搭建AI知识库,其实并不复杂。大多数平台(如腾讯IMA、dify、ChatDOC等)搭建流程都大同小异。
只要你明白下面这套“通用闭环模型”,几乎可以在任何平台上举一反三,快速上手。
📌 什么是“通用闭环模型”?
知识库不是一次性工程,而是一个完整的循环体系。大致包含以下 6 个步骤:
收集 → 清洗 → 导入 → 构建 → 使用 → 反馈优化
下面我们一步步说清楚。

01
—
资料收集
💡 要干嘛?
把你已有的知识内容统一收集到一个地方,准备导入。
📁 常见资料来源:
-
PDF:产品说明书、学术文献、行业报告
-
Word / Excel:项目方案、制度文档
-
微信公众号:个人历史文章、企业推文
-
笔记、博客、网页链接、在线文档
🎯 建议做法:
-
建立一个“知识收集文件夹”
-
所有文件统一命名格式(如【分类】+标题)
-
把临时浏览记录/公众号文章一并收集。
02
—
资料清洗
💡 要干嘛?
让你的资料“适合AI吃”,去掉噪声、结构混乱的信息。
📦 清洗内容:
-
删除封面页、广告页、水印页
-
清理乱码、语义不通的段落
-
拆分为小段落(有的平台自动做这一步)
🛠️ 工具推荐:
-
Adobe Acrobat:PDF删除页面/拆分页面
-
小丸工具箱 / pandoc:格式转化
-
手动复制粘贴也能搞定,小文件无需上工具
03
—
导入资料
💡 要干嘛?
将清洗好的内容上传到平台中,准备建立索引。
🌐 不同平台导入方式:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🚨 注意:
-
支持格式不同(PDF、DOC、TXT)
-
上传大小限制不同(IMA单文件100MB以内)
04
—
文本切分并向量化,构建知识库完成
💡 要干嘛?
让平台把资料转成“AI能理解的格式”,一般是向量索引或结构化字段。
🧠 背后发生了什么?
-
平台会把文本进行“切分”,一段一段保存;
-
每段文字生成一个向量,作为AI的“记忆点”;
-
索引建好后,AI才能“检索+理解+回答”。
📌 特别提示:
-
一些平台允许你选择“切分粒度”(段落/句子级);
-
切得越碎,召回准确性越高,但也容易断句失意;
-
切得越整,语义更连贯,但可能找不到具体答案。
05
—
开始提问 & 优化使用
💡 要干嘛?
开始“用起来”!验证知识库是否好用、是否精准。
✍️ 提问方式举例:
-
“2025年我们续签合同的流程有哪些?”
-
“公司销售话术里有没有提到退款政策?”
-
“产品A与产品B的区别有哪些?”
🎯 优化建议:
-
检查AI回答是否引用了文档原话;
-
如果答非所问,考虑重新切分 or 增加“锚点”关键词;
-
用“多个问法”测试同一个问题,观察不同表现;
06
—
不断反馈,持续更新
💡 要干嘛?
知识库不能一劳永逸,要有更新机制,才能真正活起来。
📦 自动化建议:
-
设置自动导入目录(如:watch某个本地文件夹)
-
用爬虫或公众号采集工具定期抓取内容
-
建立一个“内容更新提醒流程”,定期提醒上传新文档
07
—
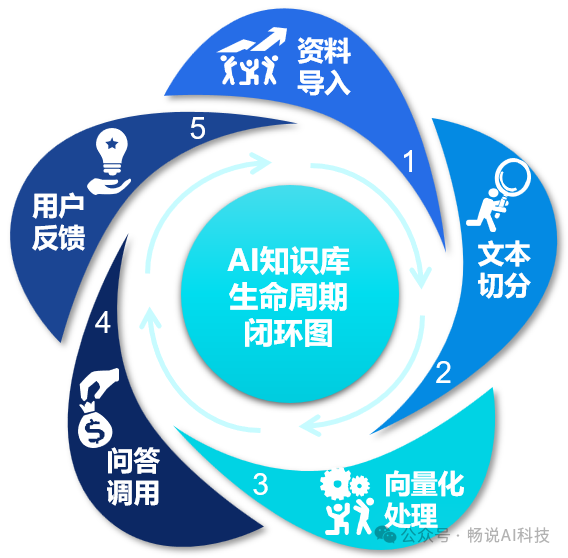
浓缩成五步闭环图
💡 根据上面的通用6步法就可以搭建一个实用的知识库,不过我们对其进行浓缩、归纳后,形成了下面的五步闭环图,更加简捷、明了。