你是否曾为堆积如山的PDF文件头疼不已?合同、报告、论文……内容繁杂,查找关键信息就像大海捞针。现在,这一切即将被彻底改变!在信息爆炸的时代,海量数据散落在各大网站、论坛、文档中,手动收集整理不仅耗时耗力,还容易遗漏关键信息。今天,我们将带你探索如何利用 dify 平台,结合RAG技术,实现自动化采集网页内容并高效入库,打造一个真正智能、可检索、可扩展的 AI 知识库系统。
1.准备工作
-
本地部署Dify
-
创建一个空的知识库
-
获取硅基流动的API_KEY
-
安装Dify的硅基流动API插件
-
Dify配置文件修改
-
获取MinerU的API_KEY
-
安装Dify的MinerU插件
2. 新内容标注
准备工作中的前四条在以往文章中均已涉及,这里不再赘述,不清楚的小伙伴可以查看往期的公众号文章,仅对后三条操作进行详细描述。
-
Dify配置文件.env修改,先在Dify得docker目录下执行docker compose down移除容器,然后重新执docker compose up -d构建容器。
需要修改Dify的文件服务的配置,修改内容如下:

-
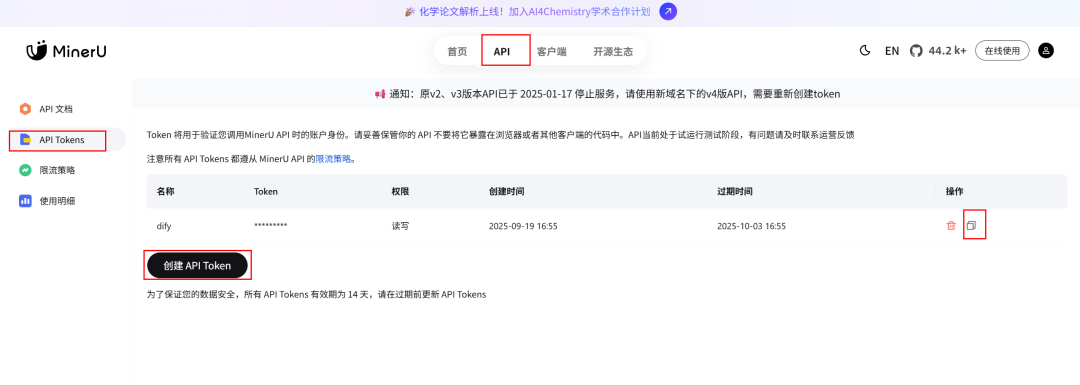
获取MinerU的API_KEY
浏览器访问https://mineru.net,第一次使用需要注册MinerU账号,可以使用github账号或者微信注册,还需要申请MinerU官方的API接口调用(个人申请就行,基本都是秒通过的),注册成功后创建并复制API_KEY备用(如果是本地自建的MinerU可以跳过此步骤,后续也会本地部署尝试)。
-
安装Dify的MinerU插件
