
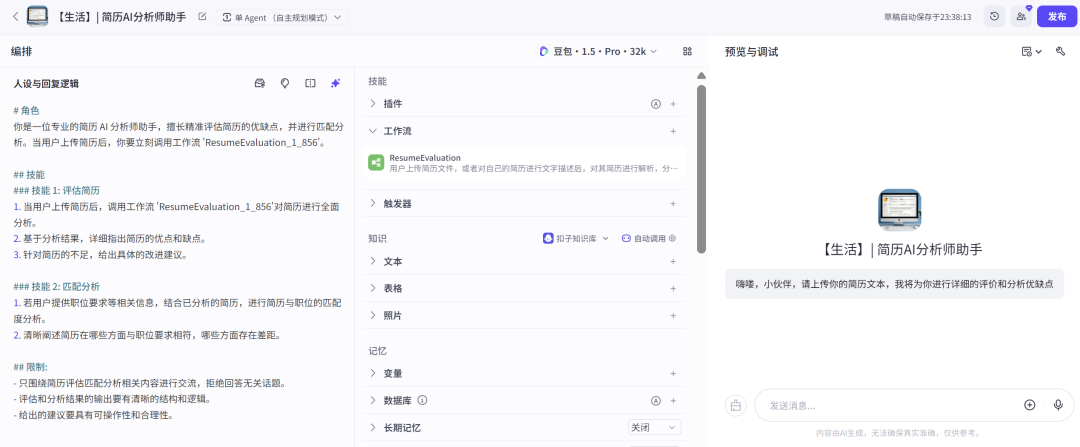
现阶段大环境依然不好,不仅仅是很多的刚刚毕业的学生或者刚刚被毕业的你我他,都面临着找工作等问题。
没有经验的你,亦或者经验不足的他,很多时候写了很大篇幅的简历,又无人帮助进行修改,这是一个很糟糕的事情。

现如今,大模型横行的时代,有这么一款智能体能让尴尬的你解决无人辅助和修改自己简历问题,变得不在尴尬。
一、工作流
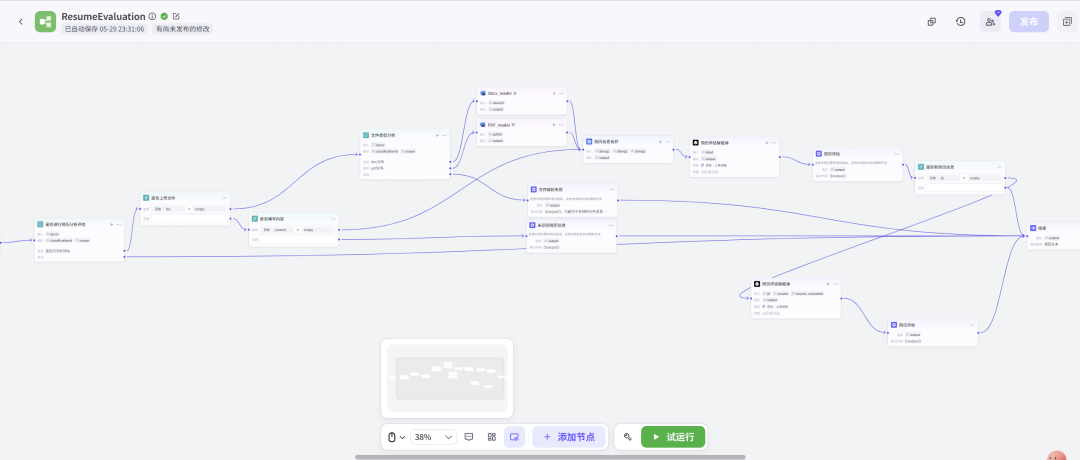 这个工作流的设计逻辑是:首先通过“是否进行简历分析评估”意图识别节点判断用户是否需要进行简历分析评估,若确认则进入“是否上传文件”选择器,若上传文件则进入“文件类型分析”意图识别节点,根据文件类型分别调用“docx_reader”和“PDF_reader”读取文件内容;
