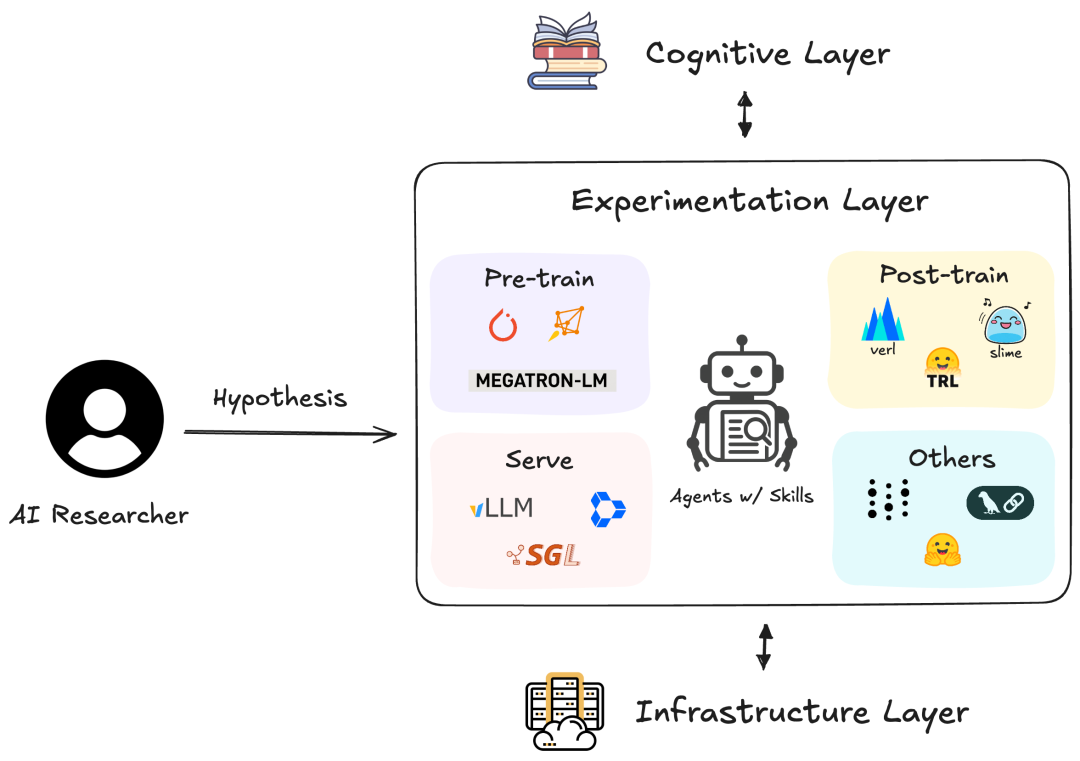
AI Research Engineering Skills Library 就是为此而生。
它不是一个普通的 Python 包,而是一个专为 AI Agent(智能体)设计的“技能知识库”。它包含 74 项经过实战验证的工程技能,涵盖了从数据处理、模型架构、微调、评估到部署的全生命周期。
通过注入这些技能,你的 AI Agent 将不再是一个只会写 Hello World 的新手,而是一个懂 RAG、精通 MLOps、能驾驭 H100 集群的资深研究工程师。
🚀 核心功能:74项硬核技能全覆盖
这个项目将 AI 科研所需的复杂能力拆解为 18 个核心版块,每一个技能都源自生产环境或官方最佳实践。
1. 深度与广度并存
这不是简单的文档搬运,而是“专家级”的经验封装:
-
• 模型架构: 包含 LitGPT, Mamba, RWKV 等前沿架构实现。 -
• 微调 (Fine-Tuning): 只有“调参侠”才懂的 Axolotl, LLaMA-Factory, Unsloth 实战技巧。 -
• 分布式训练: 搞定 Megatron-Core, DeepSpeed, PyTorch FSDP 等多卡训练难题。 -
• 推理优化: 掌握 vLLM, TensorRT-LLM, GGUF 量化,让模型跑得飞快。
2. 即插即用的“大脑插件”
无论你使用的是 Claude Code,还是 Cursor、Windsurf,甚至是自定义的 RAG 系统,这些技能文件(Markdown/YAML格式)都可以直接被 AI 读取和理解。
3. 质量优先
每一个 Skill 都包含:
-
• 权威来源: 基于官方 Repo 和真实 GitHub Issue 总结。 -
• 生产级代码: 提供经过测试的配置和代码片段。 -
• 故障排除: 预判并解决常见的报错。
🛠️ 实战案例:AI 如何利用它?
假设你想复现一项关于“RLHF(人类反馈强化学习)”的研究。
没有 Skill 库时:
你需要手动查阅 TRL 文档,编写 PPO 训练循环,调试 GPU 显存溢出错误,耗时数天。
拥有 Skill 库后:
你只需对 Agent 说:“使用 grpo-rl-training 技能帮我设置实验。”
Agent 会自动:
-
1. 读取 06-post-training/grpo-rl-training中的最佳实践; -
2. 生成基于 TRL 库的训练代码; -
3. 配置好 Ray 和 vLLM 进行高效的数据生成; -
4. 自动规避常见的显存碎片化问题。
⚡ 快速上手指南
你可以通过多种方式使用这个强大的知识库。
方法一:Claude Code (官方推荐)
如果你有 Claude Code 权限,可以直接通过插件安装:
# 安装单个技能(例如 vLLM 推理服务)
/plugin install serving-llms-vllm@ai-research-skills
# 安装 LangChain 技能
/plugin install langchain@ai-research-skills
对于大多数开发者,手动导入是最快的方式:
-
1. 下载项目仓库。 -
2. 将你需要的技能文件夹(例如 03-fine-tuning/axolotl/)拖入你的 IDE 项目中。 -
3. 在对话框中引用该文件夹作为上下文(Context)。
User: @axolotl 帮我写一个微调 Llama-3-8B 的配置文件,使用 QLoRA 减少显存占用。