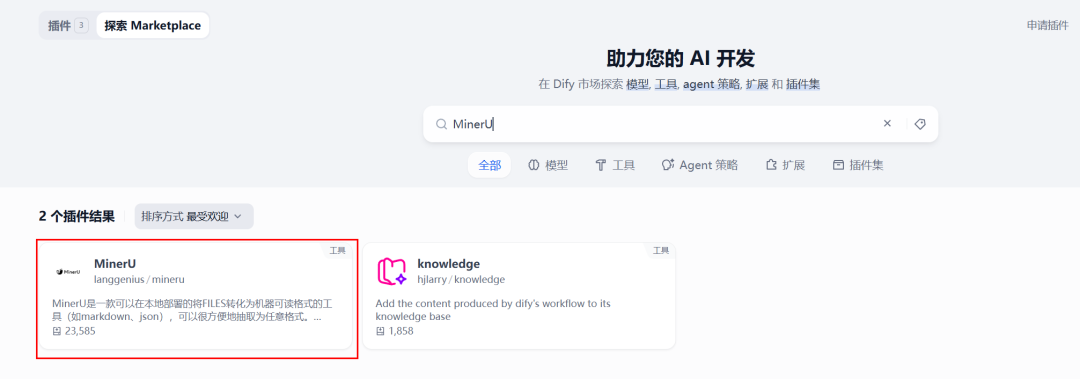
在Dify的插件市场搜索MinerU,安装第一个Dify官方的插件,安装完成后配置MinerU的BaseURL、API_KEY和服务类型,服务类型支持官方API调用和本地自建服务,这里以官方API调用为例。
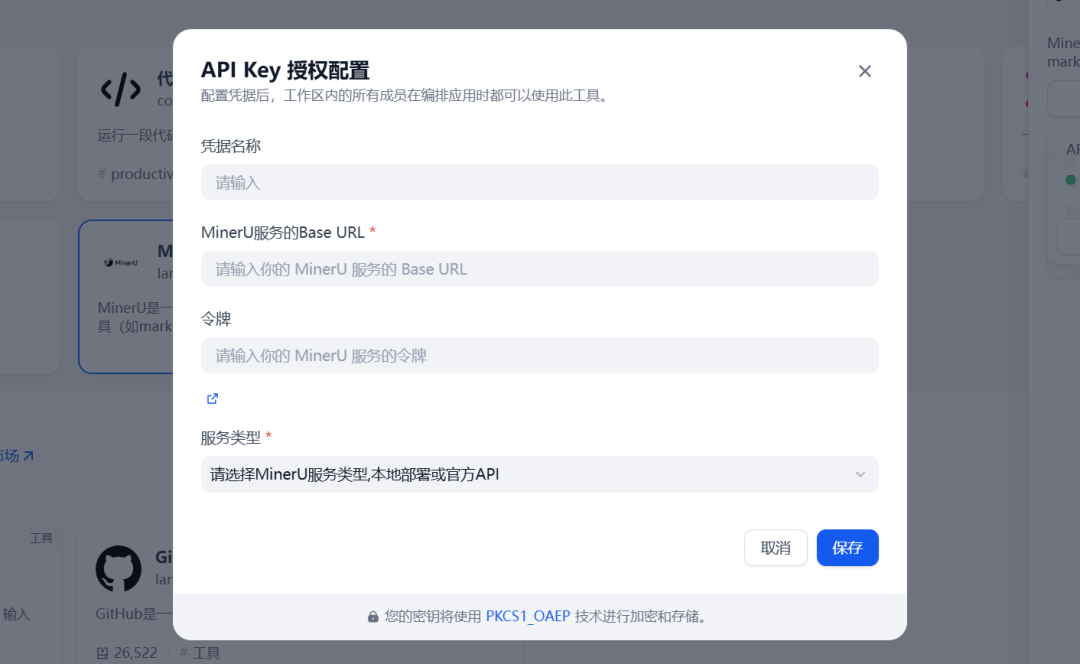
通过 MinerU 官方 API,您可以将复杂的 PDF 文档智能解析为结构化文本内容。只需配置 BaseURL 为 https://mineru.net 并使用官方提供的 API_KEY,即可调用其强大的文档理解能力,精准提取文字、表格、标题层级等关键信息,无缝对接 Dify 等应用,实现自动入库与知识管理,让非结构化数据轻松转化为可用的业务资产。
