
之前在写ragflow爬虫组件的时候,我就想想通过爬虫组件采集信息,打造个人的私人知识库。我翻了下ragflow的源码,发现api必须上传文档,不能直接上传文本,周日在家想起这件事,我想看看dify的能否实现。
然后我看了知识库有对应的接口,就开始尝试了下,然后入坑了。调了80多次才调好。
以前写代码不正确先自我怀疑,用dify和ragflow一定不能有这种思维,一定要想这是bug。
准备工作
创建空白知识库
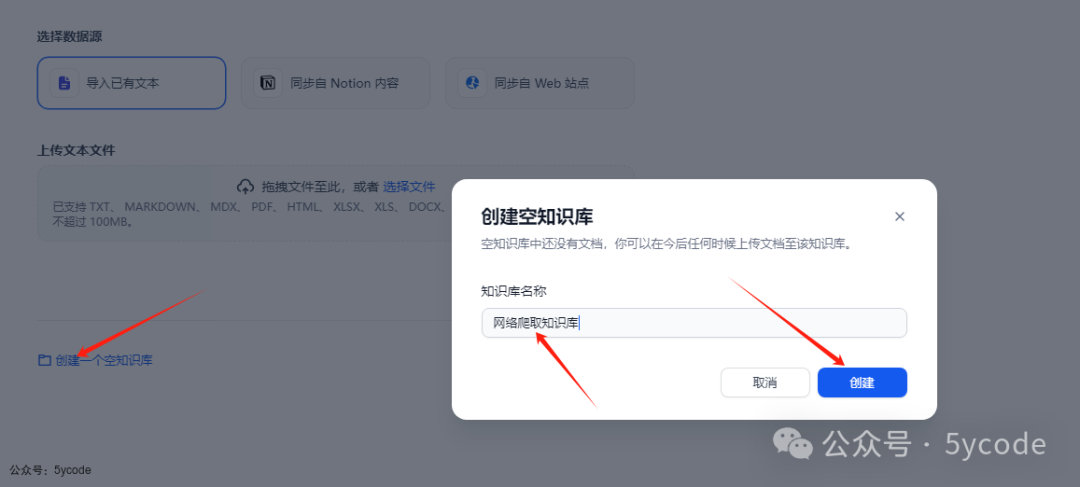
获取数据库的datasetid
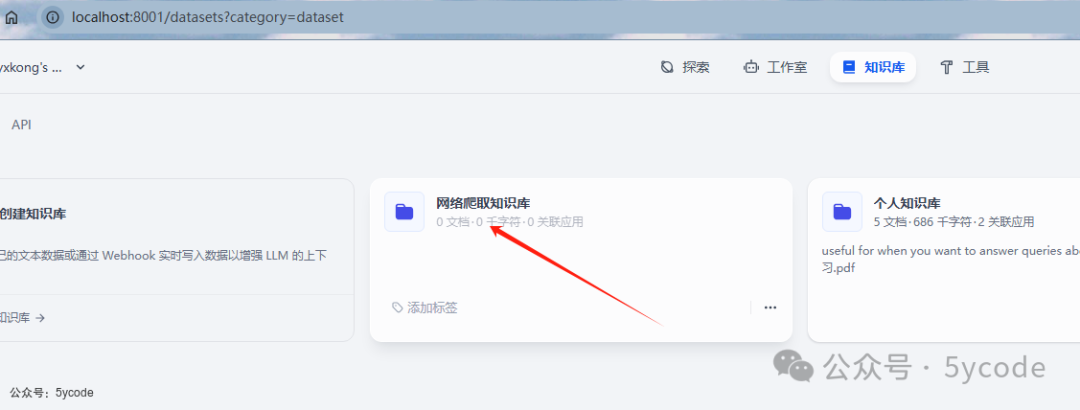
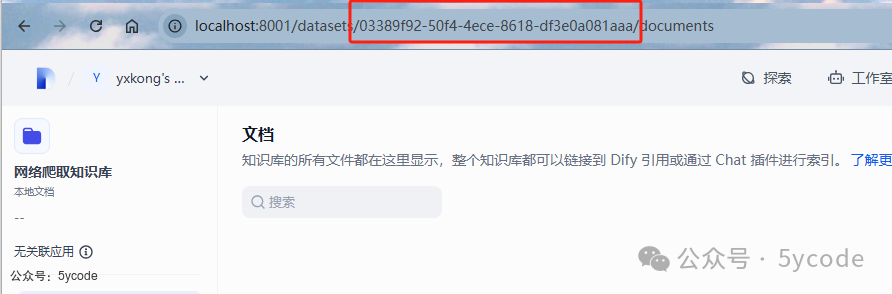
拿到知识库的Id 03389f92-50f4-4ece-8618-df3e0a081aaa
申请密钥
