本文为你介绍一套双层系统,能让你运行的每一个 AI 智能体都变得更聪明。20 分钟即可搭建完成,效果会逐日提升,且完全开源。
安德烈・卡帕西近期提到,他现在把大部分 Token 开销从代码转向了知识管理。
这篇帖子引发了广泛共鸣,因为它点出了所有人都能感受到的问题:你的 AI 智能体根本不了解你。每次对话都从零开始,你要反复解释你的业务、你的风格、你的目标、你的上下文,而输出内容千篇一律,因为输入没有记忆。
我借鉴了他的思路,在两周内测试了多种方案,最终精简出最有效的一种,并导入了我自己的数据:笔记、想法、推文、文章、书签。AI 智能体据此整理出230 多个结构化维基页面,对概念、实体和来源进行交叉关联,我可以随时查询。
本文会讲解什么是知识层,如何为内容创作、企业运营以及个人生活搭建专属知识层。这套框架开源,搭建仅需 20 分钟。
安德烈・卡帕西
@karpathy ・ 4 月 3 日 大语言模型知识库
我最近发现一个非常实用的方法:用大语言模型为各类研究方向搭建个人知识库。这样一来,我近期消耗的 Token 中,用于处理代码的比例大幅下降,更多被用于处理…… (展开更多)
AI 知识层是架设在你与 AI 智能体之间的基础架构。智能体在执行任何操作前,都会先读取这一层的信息。 没有它,智能体只能靠猜测;有了它,智能体才能真正 “了解” 你。
-
知识库层(KBL)—— 动态层
你把原始素材扔进一个文件夹:推文、文章、书签、PDF、笔记、语音备忘录。 AI 智能体读取所有内容,按类型分类,生成带交叉引用的结构化维基页面,并维护一份总索引,每条内容附带一句话摘要,方便快速浏览。 你提出的每一个问题,都会被归档为新页面。维基库会随时间不断丰富。
