

前言:大模型评测是一个系统工程,本文希望通过比较通俗的方式给大家直观感受大模型微调后的效果,相关是思路想法旨在起到抛砖引玉的效果,如果学习者对大模型评测有深厚的兴趣,可以从不同的角度进行学习。
三天前,看到了我们 Datawhale 公众号上发了文章《零基础入门:DeepSeek 微调教程来了!》反响很好,其中的内容写的非常接地气,适合学习者进行学习体验。
于是,我尝试在那篇文章的基础上进行了复现,并对内容进行了一些延伸,帮助读者更加直观的感受大模型微调对模型的调整。
为了方便学习与体验,本文中选择的模型是蒸馏后 DeepSeek-R1-Distill-Qwen-7B 模型,显卡选择是 RTX4090 24G。
Deepseek 模型以及数据集均来源于魔塔社区 medical-o1-reasoning-SFT。
1. 微调教程复现
import torch
import matplotlib.pyplot as plt
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
TrainerCallback
)
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 指定使用GPU
# 配置路径(根据实际路径修改)
model_path = "xxxx" # 模型路径
data_path = "xxxx" # 数据集路径
output_path = "xxxx" # 微调后模型保存路径
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
device = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 自定义回调记录Loss
class LossCallback(TrainerCallback):
def __init__(self):
self.losses = []
def on_log(self, args, state, control, logs=None, **kwargs):
if "loss" in logs:
self.losses.append(logs["loss"])
# 数据预处理函数
def process_data(tokenizer):
dataset = load_dataset("json", data_files=data_path, split="train[:1500]")
def format_example(example):
instruction = f"诊断问题:{example['Question']}n详细分析:{example['Complex_CoT']}"
inputs = tokenizer(
f"{instruction}n### 答案:n{example['Response']}<|endoftext|>",
padding="max_length",
truncation=True,
max_length=512,
return_tensors="pt"
)
return {"input_ids": inputs["input_ids"].squeeze(0), "attention_mask": inputs["attention_mask"].squeeze(0)}
return dataset.map(format_example, remove_columns=dataset.column_names)
# LoRA配置
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 训练参数配置
training_args = TrainingArguments(
output_dir=output_path,
per_device_train_batch_size=2, # 显存优化设置
gradient_accumulation_steps=4, # 累计梯度相当于batch_size=8
num_train_epochs=3,
learning_rate=3e-4,
fp16=True, # 开启混合精度
logging_steps=20,
save_strategy="no",
report_to="none",
optim="adamw_torch",
no_cuda=False, # 强制使用CUDA
dataloader_pin_memory=False, # 加速数据加载
remove_unused_columns=False, # 防止删除未使用的列
device="cuda:0" # 指定使用的GPU设备
)
def main():
# 创建输出目录
os.makedirs(output_path, exist_ok=True)
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token
# 加载模型到GPU
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map=device
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 准备数据
dataset = process_data(tokenizer)
# 训练回调
loss_callback = LossCallback()
# 数据加载器
def data_collator(data):
batch = {
"input_ids": torch.stack([torch.tensor(d["input_ids"]) for d in data]).to(device),
"attention_mask": torch.stack([torch.tensor(d["attention_mask"]) for d in data]).to(device),
"labels": torch.stack([torch.tensor(d["input_ids"]) for d in data]).to(device) # 使用input_ids作为labels
}
return batch
# 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
callbacks=[loss_callback]
)
# 开始训练
print("开始训练...")
