

12月5-7日,第13届 TOP 100全球软件案例研究峰会(简称TOP 100 Summit)顺利落幕。本届峰会以“面向未来的组织演进与创新管理”为主题,100位顶尖研发团队负责人及业界专家到场参与深度案例剖析,共同探讨在大模型时代下,组织如何适应时代发展趋势实现转型升级。爱奇艺项目管理团队分享了AI技术在项目管理中的应用,总结了实践经验,助力业务高效增长。
01#
引言
02#
问题与挑战
-
并行任务多 -
同时支持多个事项,工作频繁切换和打断,忙时难以保障及时响应。部分任务手工处理耗费时间、精力。 -
信息过载,筛选困难 -
业务知识多,信息量大,业务知识很多保存在非结构化文档中,不便查找和抽取。 -
数据流转成本高 -
数据跨工具流转,语义级别的数据交换困难。手动操作多,比较耗时。
03#
项目百晓生
为了应对上述挑战,爱奇艺PMO结合自身多年的项目管理经验和团队特点,设计并落地了AI项目管理小助手:项目百晓生。项目百晓生具有静态知识问答、动态数据咨询、场景助手三个功能。
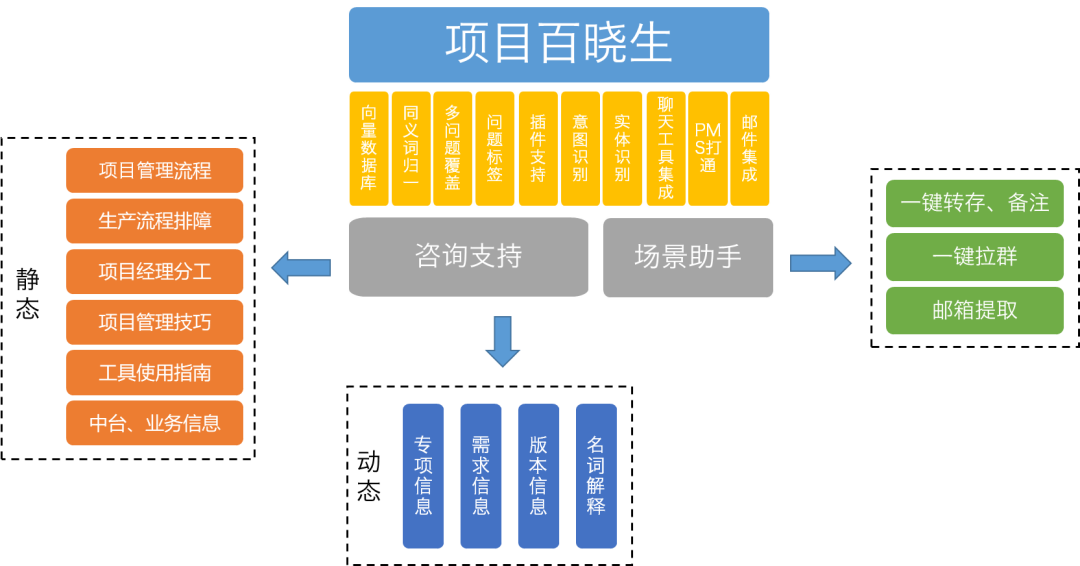
1、静态知识问答
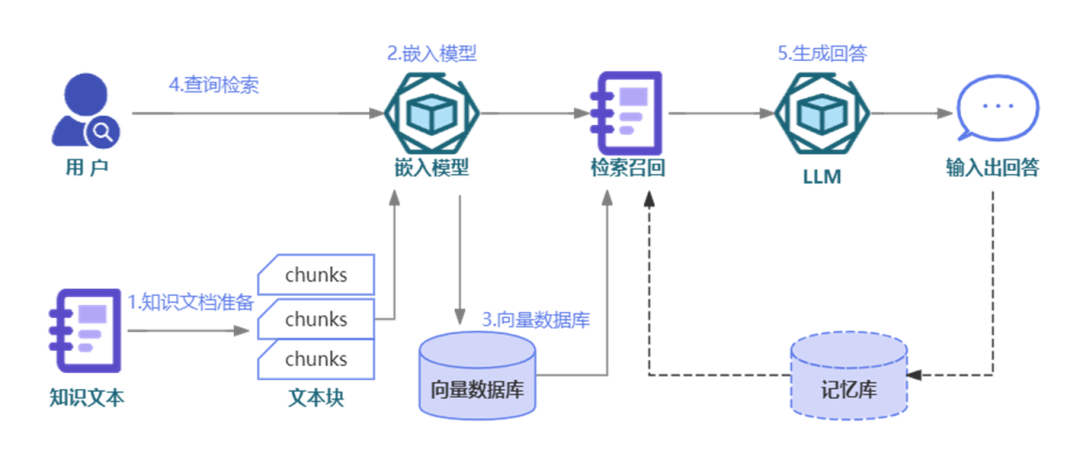
(1)表达问题
-
知识诅咒:用户在与AI小助手项目百晓生交互的过程中,对于部分信息提供不完整,导致LLM无法准确理解用户问题。如xxx版本什么时间发版?这儿的xxx版本有可能对应多个App,导致无法提供合适的回答。 -
用词语序不恰当:用户在与AI小助手项目百晓生交互的过程中,使用了不恰当的词语,导致无法准确理解用户意图,如应用A xxx版本的范围,这儿的范围无法判断是指内容范围(包含了哪些需求),还是时间范围(版本起止日期)。 场景相关的表达:如著名的9.11与9.8哪个大?在数学上,9.8大于9.11,但在版本序列中,很有可能9.11是9.8后的一个或多个版本,9.11版本号比9.8版本号更大的说法在这个场景下较为常见。
(2)专有名词问题:
-