-
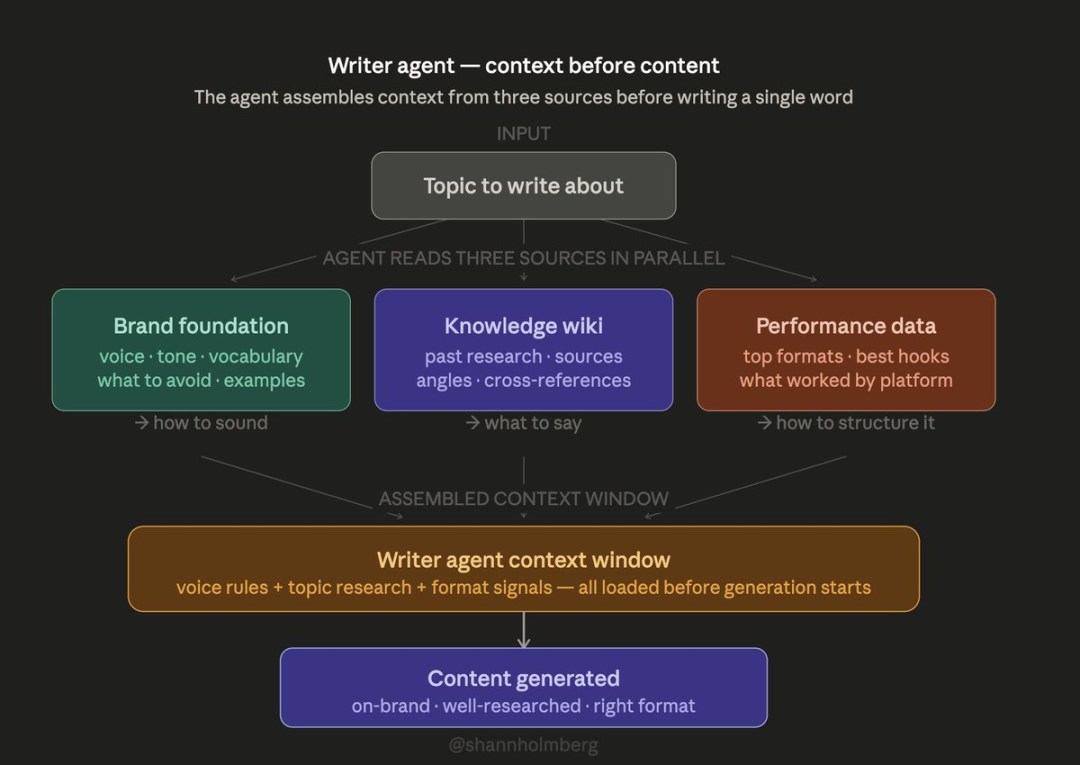
这一层仅由你手动编辑,包含你的语言风格、视觉调性、品牌定位、受众定义,以及你绝对不会使用的词汇。 智能体在生成内容前会读取这一层,但永远不会改写它。即便由 AI 代劳,这一层也能保证所有输出都带有你的个人风格。
+-------------------------------------------------------+| 你的AI智能体 || (文案、调研、策略、分析) |+---------------------------+---------------------------+ | 读取 | 读取 v v+------------------+ +-------------------+| 知识库层 | | 品牌基础层 || KNOWLEDGE BASE | | BRAND FOUNDATION || LAYER (KBL) | | (BF) || | | || 动态维护 | | 静态固定 || AI智能体维护 | | 人工编辑 || 持续迭代丰富 | | 你的风格、规则、定位 || 维基页、来源、索引| | |+--------+---------+ +-------------------+ | 整合自 |+--------+---------+| 原始素材箱 || 推文、文章、书签 || PDF、笔记、想法 |+-------------------+
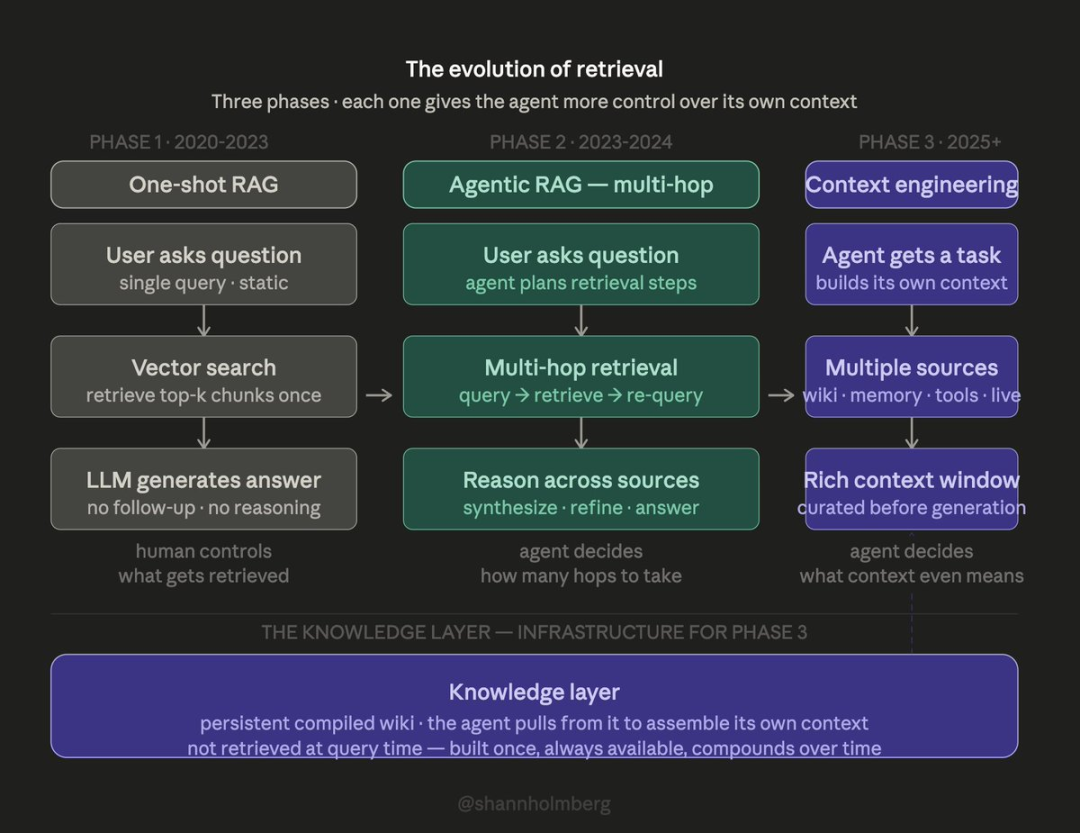
传统 RAG 是在查询时对文档分块、检索并实时推导答案。 而知识层一次性编译完成,自动交叉关联并保持更新。
