

同时大家也提了一些问题,汇总一下大家的问题:
-
已经有现成的知识库(自动采集) -
embdding向量拆分的时候可能会丢失信息(分段优化) -
给llm的信息受token数量限制(分级召回策略) -
使用dify建知识库加集成ollama,感觉效果一般(索引优化) -
局域网内多终端访问同一个向量数据库(web应用)
在后面方案里详细地给大家说明。
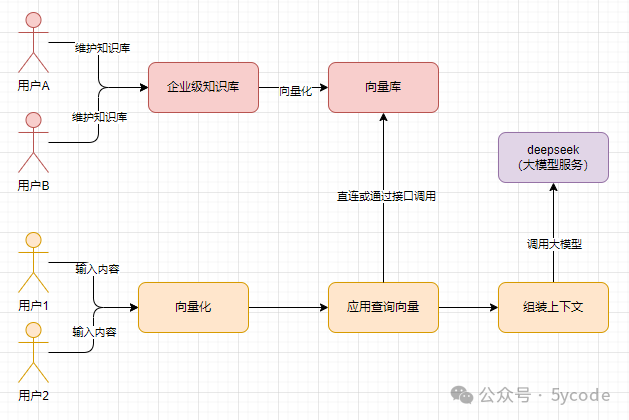
方案说明
我简单地梳理了下流程。理想的情况下:
-
知识的维护是一波人,维护过后的知识,直接向量化到向量库了里 -
知识的使用可能是另外一波人,他甚至都不知道有这些知识,只是在应用的时候,自动检索到并组装上下文给到deepseek。
知识库
-
支持多人同时编辑 -
具备以下条件: -
事件通知机制:新增或修改以后同步通知(有最佳) -
有对外的api或可以爬取的页面
关于dify 和MaxKB的知识库
共同点:
-
都可以使用通用知识库:(上传文档) -
可以网页抓取(支持同步) -
可以设置分段模式,也可以自定义分段(解决文档结构的差异性) -
指定向量模型 差异点: -