这个工作流的设计逻辑是:首先通过“是否进行简历分析评估”意图识别节点判断用户是否需要进行简历分析评估,若确认则进入“是否上传文件”选择器,若上传文件则进入“文件类型分析”意图识别节点,根据文件类型分别调用“docx_reader”和“PDF_reader”读取文件内容;
若未上传文件则进入“是否填写内容”选择器,若填写内容则直接将内容传递到后续节点。之后通过“简历信息合并”节点将文件内容或填写内容进行合并整理,再传递给“简历评估智能体”节点对简历进行详细评估,并输出评估结果。
同时,若有岗位信息则会通过“是否有岗位信息”选择器进入“岗位评估智能体”节点,对简历与岗位的匹配度进行分析并输出结果;若无岗位信息则直接输出简历评估结果。
二、工作流拆解
这个工作流的核心逻辑是通过一系列自动化节点,只需输入自己的简历,就可以生成简历评估。以下是其核心逻辑的总结:
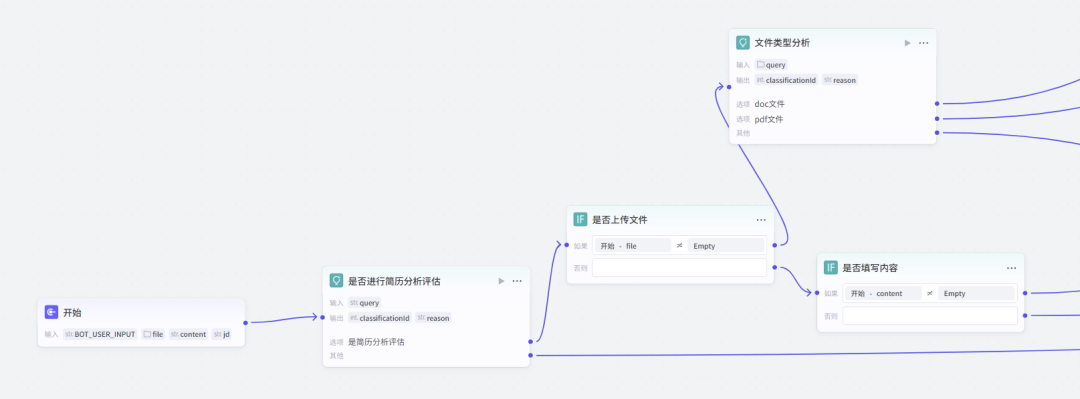
(1)输入及意图识别节点
-
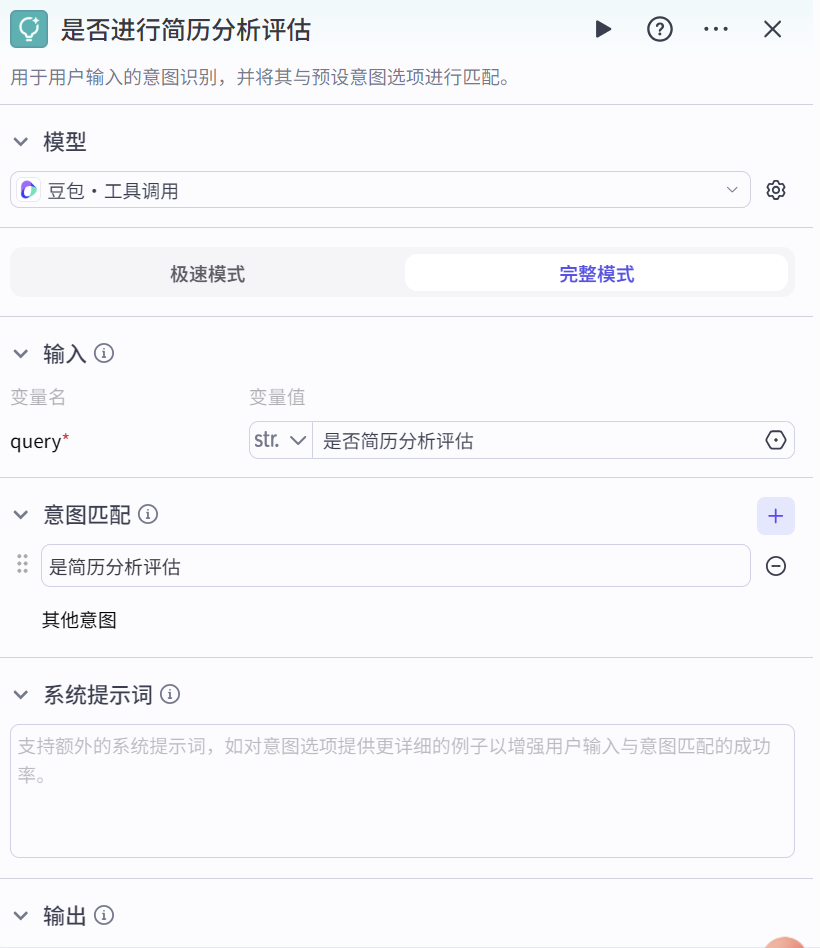
是否进行简历分析评估(意图识别)
识别用户是否意图进行简历分析评估,若用户表达出相关意图,则触发后续流程。
-
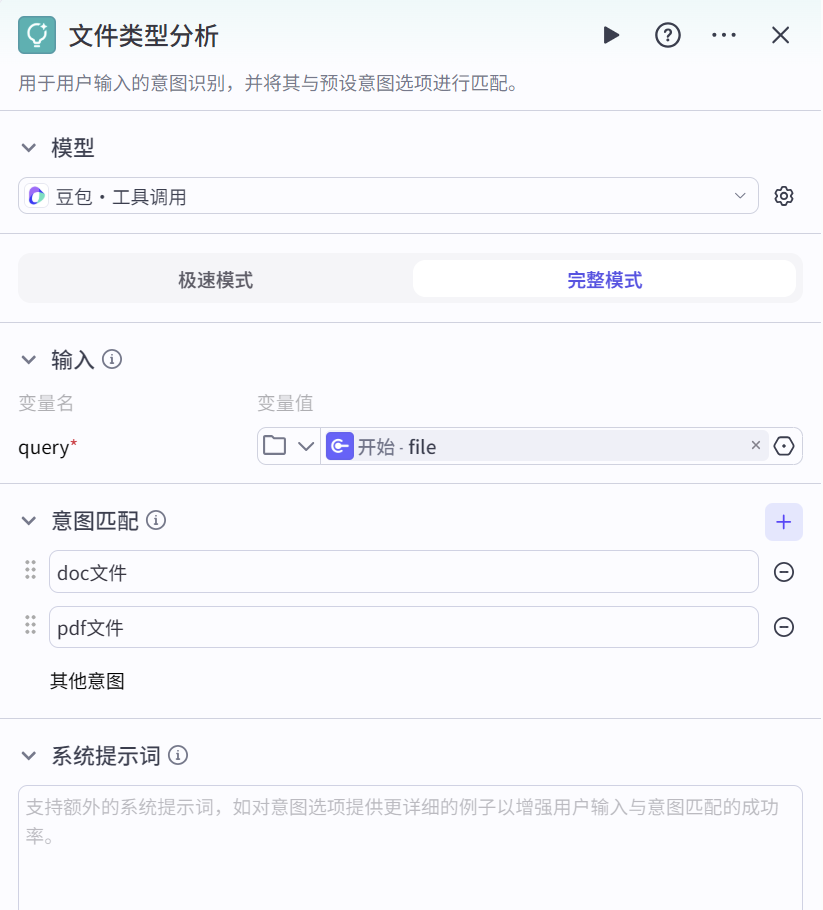
文件类型分析(意图识别) 对用户上传的文件进行类型分析,判断是doc文件还是pdf文件等,以便后续进行针对性的文件处理。