卡帕西发现,当素材达到约 100 篇文章时,编译式方案的问答效果优于 RAG。 Graphify 测算,相比检索原始文件,该方案单次查询 Token 消耗减少 71.5 倍。
-
上下文工程:智能体从多源信息自主构建上下文(2025+)
原因和大多数人不在周日备餐一样:前期花 1 小时,能为一周省下 10 小时,但很少人愿意做。 多数人宁愿抱怨 AI 输出糟糕,也不愿花 20 分钟搭建一套能解决问题的系统。
90% 使用 AI 的人都在做同一件事:写提示词、接受结果、直接发布,毫无判断、毫无审美。 知识层能让你跳出这 90% 的人群。它把你的审美、数据、思维模式编码进去,让 AI 输出的内容像你亲手写的,而非千篇一律的 AI 垃圾。
但门槛确实存在:你需要筛选输入内容。与你工作相关度不足 80% 的内容,直接舍弃。高价值输入才有高质量输出,喂进去噪音,得到的只会是噪音。
这是我最初的应用场景。我运营着一个 AI 营销账号和一家代理机构,需要 AI 智能体了解我过往的作品、爆款规律和语言风格。
我搭建了一套名为LLM Wikid的框架并开源(后文会讲解部署方法)。导入个人数据后效果如下:
-
先把脑中所有想法写下来:项目笔记、半成品产品思路、行业观察、AI 营销趋势判断,无需刻意结构化
-
导入 6 周内的 87 条 X 平台推文存档、3 篇已发布文章和所有书签
-
AI 智能体处理后生成:15 个主题来源页、14 个概念页、11 个实体页,内含 100 + 条交叉链接
-
再通过 X API 导入 197 个书签,AI 下载 81 张图片、转录 49 条视频,分析视觉内容并整合进维基库