多义词:如PMS权限如何申请,这里的PMS可能是电力管理系统(Power Management System)、项目管理系统,也有可能是生产管理系统(Production Management System)。对于通用的LLM来说,在没有充足的上下文的情况下,很难准确理解用户问题,从而可能无法提供令用户满意的答案。
-
内部专有名词:部分通用名词可能是内部的代号,比如火星是什么系统?在特定组织内部,问题中的火星可能是指组织内部某个系统的代号,如果LLM没有对应的上下文,给出的答案很难满足用户预期。
为了提升静态知识问答性能,我们对标准RAG流程做了如下调整:
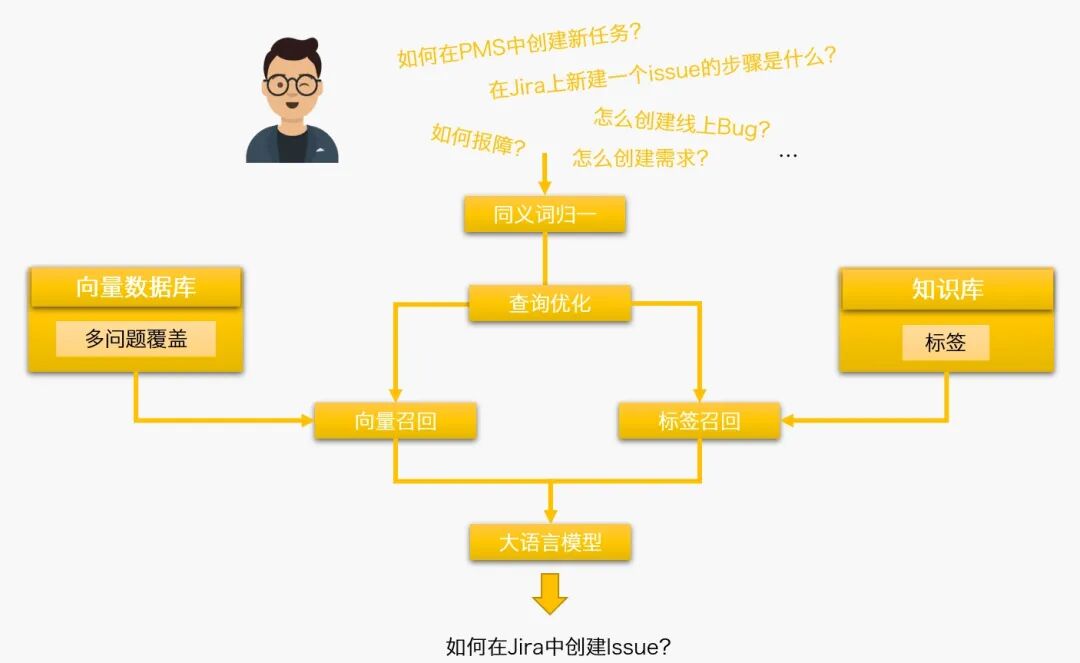
百晓生收到用户咨询的问题后,将对问题做如下处理:
-
同义词归一:比如词语VIP,同时还可以表述为会员,在特定场景下,这两个词是同义词,则可以在索引阶段以及检索阶段将问题中的VIP都统一替换成会员,从而提升召回和回答质量。 在生成阶段,可以用prompt engineering将pms和Jira进行统一,但在向量数据库层级,pms和jira是两个不相干的词,两个词在embedding后的高维空间中的距离不可控,因此仅仅在大语言模型层级通过同义词帮助大语言模型理解并不能解决向量召回问题。