

-
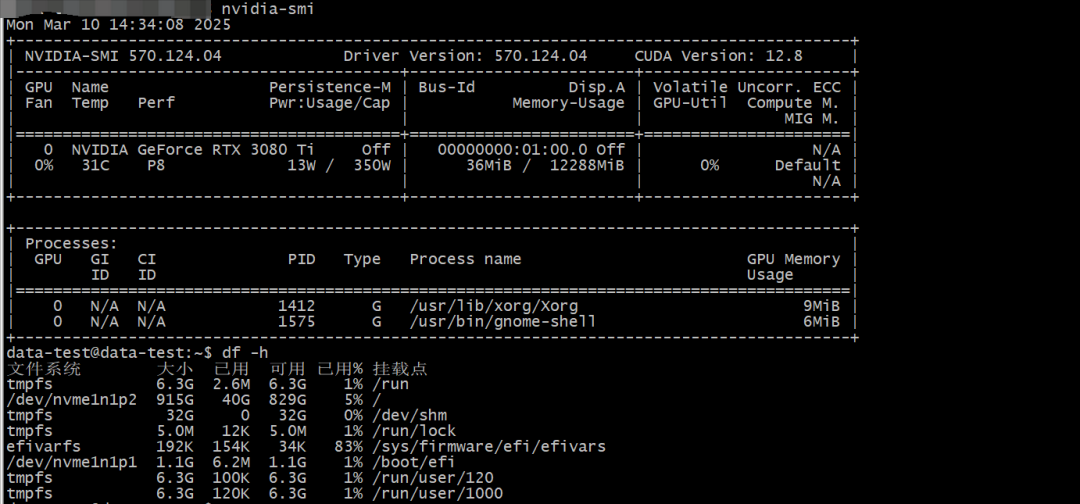
查看GPU显存 nvidia-smi
-
创建一个独立的虚拟环境并激活


-
安装vLLM

-
安装modelscope

-
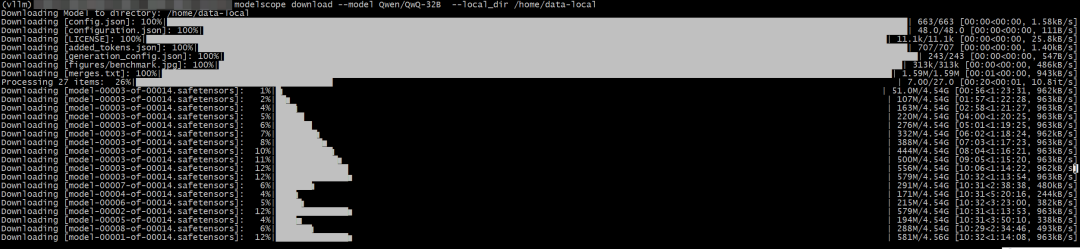
下载完整模型库




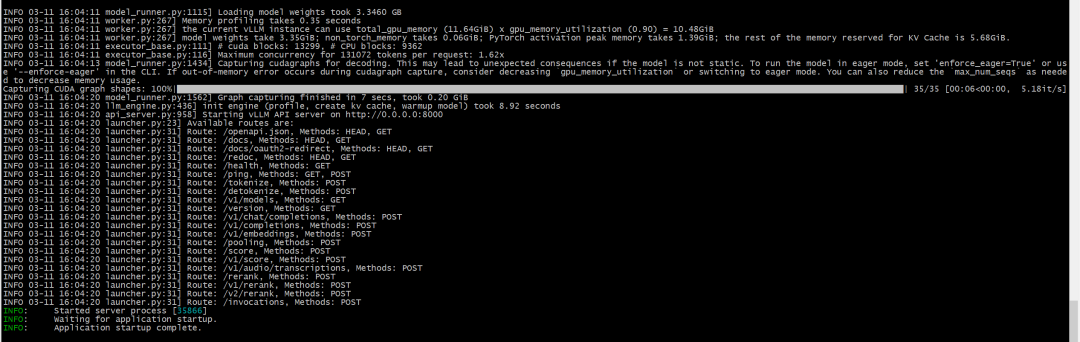
-
API接口测试
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "QWQ-32B","prompt": "你好","max_tokens": 100}'
-
通过OpenAI兼容的API调用
from openai import OpenAI# 初始化客户端(添加api_key参数)client = OpenAI( base_url="http://172.19.66.132:8000/v1", api_key="dummy" # 虚拟密钥:ml-citation{ref="1" data="citationList"})# 调用模型生成文本response = client.completions.create( model="Qwen-1.5B", prompt="如何部署大语言模型?", max_tokens=200)# 正确输出字段为response.choices.textprint(response.choices[0].text)