我的笔记、想法、推文、书签、文章全部关联、可检索。
知识库层(KBL):存放所有动态增长的内容,按类型分类(转录稿、文章、推文、论文),维基链接交叉引用,附带精简摘要索引
写作时输入/wiki-query,即可从个人数据中获得带引用的答案,答案会自动归档为新页面,让后续查询更丰富
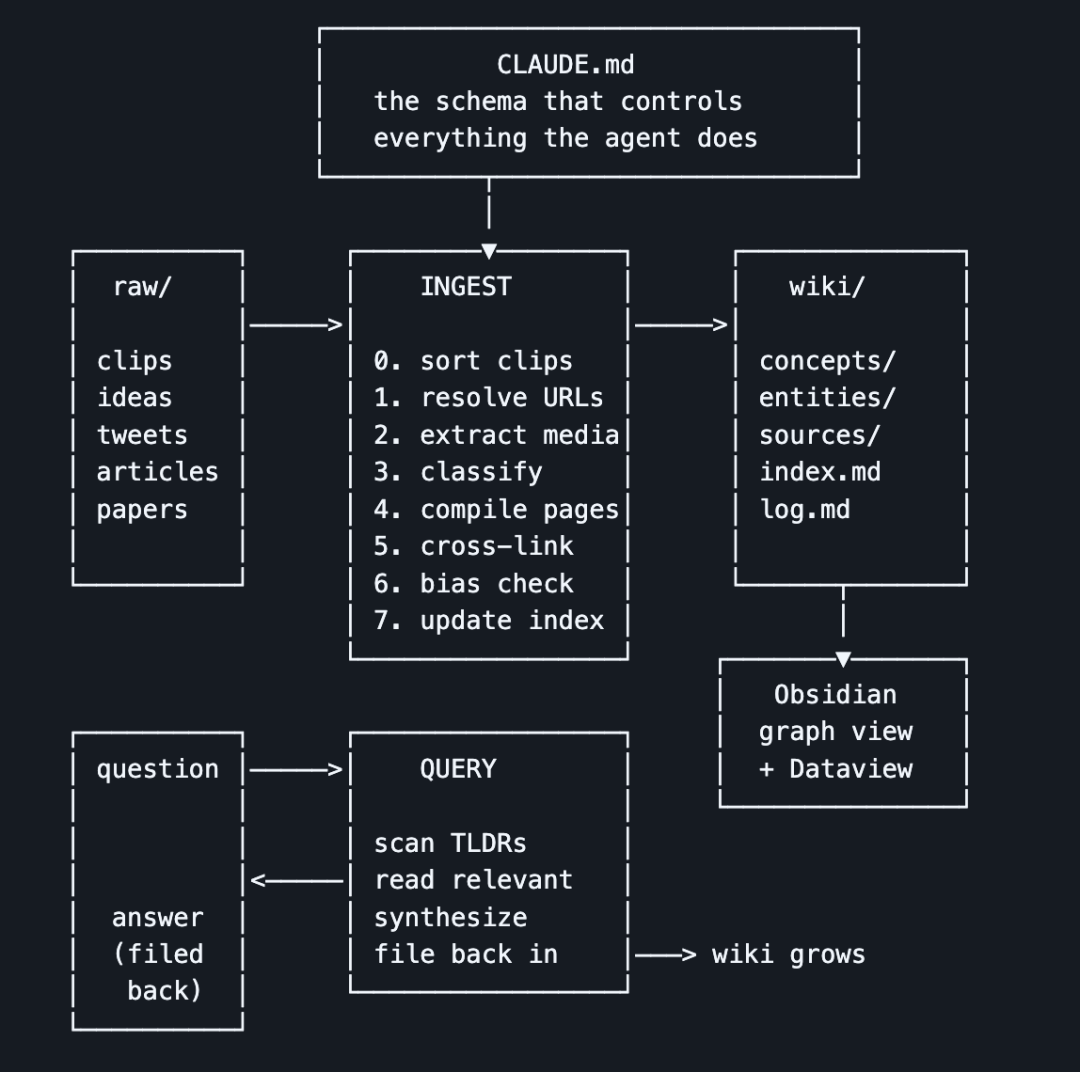
my-wiki/ raw/ # 原始素材箱 clippings/ # Obsidian网页剪藏 ideas/ # 想法、头脑风暴 bookmarks/ # 收藏的推文、工具 articles/ # 个人原创文章 papers/ # 研究论文、PDF x-archive/ # X平台导出内容 assets/images/ # 媒体素材 wiki/ index.md # 总索引 concepts/ # 概念、框架 entities/ # 人物、公司、工具 sources/ # 原始素材摘要 outputs/ # 查询答案归档 templates/ # 页面模板 CLAUDE.md # 总规则schema
日常浏览时一键剪藏,夜间执行/wiki-ingest自动处理,醒来就能获得更丰富的知识库。
品牌基础层(BF):固定不变的规则,包括 AI 禁用词清单、视觉风格指南、语言风格档案。所有 AI 智能体生成内容前都会先读取。
-
文案智能体:读取风格规范,查询维基库做选题研究,结合数据选择合适格式
-
调研智能体:监测社交平台新信息,导入原始素材,扩充维基库
-
策略智能体:交叉对比行业爆款与现有内容,找出空白赛道
