
Why Knowledge Graphs are Critical to Agent Context
摘要
传统的长上下文窗口、向量数据库和RAG方案虽能提供语义相关检索,但在精准性、推理性和可解释性上存在不足。知识图谱通过建模实体及其关系,为智能体提供精准、可解释、覆盖全面的上下文,为企业与科研机构的智能应用带来更高决策支持力.
正文
1. 为什么需要重新思考“上下文”
在为智能体(Agent)提供信息时,大多数现有方法依赖长上下文窗口、向量存储或传统的RAG(Retrieval-Augmented Generation)流程。虽然这些方法能找到语义相似的内容,但在需要精准性、推理能力和决策解释时,它们往往力不从心.
2. 现实案例:向量检索的局限
设想一个AI智能体负责管理战略客户关系,当你问它:
“我们与Acme公司的关系在合同续签前如何?”
传统RAG方法会将所有与Acme的沟通嵌入向量空间,并检索语义相似内容,例如:
-
“能否发一份更新的SLA,并包含新的可用性保证?” -
“我们对续约很有信心,合作一直很愉快。” -
“你们团队本季度很给力,响应速度加快,工作流程更顺畅。” 
这些回复看似相关,但无法回答关键问题:
-
这些观点是否来自真正有决策权的人? -
它们是否是最重要的信号?
语义相似度不能告诉你“是谁”说的,“为什么”重要.
3. 知识图谱的结构化回忆
如果给交流内容叠加一个知识图谱,情况就完全不同。
我们可以将公司、合同、人员、会议、沟通内容等作为实体建模,并明确标注它们之间的关系。
例如,通过知识图谱,智能体可以发现:
-
该合同绑定在特定副总裁(VP)名下,此人是关键决策者; -
从而将分析重点锁定在VP的发言上。
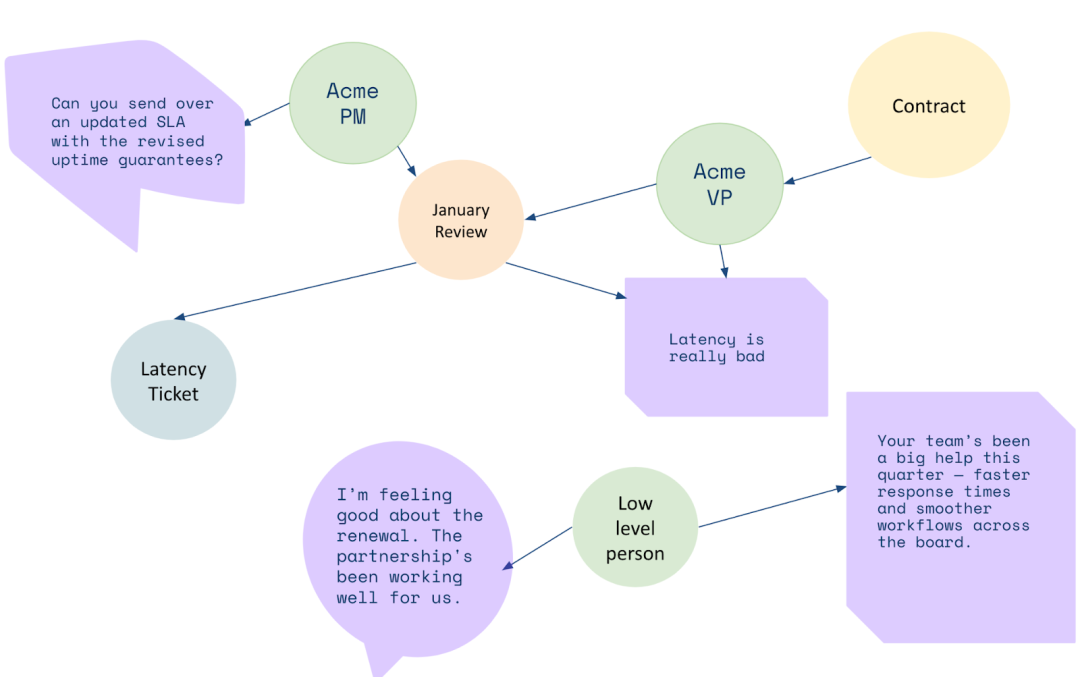 知识图谱提供了:
知识图谱提供了:
- 完整性
:涵盖所有Acme相关重要人物 - 精准性
:准确找到关键人物(VP) - 可解释性
:路径清晰可追溯 - 上下文
:明确“是谁、何时、何地”.
4. “爆炸半径”向量搜索:精准定位
Kùzu引入了“Blast Radius Vector Search”——在知识图谱的特定实体节点周围进行向量检索,而非在整个向量空间中盲搜。

这样,智能体就能在查询时获取适量且相关性极高的上下文,例如:
-
VP在上次会面中表达了对网络延迟的担忧 -
图谱还记录了会议的时间、与会者,以及其他反馈
这让智能体区分出哪些正面评价来自真正影响续约的人,哪些只是外围声音.
5. 为什么知识图谱更适合作为“智能体记忆”
知识图谱在上下文工程中的优势包括:
- 作者与情境
:明确“谁说了什么,何时何地” - 可解释性与覆盖面
:推理路径透明且可持续优化 - 动态结构
:可随新信息快速更新关系网络
这让智能体的处理方式更接近人类认知模式.
6. 技术与应用趋势
近年来,从世界500强企业到创新型初创公司,都在为智能体构建专用知识图谱,用于强化长短期记忆能力。Kùzu的优势在于:
- 开发友好
:pip install即可快速部署 - 多索引支持
:统一处理图、向量、全文检索 - 高性能
:优化应对真实业务场景 - 灵活部署
:云端、边缘、无服务器、本地均可运行.
7. 未来展望
一个新方向是:将智能体的上下文“卸载”到外部数据库而非长时间占用模型的上下文窗口。
知识图谱在构建短期与长期记忆时天然契合,例如合同续约案例中,它让智能体只保留必要且重要的信息,并在需要时高效调用.
标签
#知识图谱 #大模型 #Agent #KG #LLM #企业智能 #Graphrag