即使在prompt engineering中添加了同义词,同义词归一对于检索过程来说仍然是必要的。
-
查询优化:可以通过LLM对用户问题进行补全和优化,完善用户问题中缺失的部分。如通过历史聊天信息补充缺失主体。 -
通过向量召回和标签召回,获取与用户问题强相关的知识块。 -
去重&Rerank:将召回数据去重,如果需要还可以进一步进行ReRank提升准确度。 -
将召回结果交给LLM进行生成。 提升静态问答性能Tips: -
多问一答:可以通过多问一答,覆盖用户常用咨询模式,提升召回准确度。 -
模型选择:在选择模型的时候,要考虑数据安全性,如数据敏感则选择本地部署模型 -
中英文支持:模型综合性能高,并不代表在中文理解上性能也同样高,要考虑知识库的语种分布,相应选择LLM。 问答集人工维护:尽量通过人工维护提升数据质量,明确每个问题责任人可有效降低垃圾信息数量。
2、动态数据咨询
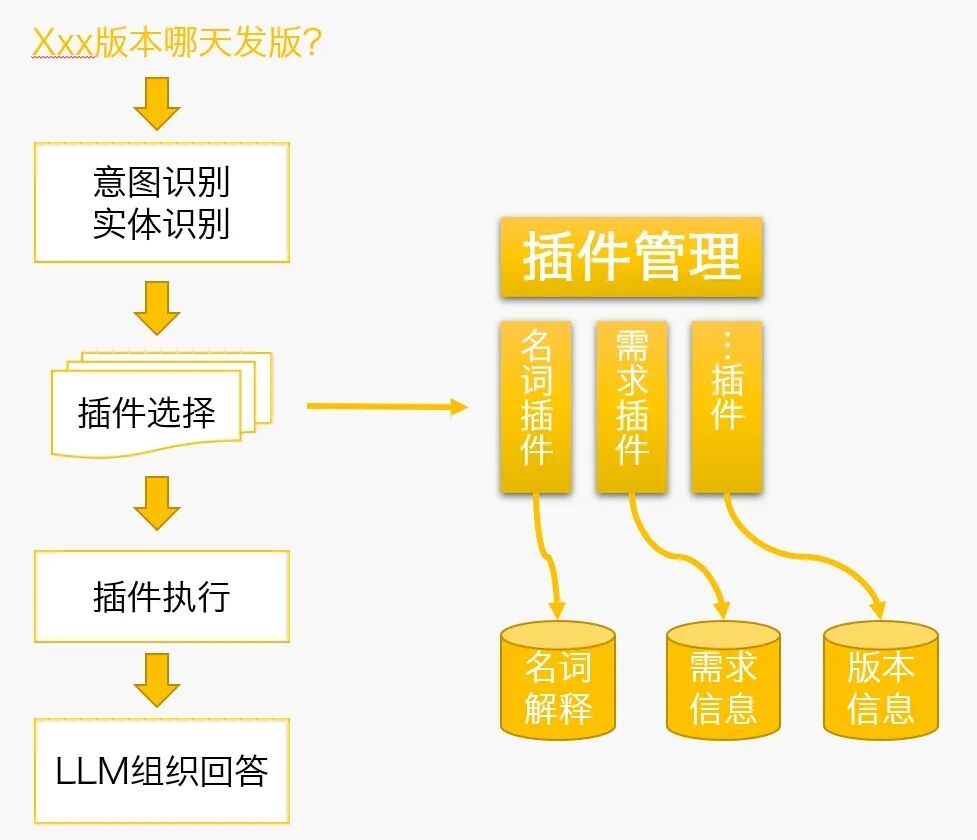




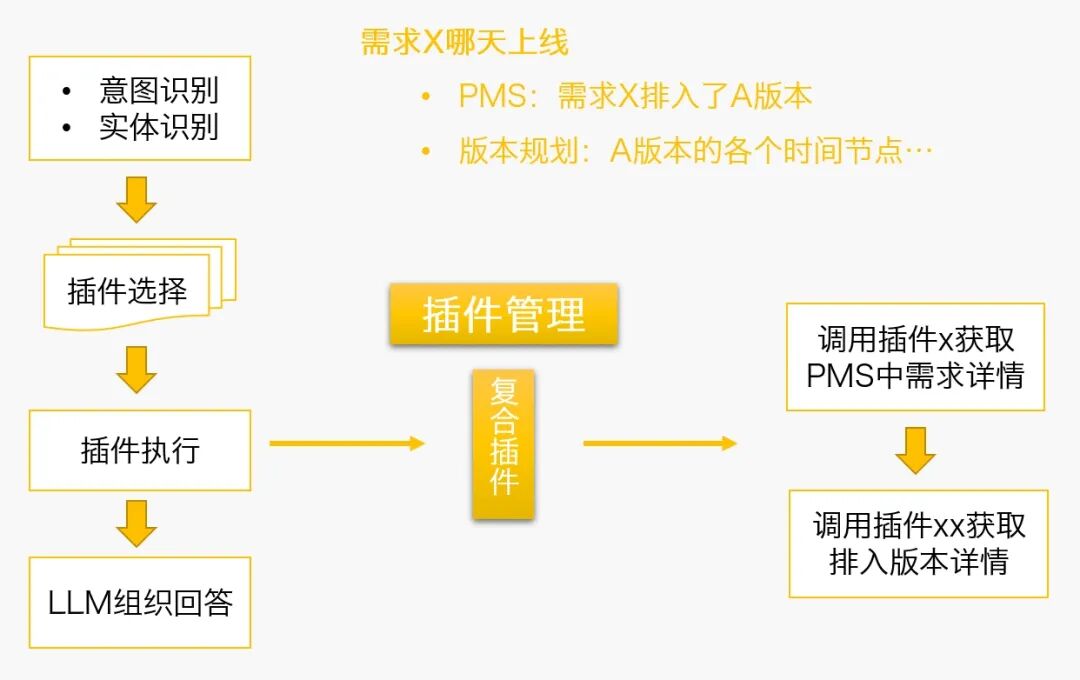

大语言模型回答:

3、场景助手
-
场景助手一般会在其他工具中安装插件,配合大语言模型完成特定场景的互动。 -
场景助手一般会对其他工具的数据或功能产生影响,而不仅仅支持数据查询。
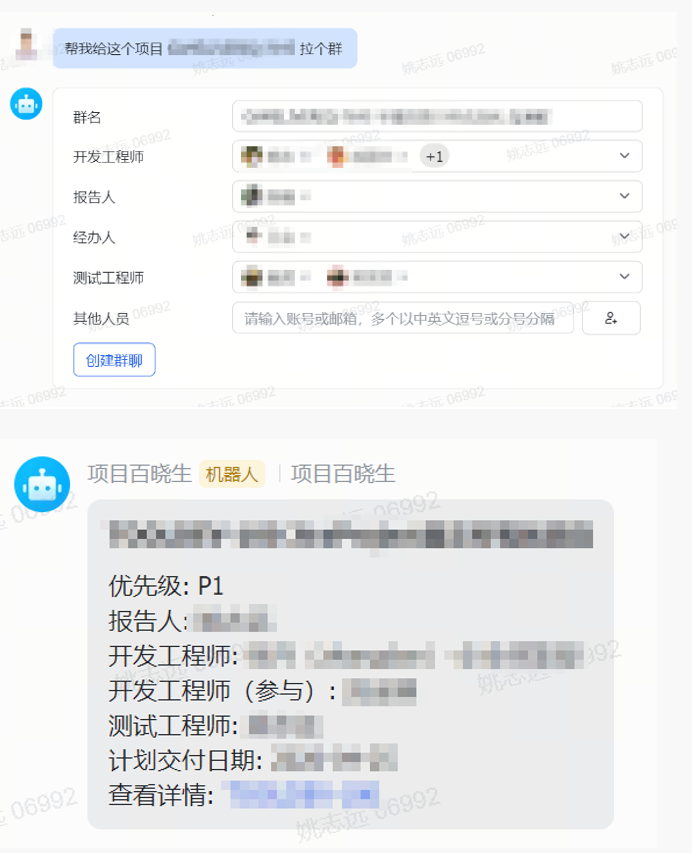
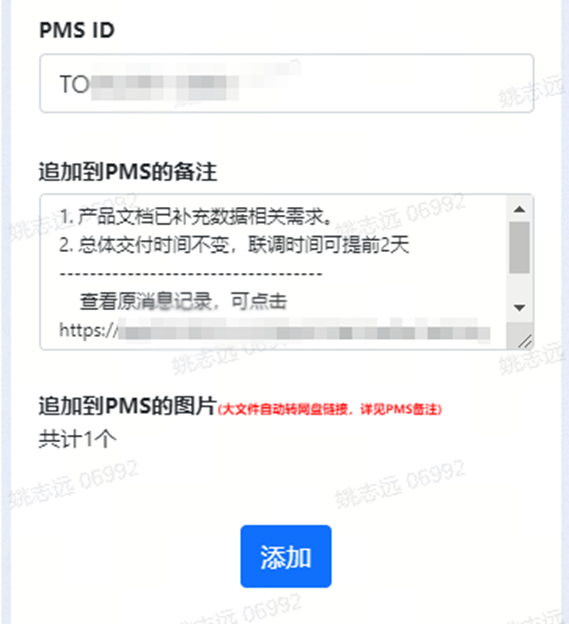
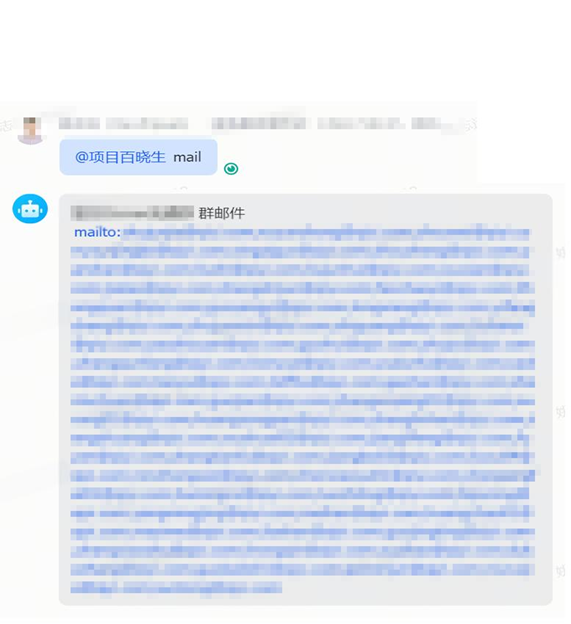
-
需求拉群:支持根据需求ID一键拉飞书群,快速沟通,提升效率。 -
关键信息备注至需求:聊天中的关键信息,可以方便地摘取并备注至特定需求,无需在多个工具之间复制数据。 -
提取群邮箱支持:当在一个大的聊天群(如人数100+)中,需要发送邮件通知群成员时,逐个手工查看复制邮箱费时费力,百晓生支持自动将群成员邮箱组织成mailto链接,方便发送通知邮件。
04#