知识层越丰富,智能体输出越优质。 同样的智能体,单薄知识库只能产出垃圾;读取 200 + 结构化页面后,输出完全贴合你的风格与数据。
这与我此前提出的 AI 营销 5 个层级完全契合:
-
-
-
-
-
多数人停留在 1、2 级,知识层能让你直接迈入 4、5 级。
低代码让开发变得简单,人人都能 48 小时做出产品,但分发依然困难。 知识层能让分发能力持续复利:每一条内容洞察、每一份书签分析、每一项数据追踪,都会让下一篇内容定位更精准。
设置定时任务,每日自动处理前一天剪藏的内容,分发能力在夜间持续进化。
同时可提供商业服务:为他人搭建知识层,收费1500–3000 美元,月服务费300–500 美元。 10 位客户首年收入可达 5.68 万美元,对创作者或机构而言是可产品化的核心技能。
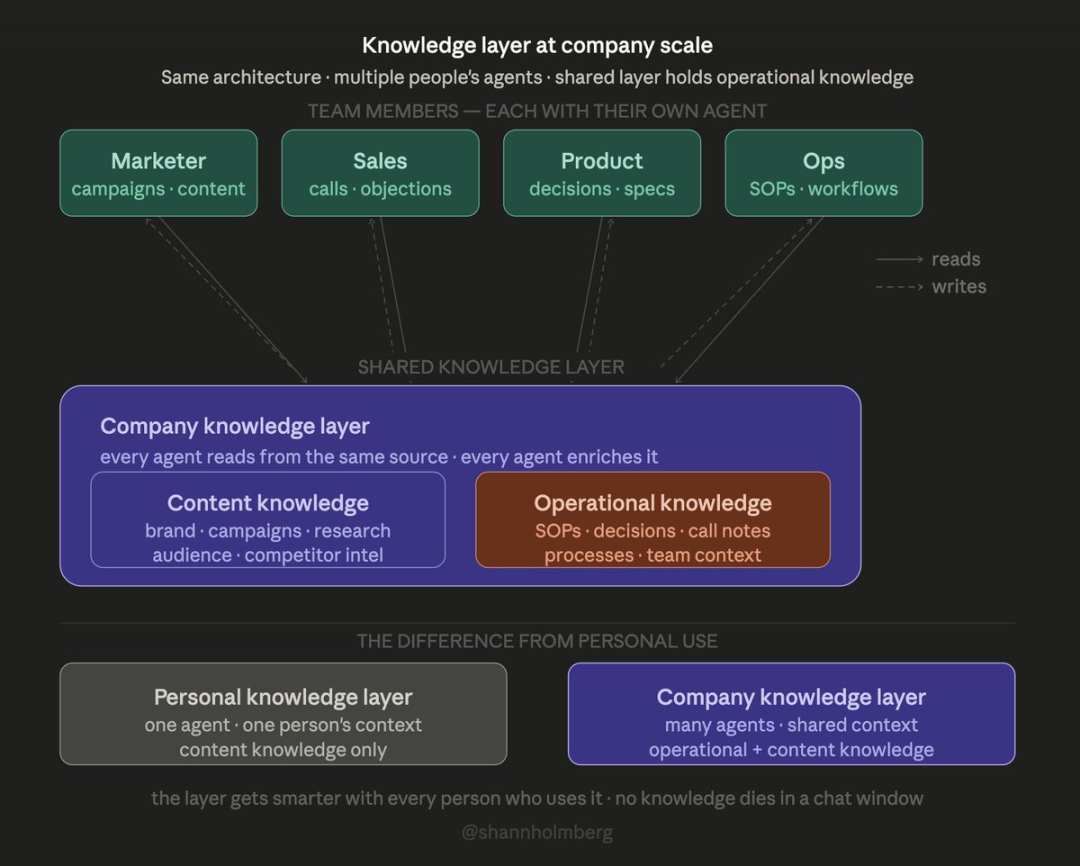
这套架构同样适用于企业级场景。 区别在于:多人智能体共用同一知识层,层内不仅包含内容知识,更有运营知识。
我在 @EspressioAI 和 @LunarStrategy 均落地使用:
-
Espressio:存放客户交付模式、智能体架构模板、内部标准流程
-
Lunar Strategy:存放营销方案、客户调研、内容框架
新员工的智能体接入知识库后,入职即具备生产力,无需花费数周摸索无文档的工作方式。
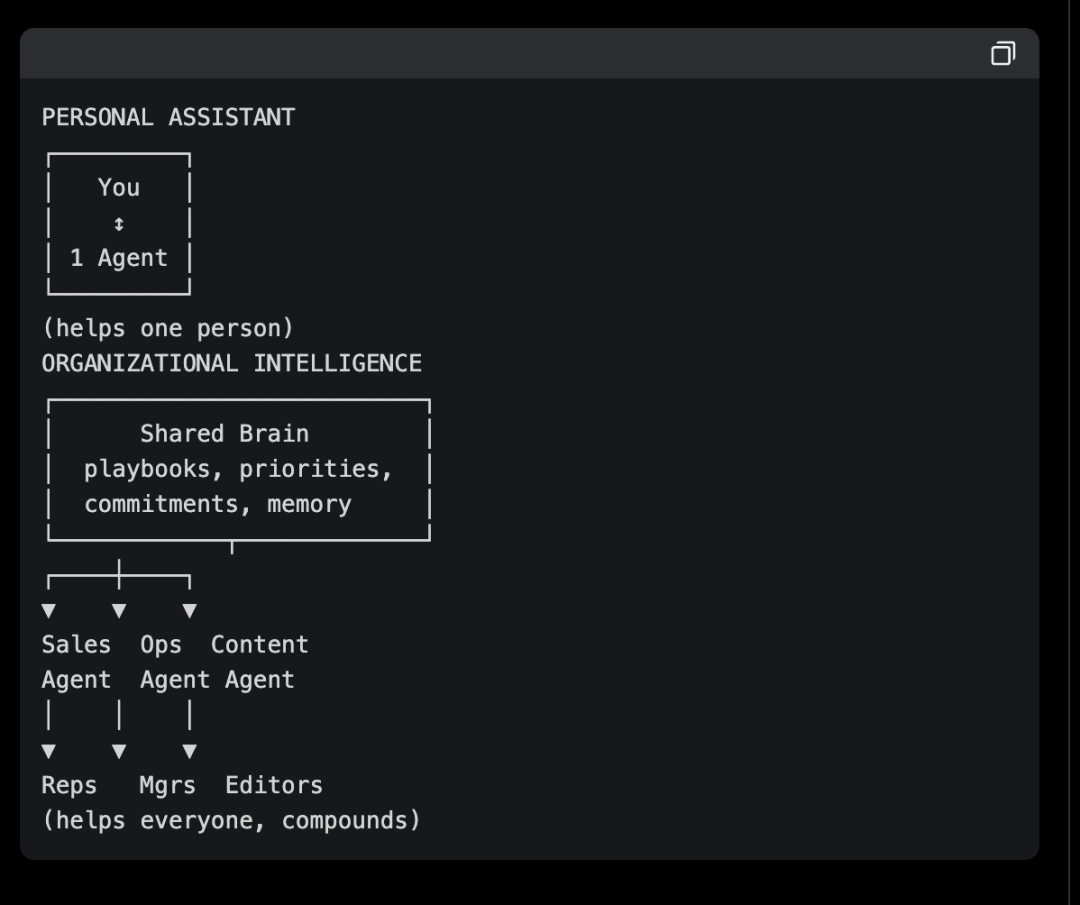
埃里克・奥修在全公司推行类似系统:每位员工配备适配岗位的 AI 智能体,共享中央大脑。 他的总结:
“私人助理有上限,真正的突破是岗位定制智能体通过中央大脑共享上下文。”
销售成交后,客户运营智能体自动获取交接信息;内容爆款后,销售智能体自动调整触达策略。