trainer.train()
# 保存最终模型
trainer.model.save_pretrained(output_path)
print(f"模型已保存至:{output_path}")
# 绘制训练集损失Loss曲线
plt.figure(figsize=(10, 6))
plt.plot(loss_callback.losses)
plt.title("Training Loss Curve")
plt.xlabel("Steps")
plt.ylabel("Loss")
plt.savefig(os.path.join(output_path, "loss_curve.png"))
print("Loss曲线已保存")
if __name__ == "__main__":
main()
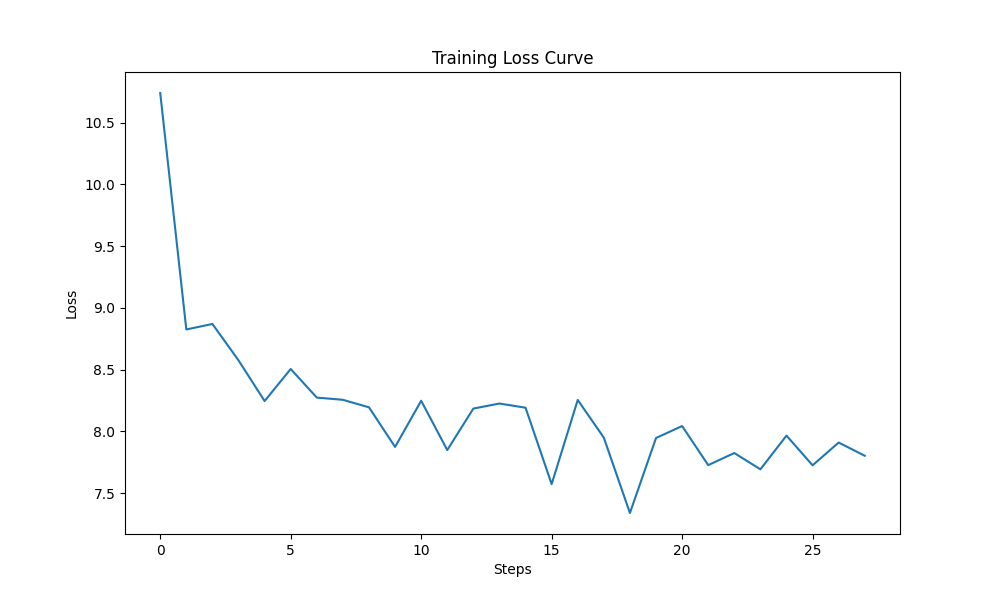
可以看到经过简单的微调,模型的 LOSS 值是有降低,说明 Deepseek 模型是对训练集的数据集有拟合的。
2.直观比较模型生成
模型微调完,生成的内容效果如何,怎么进行比较呢?
这个时候我们首先想到的是直接比较「微调模型」和「原始模型」对同一个问题生成的回答内容进行比较。
因此我们可以统一提示词,统一相关的问题,然后比较生成的答案。
具体代码如下:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import os
import json
from bert_score import score
from tqdm import tqdm
# 设置可见GPU设备(根据实际GPU情况调整)
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 指定仅使用GPU
# 路径配置 ------------------------------------------------------------------------
base_model_path = "xxxxx" # 原始预训练模型路径
peft_model_path = "xxxxx" # LoRA微调后保存的适配器路径
# 模型加载 ------------------------------------------------------------------------
# 初始化分词器(使用与训练时相同的tokenizer)
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
# 加载基础模型(半精度加载节省显存)
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path,
torch_dtype=torch.float16, # 使用float16精度
device_map="auto" # 自动分配设备(CPU/GPU)
)
# 加载LoRA适配器(在基础模型上加载微调参数)
lora_model = PeftModel.from_pretrained(
base_model,
peft_model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# 合并LoRA权重到基础模型(提升推理速度,但会失去再次训练的能力)
lora_model = lora_model.merge_and_unload()
lora_model.eval() # 设置为评估模式
# 生成函数 ------------------------------------------------------------------------
def generate_response(model, prompt):
"""统一的生成函数
参数:
model : 要使用的模型实例
prompt : 符合格式要求的输入文本
返回:
清洗后的回答文本
"""
# 输入编码(保持与训练时相同的处理方式)
inputs = tokenizer(
prompt,
return_tensors="pt", # 返回PyTorch张量
max_length=1024, # 最大输入长度(与训练时一致)
truncation=True, # 启用截断
padding="max_length" # 填充到最大长度(保证batch一致性)
).to(model.device) # 确保输入与模型在同一设备
# 文本生成(关闭梯度计算以节省内存)
with torch.no_grad():
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1024, # 生成内容的最大token数(控制回答长度)
temperature=0.7, # 温度参数(0.0-1.0,值越大随机性越强)
top_p=0.9, # 核采样参数(保留累积概率前90%的token)
repetition_penalty=1.1, # 重复惩罚系数(>1.0时抑制重复内容)
eos_token_id=tokenizer.eos_token_id, # 结束符ID
pad_token_id=tokenizer.pad_token_id, # 填充符ID
)
# 解码与清洗输出
full_text = tokenizer.decode(outputs[0], skip_special_tokens=True) # 跳过特殊token
answer = full_text.split("### 答案:n")[-1].strip() # 提取答案部分
return answer
# 对比测试函数 --------------------------------------------------------------------
def compare_models(question):
"""模型对比函数
参数:
question : 自然语言形式的医疗问题
"""
# 构建符合训练格式的prompt(注意与训练时格式完全一致)
prompt = f"诊断问题:{question}n详细分析:n### 答案:n"
# 双模型生成
base_answer = generate_response(base_model, prompt) # 原始模型
lora_answer = generate_response(lora_model, prompt) # 微调模型
# 终端彩色打印对比结果
print("n" + "="*50) # 分隔线
print(f"问题:{question}")
print("-"*50)
print(f"