dify支持直接写接口查询向量库(ps:两边的规则要一致) -
dify 检索可以调整相似度阈值和Rerank 模型(进行重新排序,从而改进语义排序的结果)
向量化
高精度要求建议自己写程序处理,更准确一些,能解决索引质量和信息丢失的问题 因为每个企业的知识结构和习惯不一样,大家处理数据的方式也会有差别,这个需要好好的调试。 这里注意的是需要记录下每篇知识向量化后的id,以及对应的版本或时间戳,方便后续删除向量数据。 deepseek给的方案是
分段优化三原则:
▸ 语义完整性校验(BERTScore>0.85)
▸ 动态重叠窗口(建议15%-20%文本长度)
▸ 关键实体锚点锁定(使用spaCy实体识别)
低精度要求会有一定的丢失概率,直接使用dify或maxKB即可。
-
分段标识默认都是/n (需要根据自己的结构化调整) -
分段重叠长度 设置为tokens大小的10%~15%
向量库(具备研发能力)
具备研发能力的同学,可以看这块。
-
根据数据量的大小和是否持久化评估自己评估 -
Dify 在 v0.6.x 及更高版本中默认集成 PGVector(基于 PostgreSQL 的向量扩展)在配置文件中可改 -
MaxKB 默认使用 Weaviate 作为向量存储引擎
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
选型建议
-
超大规模数据+分布式:Milvus、Vespa。 -
高维向量+GPU加速:FAISS(需自研存储层)、Milvus。 -
轻量级+快速开发:Chroma、Annoy。 -
混合查询(向量+属性):Weaviate、Qdrant。
提示: 实际性能受数据维度、硬件配置(如SSD/NVMe)、索引参数影响强烈,建议通过真实数据基准测试验证。
应用客户端
要求如下:
-
可以外部访问(web应用或提供api) -
可以直接使用外部的向量库或通过api调用 -
不需要自己再添加文档,向量化到向量库里 -
可以关联知识库 -
可以召回
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MaxKB和dify 都可以召回,我们可以通过高级功能,做一个流程来解决问题3。先获取topn的向量,大模型排序,根据规则进行过滤。 deepseek给的解决方案:不知道dify和maxKB如何配置。