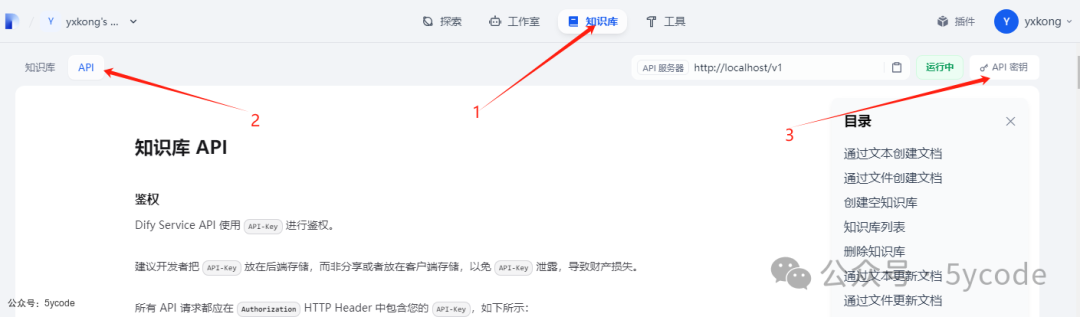
在知识库里申请秘钥,
-
通过 1点击知识库, -
点击 2API,这个位置也是api的文档 -
点击 3API密钥
在知识库里申请密钥,这个密钥要好好的保存,是操作所有知识库的,不是某一个。
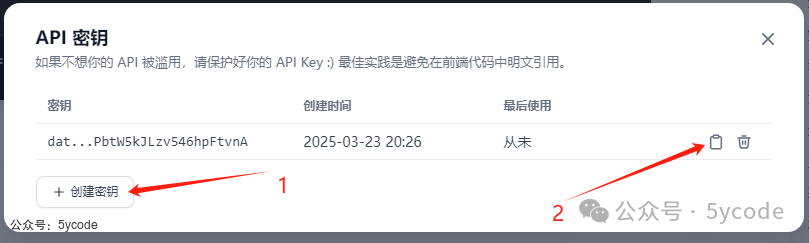
创建密钥或者直接通过2复制已有的密钥。
比如我的密钥:dataset-H8YPPbtW5kJLzv546hpFtvnA
postman验证(可选)
建议先用postman验证好。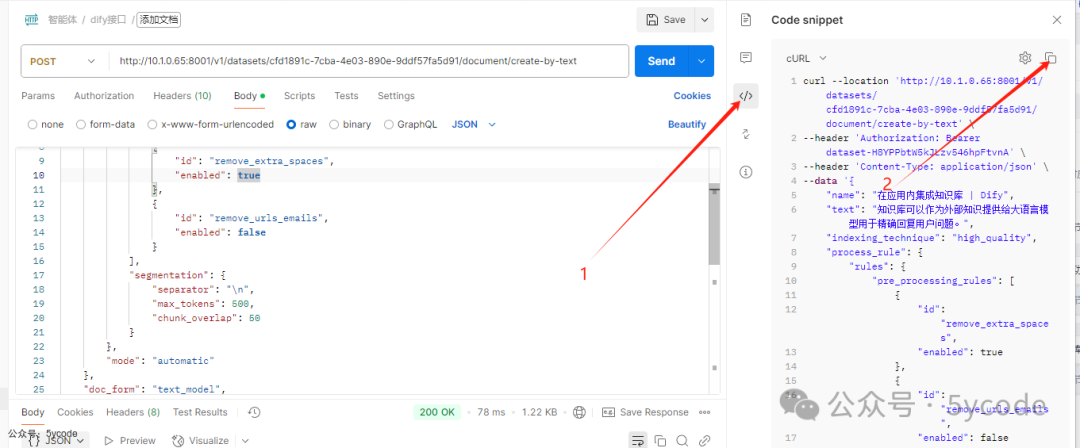 验证成功以后,我们点击位置
验证成功以后,我们点击位置1的图标,点击位置2把curl命令复制下来。
获取接口
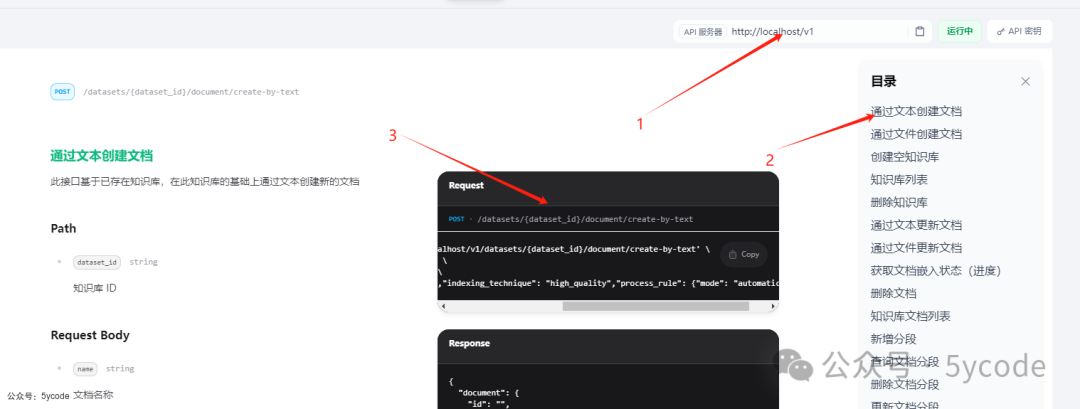 在知识库的api文档里,第一个接口就是我们这次要用的接口。