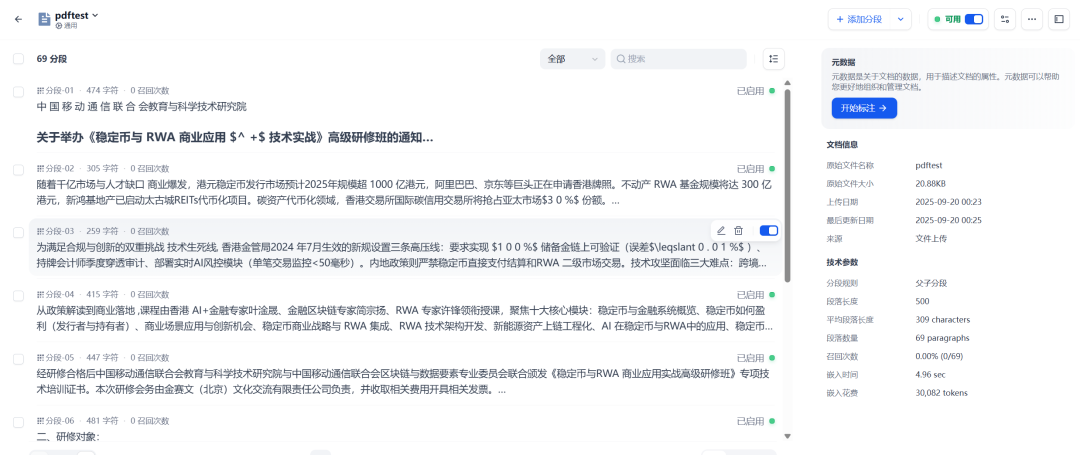
3.创建一个空知识库
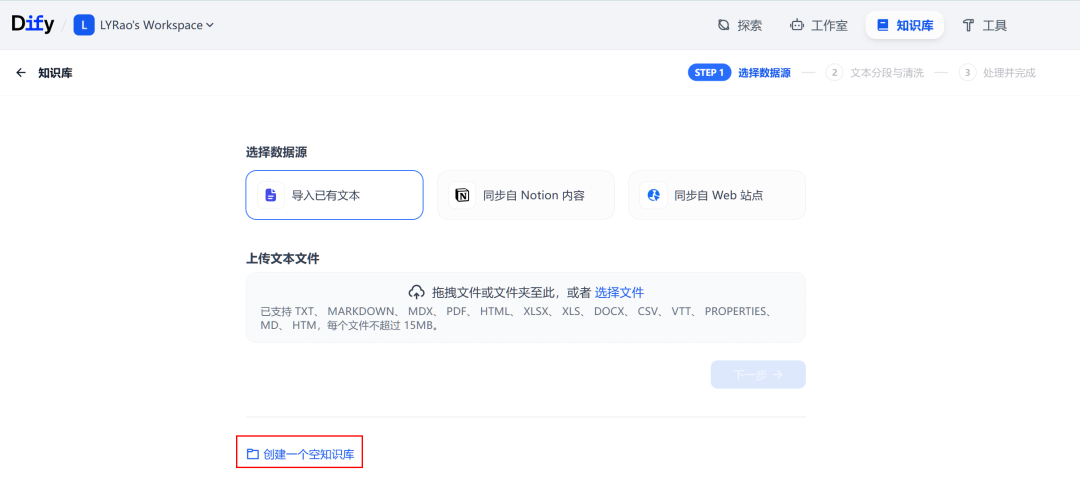
创建一个空知识库,获取知识库的ID和知识库的API_KEY。
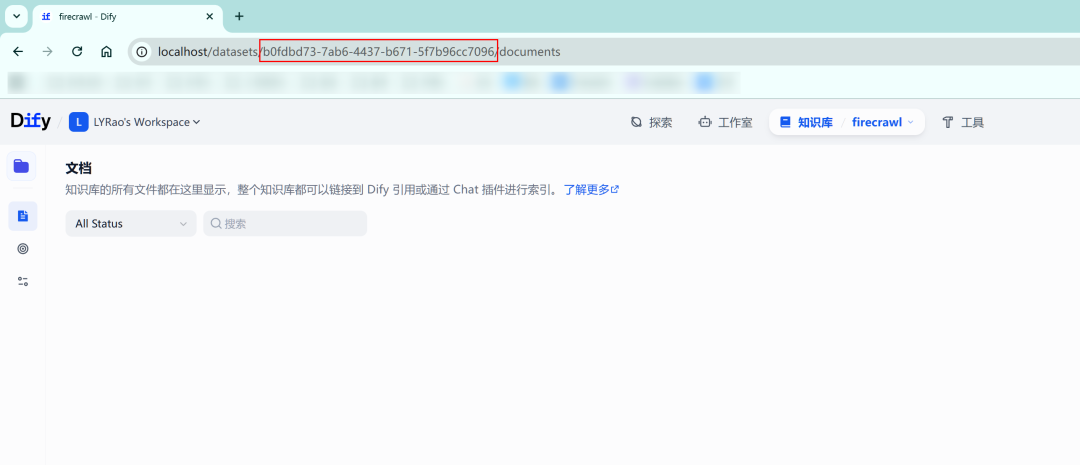
知识库id的获取方式:
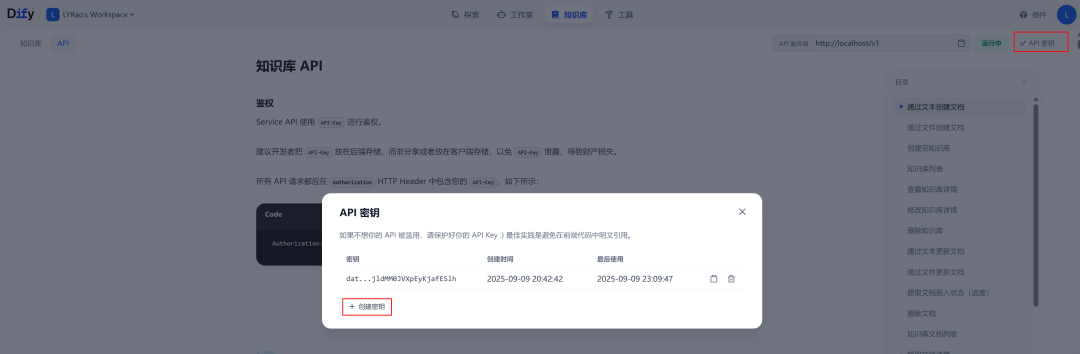
知识库API_KEY的获取方式:
3. 工作流展示
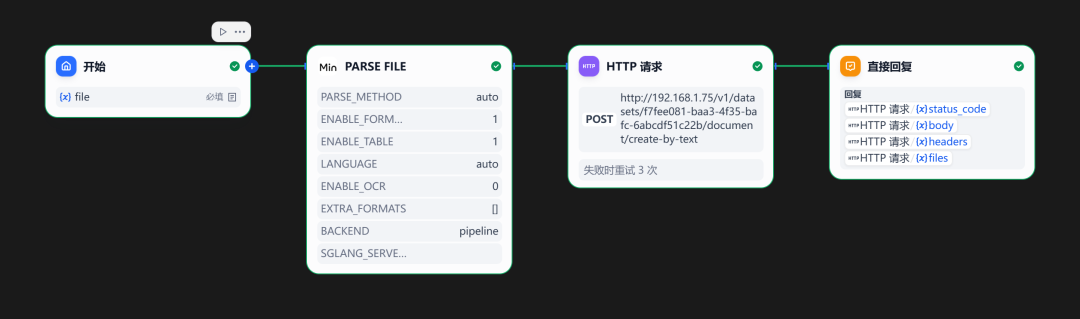
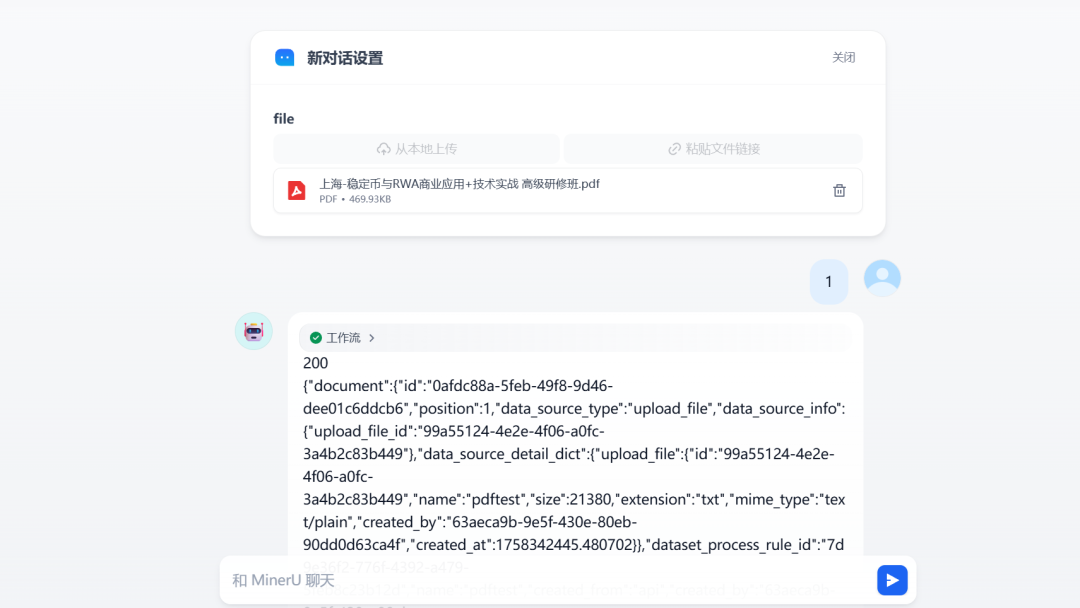
工作流的主要功能是提取PDF的内容自动化通过调用Dify知识库的API将内存保存到知识库中。
4. 效果展示