

一、流程概述
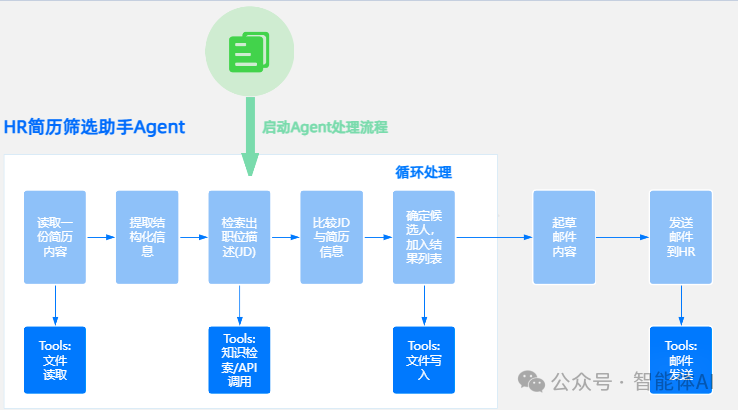
-
启动Agent处理流程:实现自动化的简历读取、信息提取和初步筛选。
-
循环处理流程:筛选符合要求的候选人,并通过邮件通知HR,完成整个流程闭环。
以下内容将通过逐步解析每一个环节,并结合代码示例,带你深入了解这一智能化流程的核心实现。
二、每步进程详解
1. 自动读取简历内容:解锁文本数据
-
工具:文件读取(File Reader)
-
核心功能:解析简历文件,提取文本数据。
代码示例:
import PyPDF2def read_file(file_path):try:with open(file_path, 'rb') as file:reader = PyPDF2.PdfReader(file)content = ""for page in reader.pages:content += page.extract_text()return contentexcept Exception as e:print("文件读取错误:", e)return None# 假设简历为PDF文件resume_path = "./resumes/candidate1.pdf"resume_content = read_file(resume_path)print("简历内容:", resume_content)
通过该代码,简历文本被解析并存储到内存中,为后续操作做好准备。
2. 提取构件信息:让数据变得有结构
从简历文本中提取关键信息(如姓名、年龄、学历等),是后续分析的重要步骤。
-
工具:知识推理API调用
-
核心功能:将非结构化文本转化为结构化数据。
代码示例:
import redef extract_info(resume_text):try:name = re.search(r"姓名[::]s*(w+)", resume_text).group(1)age = re.search(r"年龄[::]s*(d+)", resume_text).group(1)degree = re.search(r"学历[::]s*(w+)", resume_text).group(1)experience = re.search(r"工作经验[::]s*(d+年)", resume_text).group(1)return {"name": name,"age": age,"degree": degree,"experience": experience}except Exception as e:print("信息提取错误:", e)return None# 提取简历中的关键信息structured_data = extract_info(resume_content)print("提取的信息:", structured_data)
通过这段代码,Agent能够快速从简历中抓取HR关注的关键字段,大幅提升效率。
3. 检测重复简历:避免无效工作
重复的简历不仅浪费时间,还会干扰筛选结果。因此,需要在数据库中检索是否已经存在相同的简历。
-
工具:数据库查询
-
核心功能:避免重复处理,提高筛选效率。
代码示例:
existing_ids = {"12345", "67890"}def check_duplicate(candidate_id):return candidate_id in existing_ids# 假设每份简历有唯一的IDcandidate_id = "12345"# 示例IDis_duplicate = check_duplicate(candidate_id)if is_duplicate:print("发现重复简历,跳过处理。")else:print("简历是新的,继续处理。")
这一功能确保了每份简历都被高效管理,避免重复操作。
4. 匹配职位要求:精准筛选候选人
根据职位要求,对简历进行规则匹配,筛选出符合条件的候选人。
-
工具:规则匹配算法
-
核心功能:快速剔除不符合要求的简历。
代码示例:
def match_criteria(candidate_data, job_criteria):try:experience_years = int(re.search(r"d+", candidate_data["experience"]).group())return (experience_years >= job_criteria["experience"] andcandidate_data["degree"] == job_criteria["degree"])except Exception as e:print("匹配错误:", e)return False# 职位要求的条件job_criteria = {"experience": 3, "degree": "Bachelor"}match_result = match_criteria(structured_data, job_criteria)if match_result:print("候选人符合要求。")else:print("候选人不符合要求,移除。")
通过这一环节,Agent能准确锁定合适的候选人,节省HR筛选时间。
5. 保存筛选结果:形成合规名单
将符合条件的候选人信息保存到合规表中,方便HR后续查看和跟进。
-
工具:文件写入(File Writer)
-
核心功能:结构化保存数据。
代码示例:
import csvdef write_to_file(file_path, candidate_data):try:with open(file_path, mode="a", newline="", encoding="utf-8") as file:writer = csv.DictWriter(file, fieldnames=["name", "age", "degree", "experience"])writer.writerow(candidate_data)print("已将候选人信息添加到合规表。")except Exception as e:print("写入错误:", e)# 合规表路径compliance_file = "./results/compliance_list.csv"write_to_file(compliance_file, structured_data)
这一环节将筛选结果落地,形成明确的候选人名单。
6. 邮件通知HR:智能生成通知内容
为了节省HR时间,Agent会自动生成邮件内容,将筛选结果通知相关人员。
-
工具:邮件模板生成器
-
核心功能:生成清晰、专业的邮件内容。
代码示例:
def generate_email(to_email, candidate_data):subject = f"候选人推荐:{candidate_data['name']}"body = (f"尊敬的HR,nn推荐候选人信息如下:n"f"姓名:{candidate_data['name']}n"f"年龄:{candidate_data['age']}n"f"学历:{candidate_data['degree']}n"f"工作经验:{candidate_data['experience']}nn"f"请尽快联系候选人。")return subject, body# 生成邮件内容to_email = "hr@company.com"email_subject, email_body = generate_email(to_email, structured_data)print("生成的邮件内容:")print("主题:", email_subject)print("正文:", email_body)
通过自动生成的邮件内容,HR能够快速接收筛选结果。
7. 发送邮件:让信息无缝传递
最后一步是通过邮件发送工具,将筛选结果发送给HR。
-
工具:邮件发送(Email Sender)
-
核心功能:实现结果的快速传递。
代码示例:
import smtplibfrom email.mime.text import MIMETextdef send_email(to_email, subject, body):try:from_email = "your_email@example.com"password = "your_password"msg = MIMEText(body, "plain", "utf-8")msg["Subject"] = subjectmsg["From"] = from_emailmsg["To"] = to_emailwith smtplib.SMTP_SSL("smtp.example.com", 465) as server:server.login(from_email, password)server.sendmail(from_email, to_email, msg.as_string())print("邮件已发送至HR。")except Exception as e:print("邮件发送失败:", e)# 发送邮件send_email(to_email, email_subject, email_body)
这一功能确保了筛选结果能够迅速传递给HR,完成闭环流程。
三、工具总结
-
文件读取(File Reader):解析简历文件内容。
-
知识推理API(Knowledge Extraction API):提取关键字段。
-
文件写入(File Writer):保存筛选结果。
-
邮件发送(Email Sender):快速通知HR。