在知识库的api文档里,第一个接口就是我们这次要用的接口。
整体流程
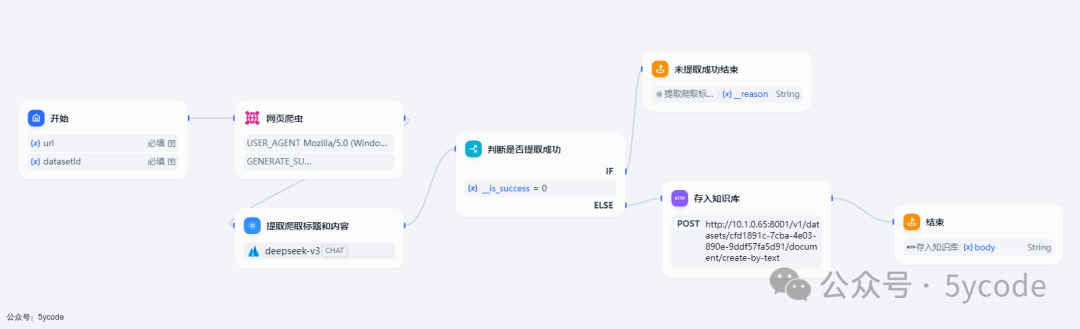 最终流程如图。
最终流程如图。
我本来是想通过采集以后,自定义父子分段实现的,但是这个入坑了。
详细步骤拆解
我们要实现采集并入库
-
1要知道爬取的url,url可以手工输入,也可以搜索以后提取 -
2采集完以后如何分段存入知识库
开始节点设置
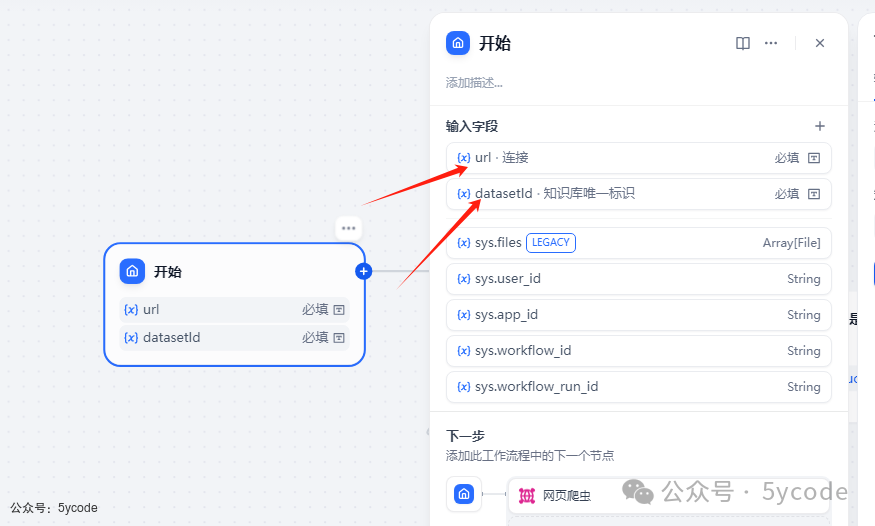 添加两个变量
添加两个变量
-
url 输入链接 -
datesetId 我们前面获取的知识库的id
网页爬虫
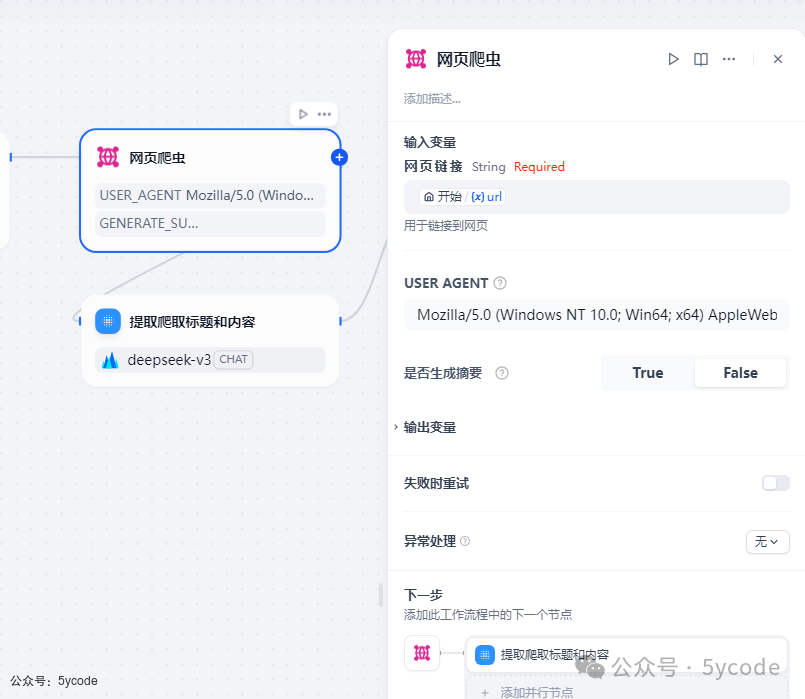 网页爬虫是dify的一个工具,需要在市场里下载安装。直接引用输入的url即可。