个人维基 → 小团队共享知识库(5–10 人)→ 企业级岗位智能体(50 + 人) 模式完全一致:
-
-
-
-
-
科迪・施耐德为本地服务商搭建了具备 10 项能力的营销智能体集群,核心正是承载全部业务数据的数据仓库。 他称之为数据仓库,埃里克称之为共享大脑,卡帕西称之为大模型维基。 名字不重要,关键是:智能体需要编译后的结构化知识,才能完成有价值的工作。
极致形态是格雷格・艾森伯格所说的“环境型企业”:主要由 AI 智能体运营,创始人只需数日检查一次。 Medvi 就是例证:年收入 18 亿美元,仅 2 名员工,无风险投资。AI 负责代码、创意、风格、客服,而知识层是前提。没有它,智能体需要持续人工指令;有了它,智能体依托组织知识自主运行。
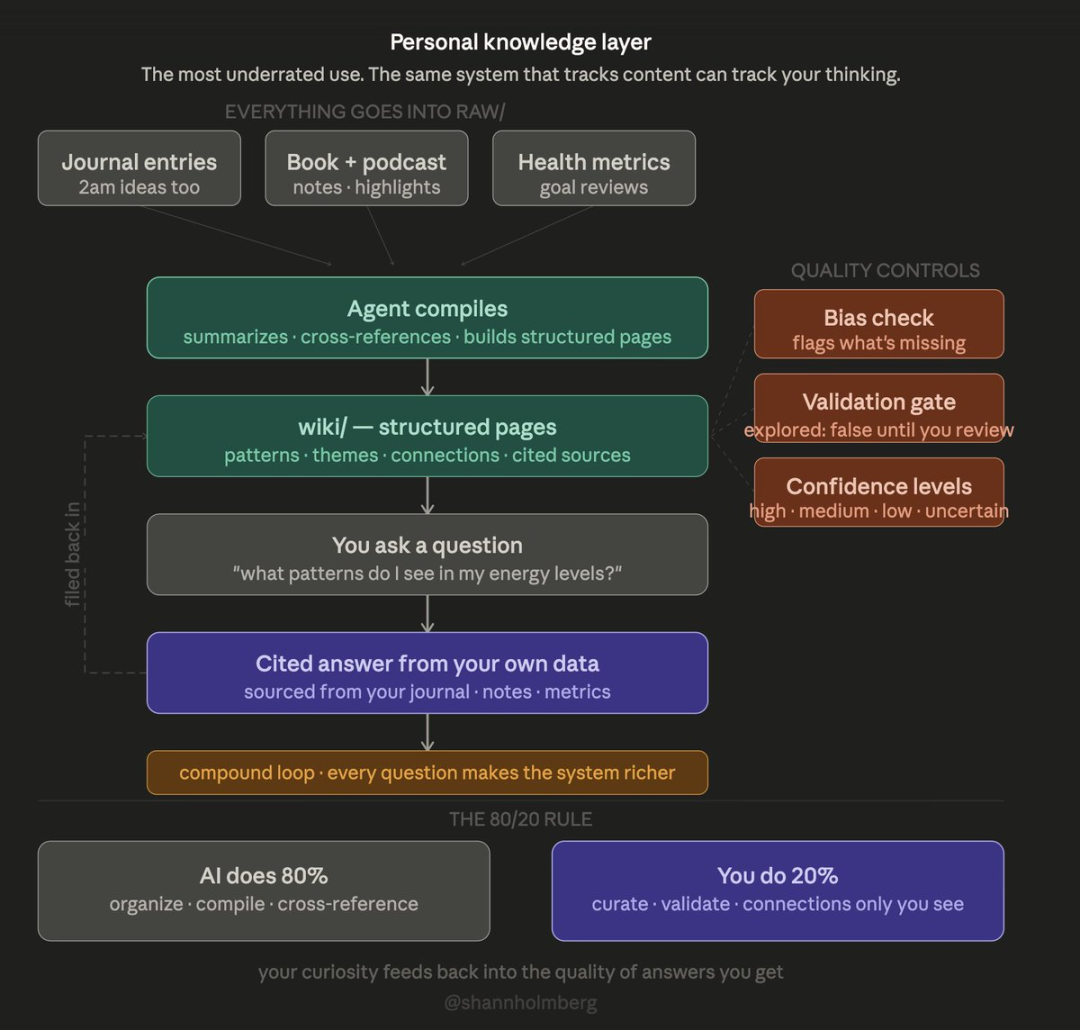
这是最被低估的用途。 这套系统既能追踪内容数据,也能追踪你的思考: 日记、读书笔记、播客精华、健康数据、目标复盘、凌晨突发灵感…… 全部导入原始文件夹,AI 整理为结构化页面。
会得到基于个人数据的带引用答案,答案自动归档,让下一次提问更智能。
复利循环:每一次提问都让系统更丰富,每一份素材都建立新关联,你的好奇心直接提升答案质量。
这里的质量控制尤为重要,盲目信任 AI 风险极高:
-
审核机制:AI 生成页面默认未审核,仅人工可标记确认
-
置信度标签:高 / 中 / 低 / 不确定,AI 如实标注知识可靠性
-
遵循 80/20 原则:让 AI 完成 80% 的整理、编译、关联工作,你把控最后 20% 的筛选、审核、独有洞察。知识层会持续优化这 80% 的质量。