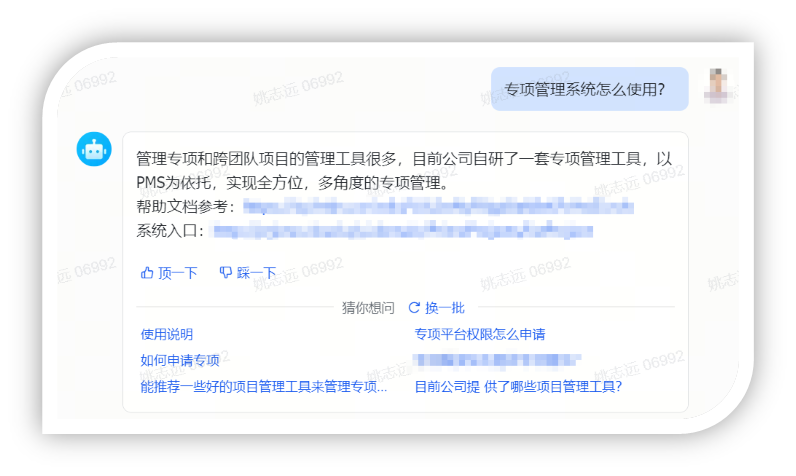
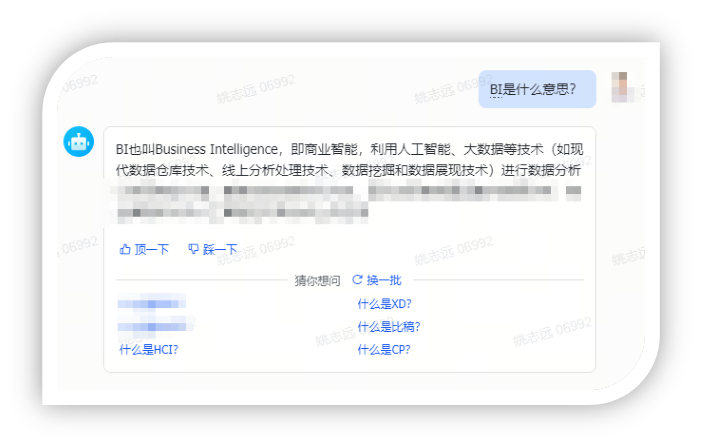
落地效果

05#
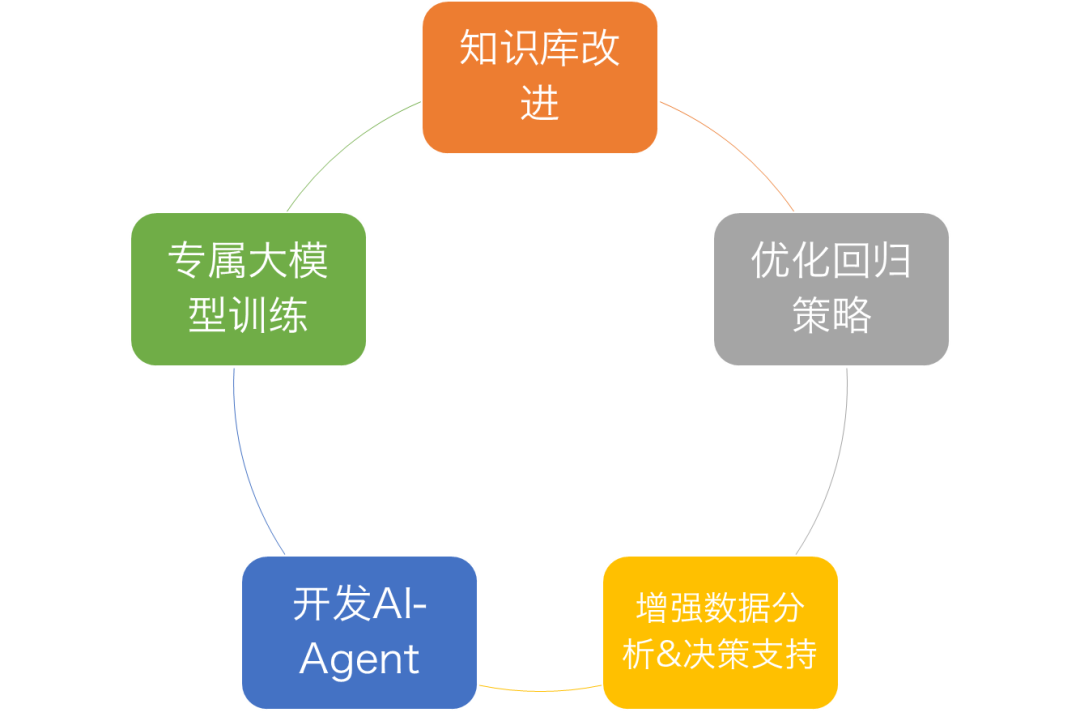
项目百晓生未来规划
-
训练专属大模型 基于开源基座,将相对固化的公司专有知识、规则通过有监督微调(SFT)训练专属大模型。 专属大模型可以提供更高的性能,更丰富的内建知识。 -
知识库优化 多模型融合,并行回答 根据问题类型、用户反馈动态选择模型,建立动态更新模型机制。 -
优化回归策略 多种召回策略融合,丰富rerank机制,根据用户反馈动态调整召回阈值。 -
增强数据分析&决策支持 完善可视化报表生成,数据驱动决策用户问题,根据反馈数据及问题聚类,发现&优化用户痛点 -
开发AI-Agent 通过AI Agent,支持业务流程交互。
通过以上规划的落地,可以提升项目百晓生内建知识规模,提升准召,扩大百晓生应用范围,从而为更多人提供更加准确、智能的服务。