网页爬虫是dify的一个工具,需要在市场里下载安装。直接引用输入的url即可。
微信公众号爬取是乱码,这个大家不用试了
提取爬取标题和内容
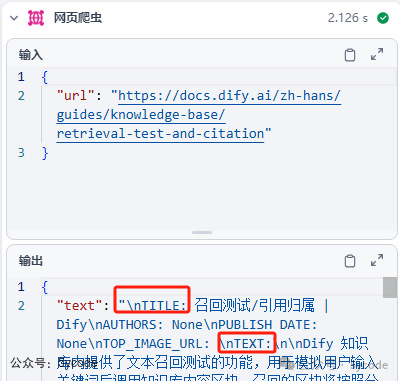
爬虫组件获取数据接口如上,我们主要是要把text中的内容提取出来。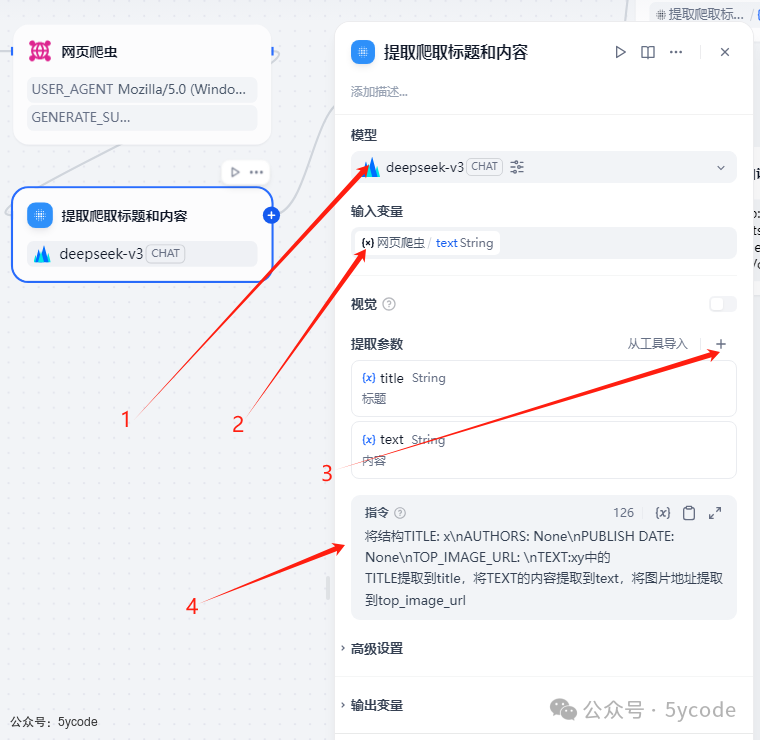
-
添加一个参数提取器 -
在 1的位置设置模型,用v3或者其他的模型就行,别用r1 -
输入变量为爬取的结果 -
通过 3添加提取参数 -
通过 4添加提取指令
添加判断组件
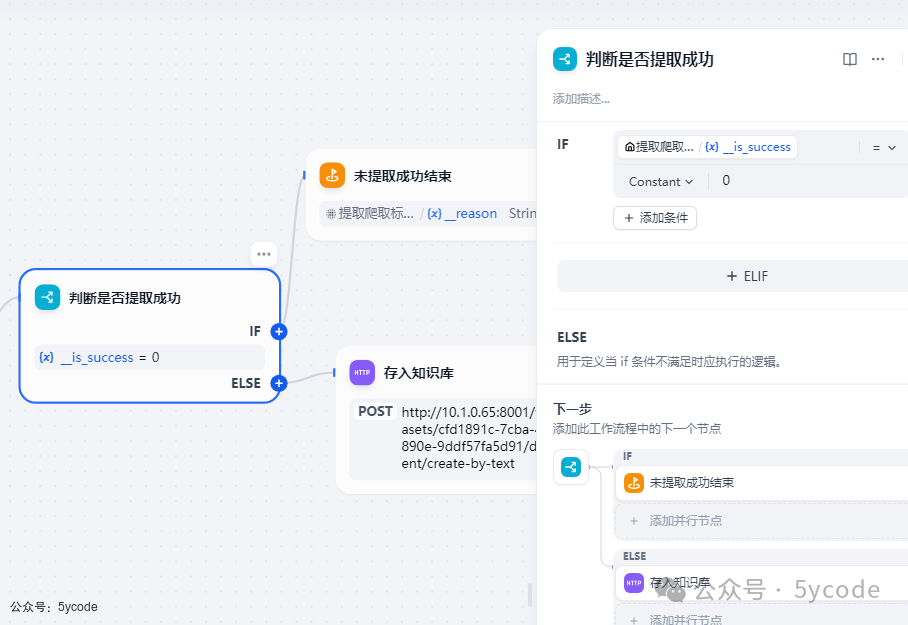 爬取成功,我们就存入知识库,否则则直接结束。
爬取成功,我们就存入知识库,否则则直接结束。
存入知识库
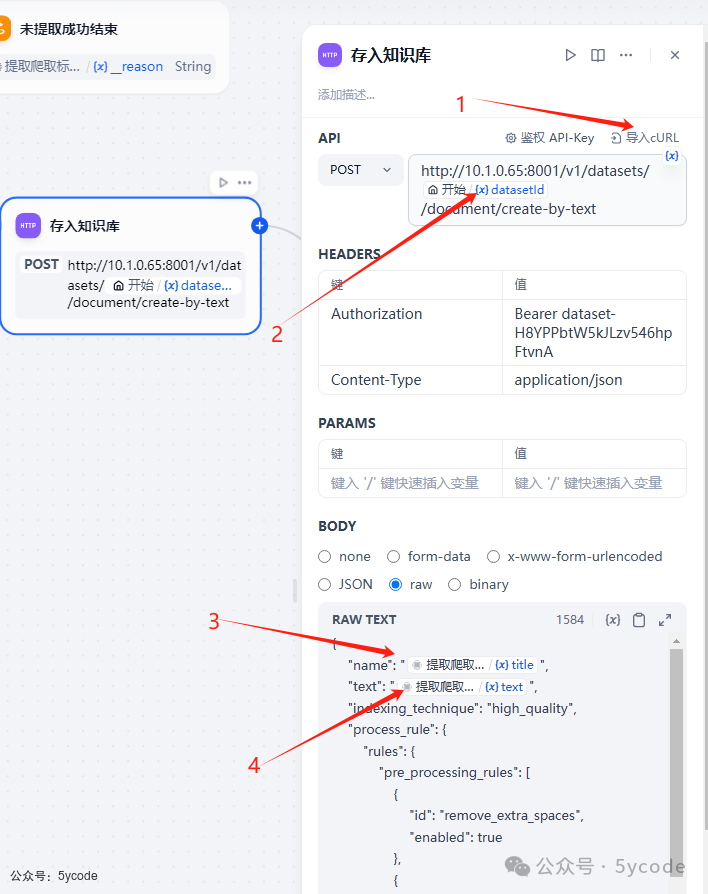