① BM25粗筛(Top100)→ ② 向量精排(Top10)→ ③ 元数据过滤
MaxKB
创建应用的时候,可以关联多个知识库,高级应用可以做流程编排。
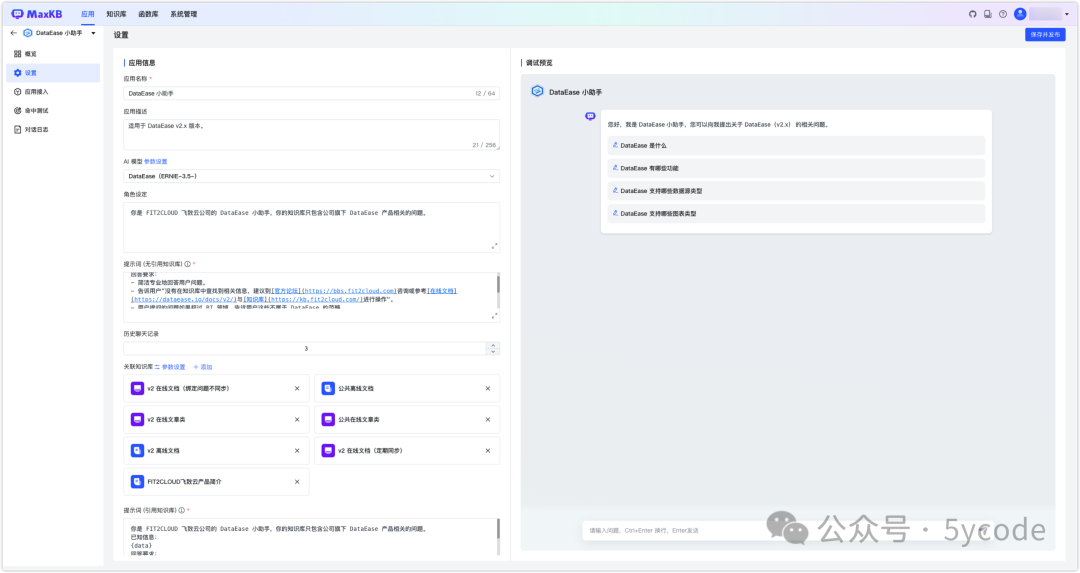
MaxKB 的智能分段,
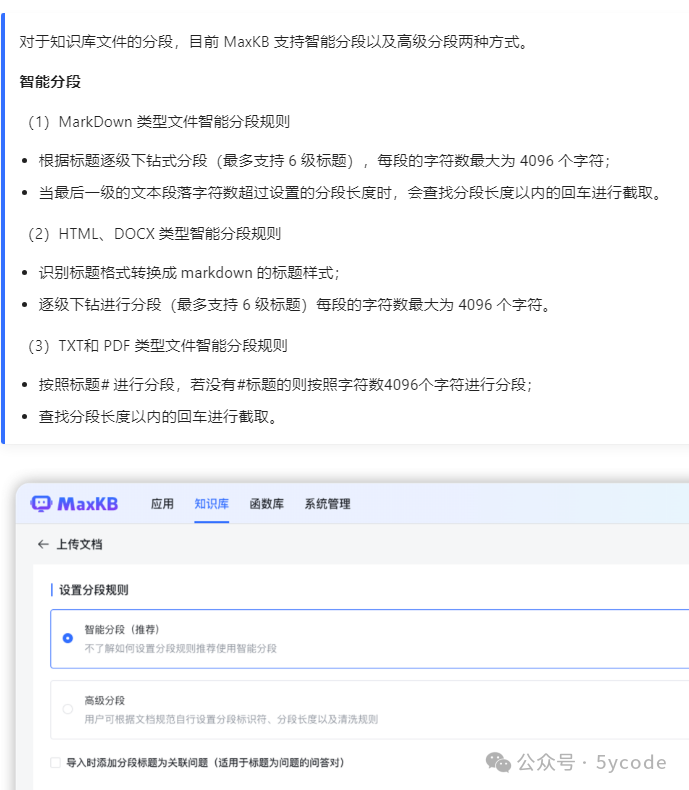
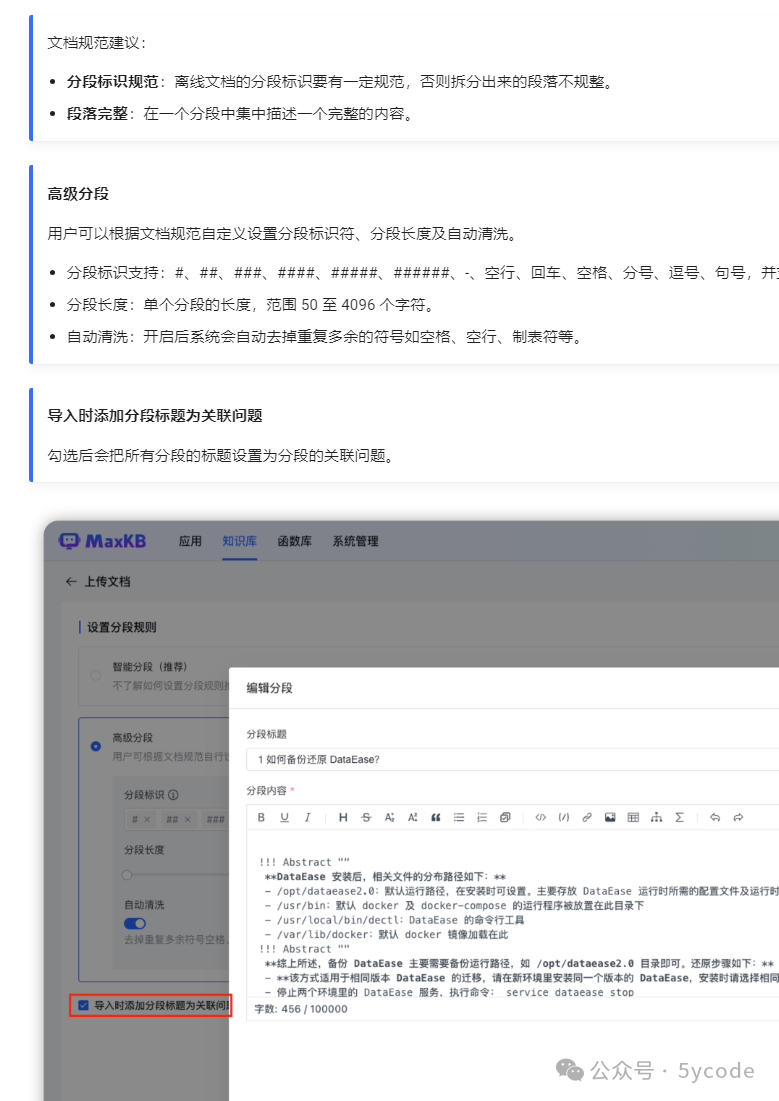
dify
创建应用的时候也可以关联多个知识库。可以设置多路召回。
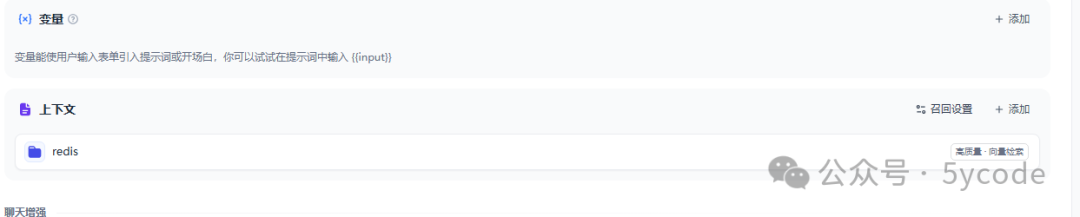
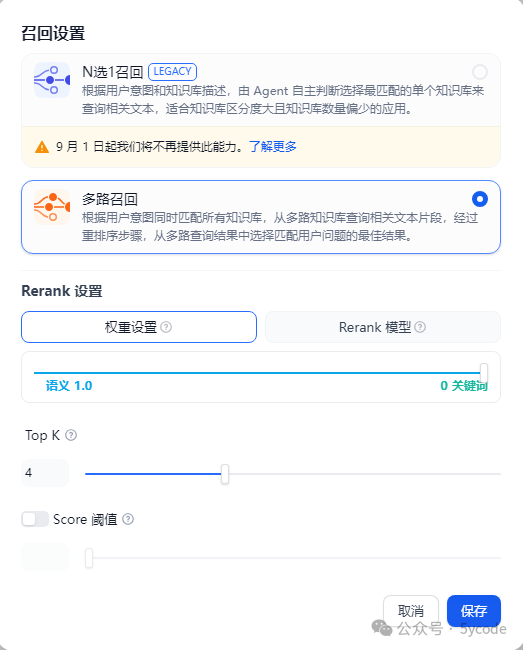
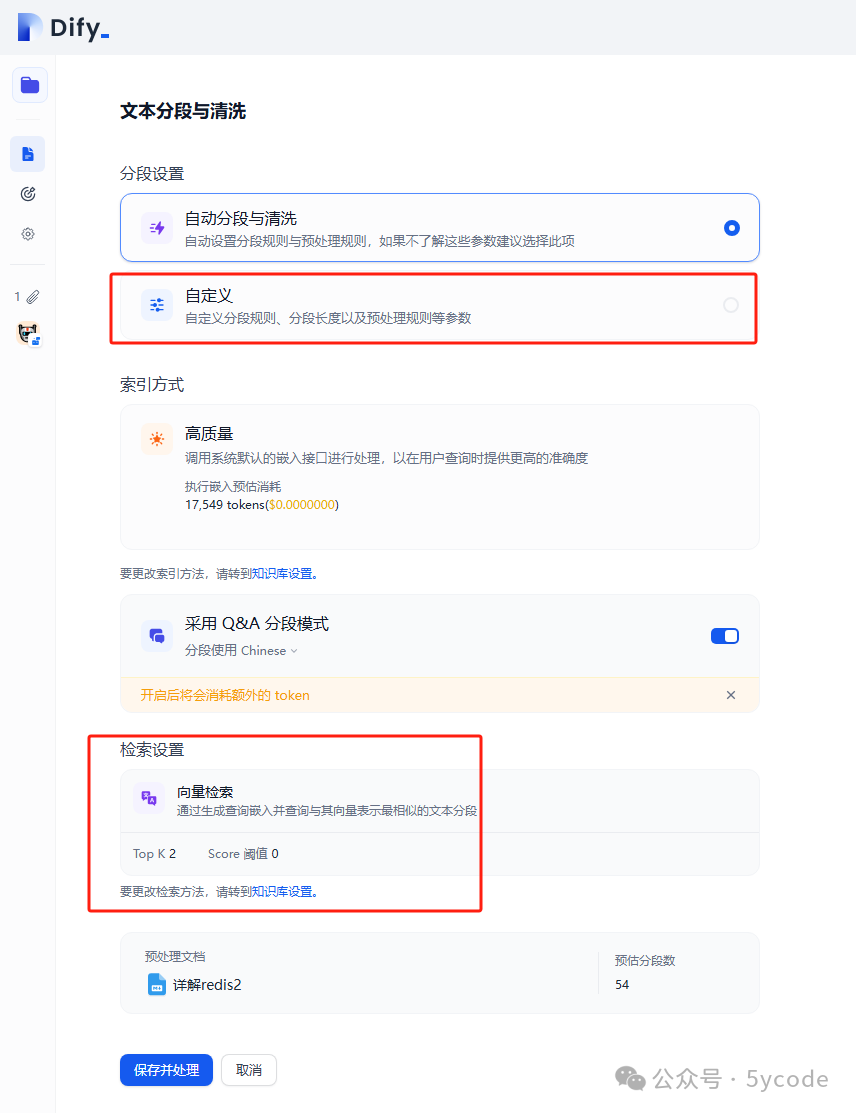
dify中知识库分段和清洗可以自定义设置
FastGpt
总结
-
在不想动用人力开发的情况下。企业内部的知识库使用dify和MaxKB都可以。dify的定制性功能更强一些。 -
分段和检索那块好好的调教下 -
对有研发能力,可以使用dify+自定义数据,能实现多种可能性,精度由自己的程序控制。只要调教好检索即可。