git clone https://github.com/shannhk/llm-wikid.git my-wikicd my-wiki用 Obsidian 打开该文件夹作为库。
在文件夹中打开 Claude Code(或支持 Markdown 与 bash 的智能体),它会读取总规则文件CLAUDE.md,自动理解架构并搭建维基结构。
安装 Obsidian 网页剪藏,收藏优质推文、文章
/wiki-ingestAI 自动分类、抓取全文、下载分析图片、生成交叉引用页面、标注对立观点与数据缺口、更新总索引。查询示例:/wiki-query 哪种内容格式收藏量最高?AI 会检索索引与相关页面,给出带引用的结论,并自动归档为新页面。
在 Obsidian 中打开图谱,你的想法、关注人物、使用工具、核心概念会形成可视化关联网络,开始用/wiki-query探索。
后续可执行:
-
查看近月收藏最多的主题
-
查找核心观点的对立论据
-
汇总对某一竞品 / 工具 / 话题的全部认知
-
定位知识薄弱的概念
-
设置定时任务,每日自动执行/wiki-ingest
-
每 1–2 周运行/wiki-lint,检查矛盾、过期内容、孤立页面、重复概念
-
页面超 300 后,安装 qmd 实现本地混合检索
-
接入更多智能体:文案、调研、策略,知识层作为共享大脑
卡帕西的帖子收获 9.9 万 + 收藏,Graphify 48 小时上线再获 2.7 万 + 收藏,同期多款实现方案爆红,需求显而易见。
大多数人会收藏、赞叹,却从不动手搭建。 今天花 20 分钟行动的人,下月就会拥有无法被搜索引擎和通用提示词复制的复利知识库,它懂你的风格、数据、模式与审美。