-
通过位置 1把在postman 验证通过的curl命令复制过来。这里需要注意下,接口请求方式是POST,自动填充的是GET -
在 2的位置,把知识库id,改成变量 -
在 3和4的位置,把提取到的标题和内容设置进去
结束
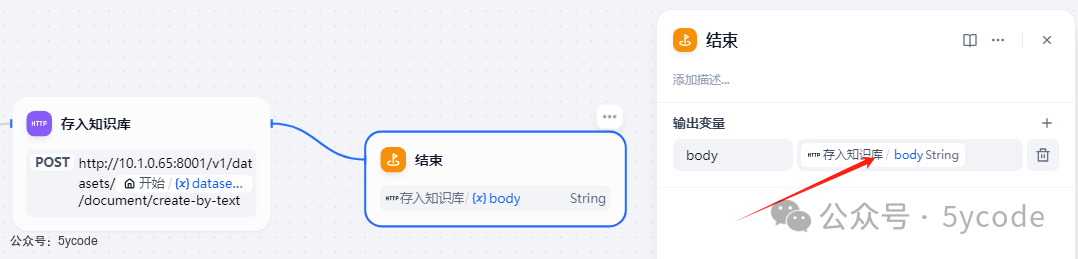 把请求结果输出。
把请求结果输出。
验证
我们拿dify官方文档的链接试一下
https://docs.dify.ai/zh-hans/guides/knowledge-base/retrieval-test-and-citation
-
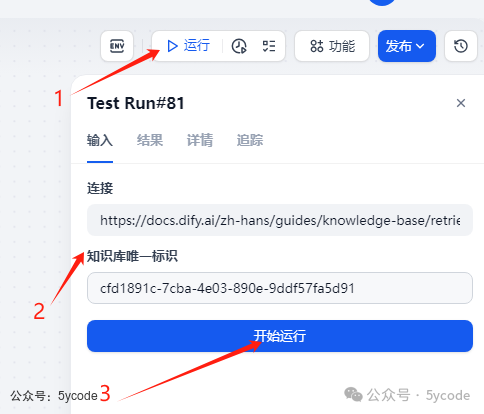
点击右上角的 1运行, -
填入链接和知识库的标识 -
点击 3运行 追踪查看是否成功。
追踪查看是否成功。
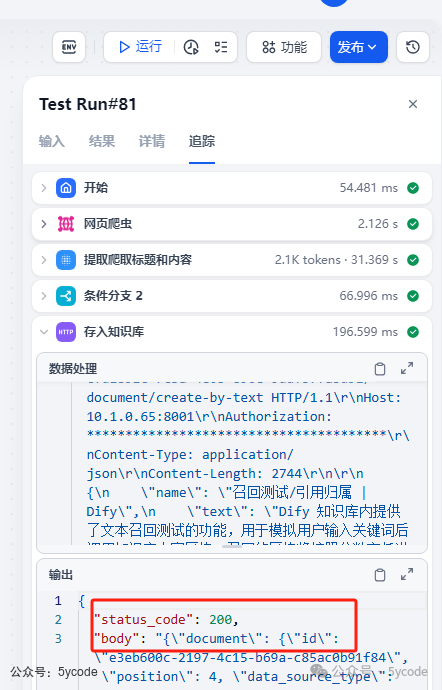 追踪查看是否成功。