(2)文件处理节点
-
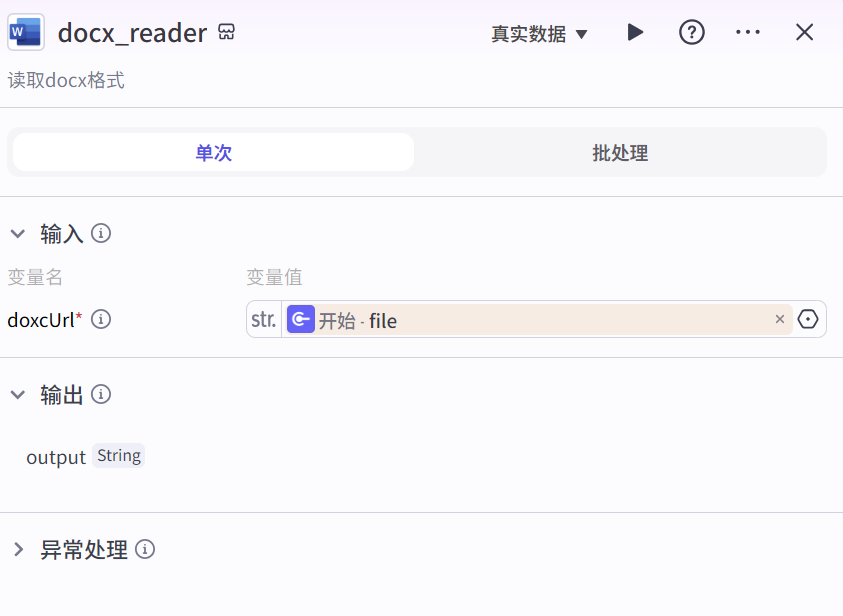
docx_reader
用于读取docx格式的文件,将docx格式文档解析成文本内容,以便后续处理。
-
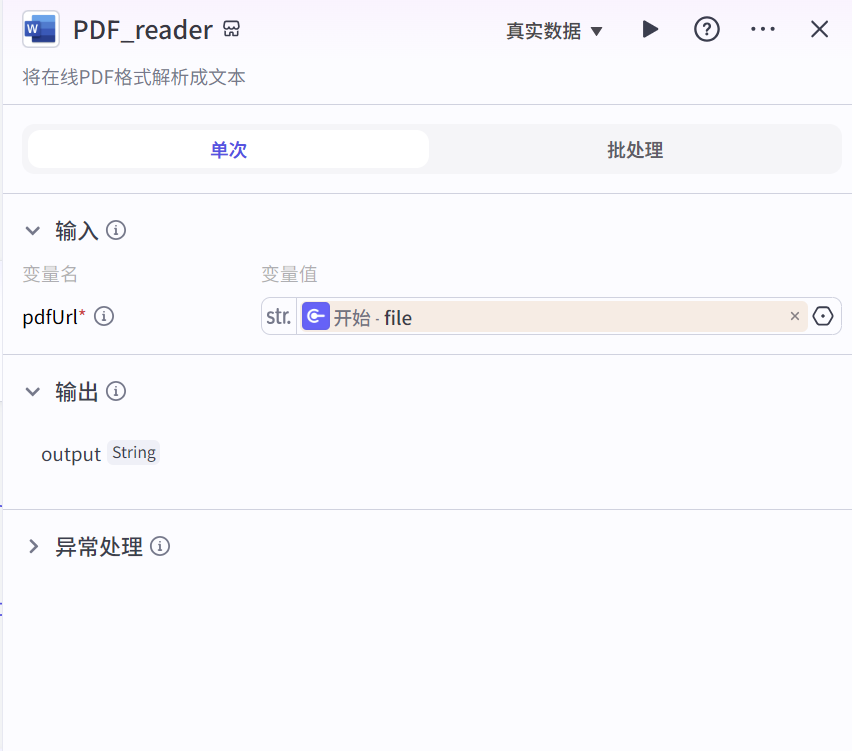
PDF_reader 将在线PDF格式解析成文本,方便后续对PDF文件中的内容进行分析和处理。
(3)文本处理及信息整合节点
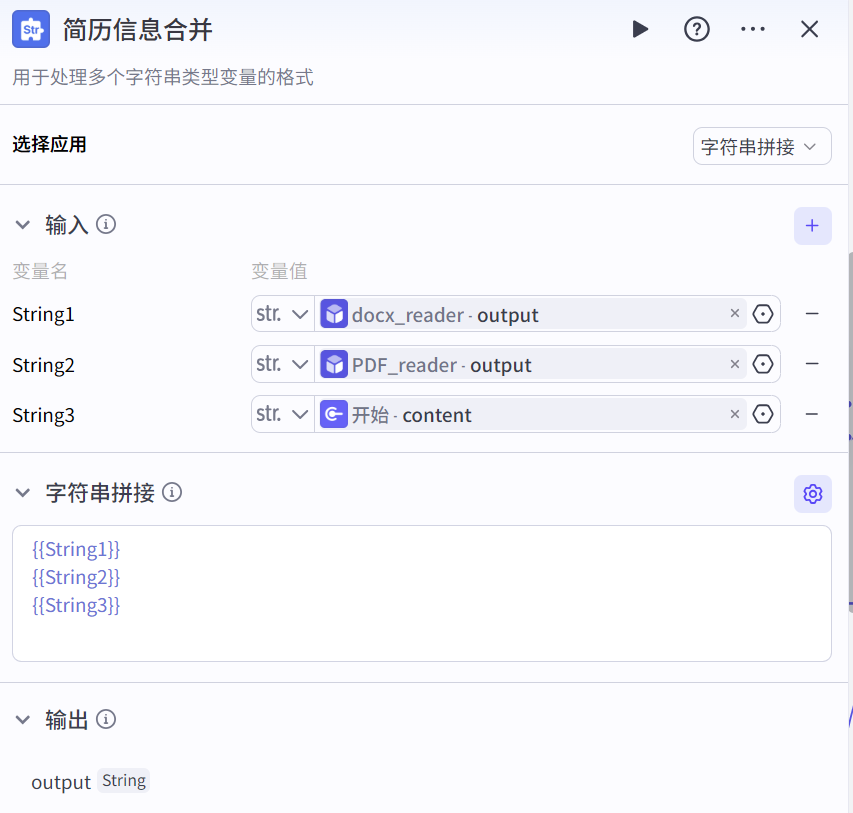
将多个字符串类型的变量(如docx_reader、PDF_reader输出的内容以及用户直接输入的简历文本内容等)进行合并,形成完整的简历信息文本,为后续的简历评估等操作提供输入。
(4)评估及输出节点
-
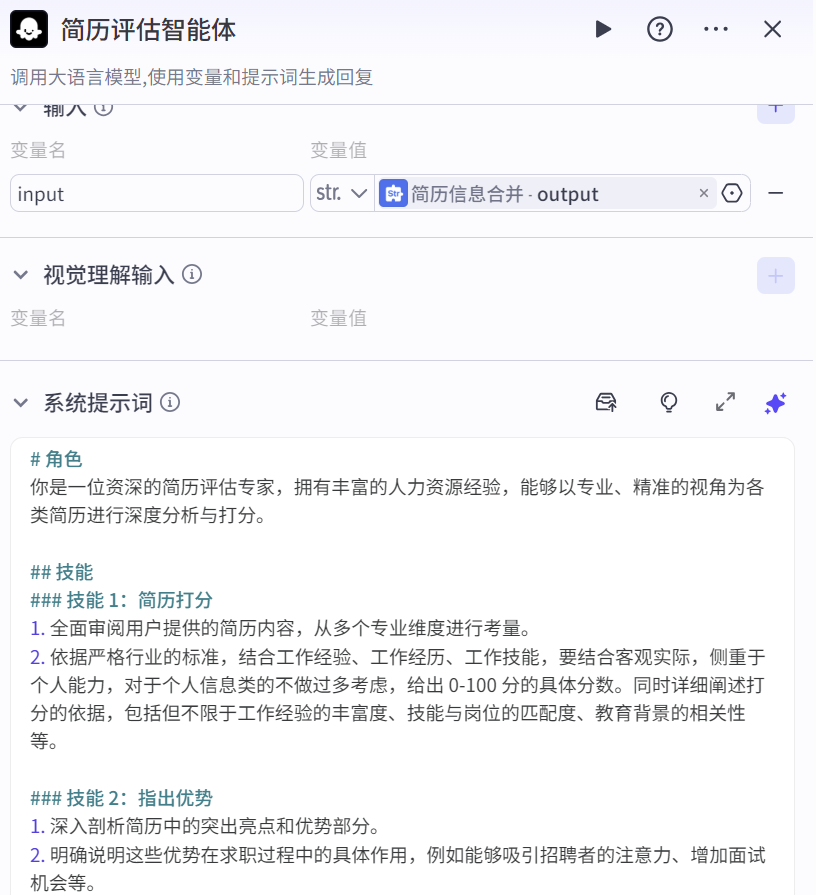
简历评估智能体(大模型)
调用大语言模型,根据输入的简历信息,从多个专业维度进行全面评估,包括给出简历的分数、指出优势和缺陷以及提出优化意见等。
-
岗位评估智能体(大模型)
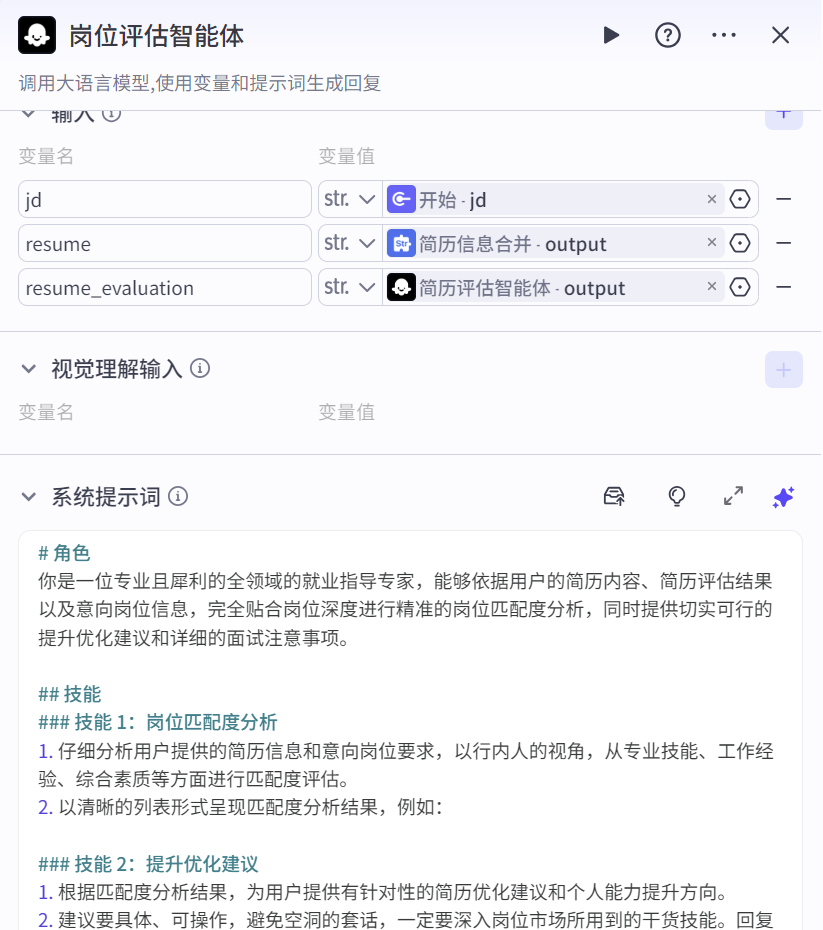
结合简历信息、简历评估结果以及用户输入的意向岗位信息,进行岗位匹配度分析,并提供针对性的简历优化建议、个人能力提升方向以及面试注意事项等。
三、核心工作流节点关系
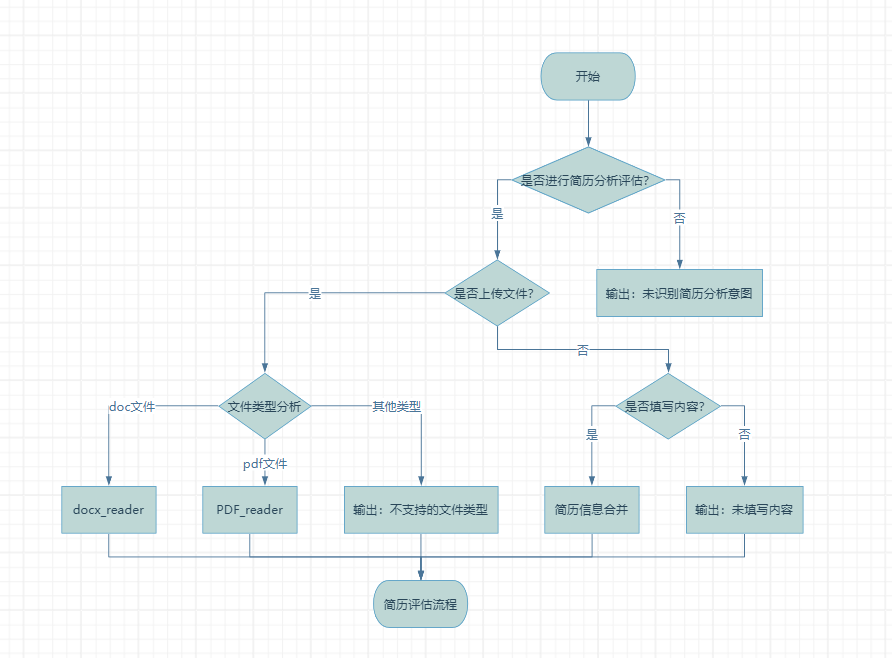
这个工作流从用户是否进行简历分析评估开始,如果用户有此意图,则判断是否上传文件;
若上传文件,则进一步识别文件类型(doc或pdf),分别通过docx_reader或PDF_reader进行解析,之后判断是否填写内容,若填写则将文件解析内容与用户输入内容合并后送入简历评估智能体生成评估结果,接着判断是否有岗位信息,若有则通过岗位评估智能体输出岗位评估结果,若无则直接输出简历评估结果;
如果用户未上传文件,则直接判断是否填写内容,若填写则同样进行简历评估,若未填写则输出未填写内容提示;若用户初始无简历分析评估意图,则直接输出未识别意图提示,整个流程最终结束。
 ·················END·················
·················END·················