追踪查看是否成功。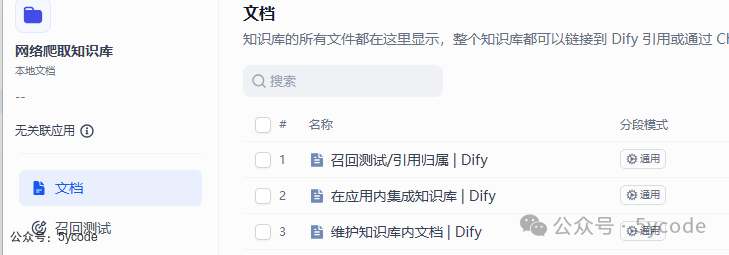 在知识库中我们可以看到存进去的文档。
在知识库中我们可以看到存进去的文档。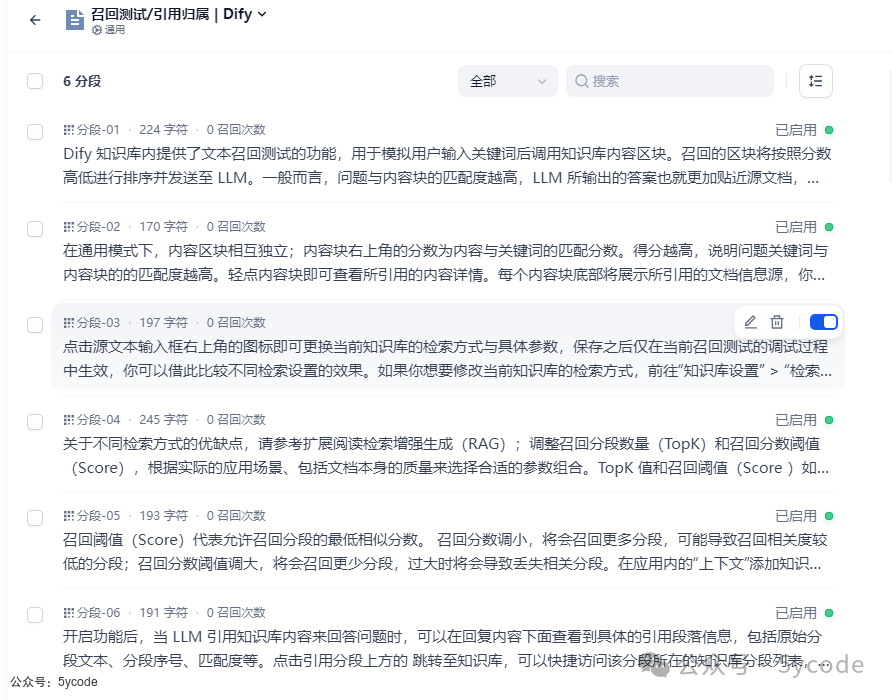 点开可以查看分段结果。
点开可以查看分段结果。
后记
看着很简单是吧,我被折磨快2天。这里需要注意一点,用本机的ip请求,如果一台机器上,可以用docker内网。
坑一
dify的接口文档和实际使用有出入,这个折腾了好久,主要是我想用父子分段,想自定义分段模式
在父子分段里是hierarchical,跟踪前端页面找到的。
父子分段上传成功以后,也不会自动分段,再点击分段,报错,暂时还没有解决。
坑二 failed to run: Failed to parse JSON:
如果爬取的文章内容里面各种格式,又是markdown,又是代码的,很容易出现这个问题,而且你在postman上验证通过,在这里也通不过。需要写代码自己清洗,但是清洗就是一个无底洞,不要尝试。或者是你自己手写json,多一个或少一个标点符号。
坑三 400 The browser (or proxy) sent a request that this server could not understand.
调试的时候,经常出现400,报错信息为The browser (or proxy) sent a request that this server could not understand,一般情况下都是你的json问题。从postman复制概率就很小
405
405 Method Not Allowed,你把请求方式设置错了,本来是post,设置成了get,就报
我把工作流扔网盘里,大家有需要可以下载。群友分享的几十个dify工作流。
