

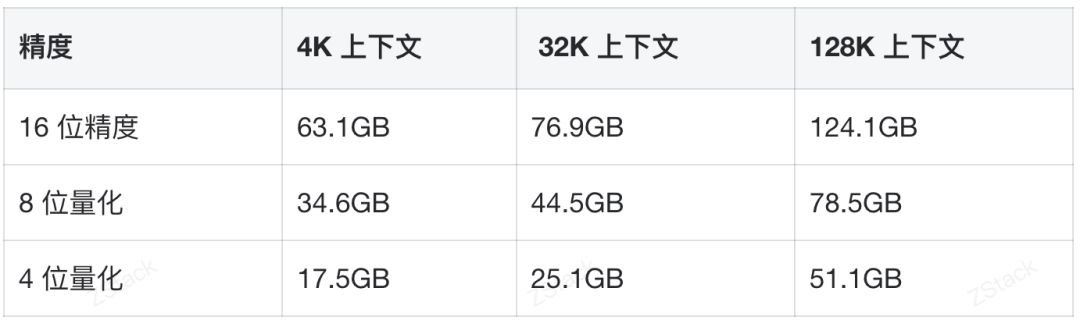
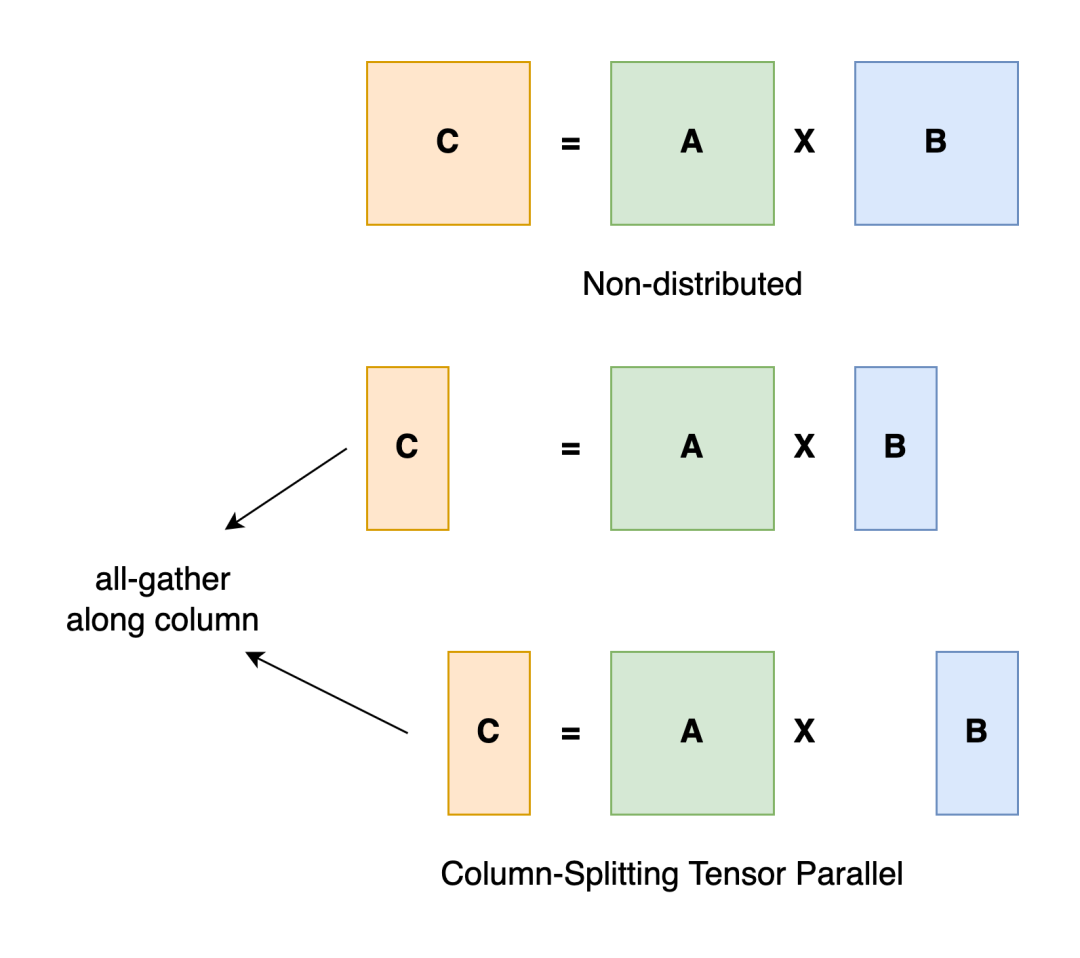
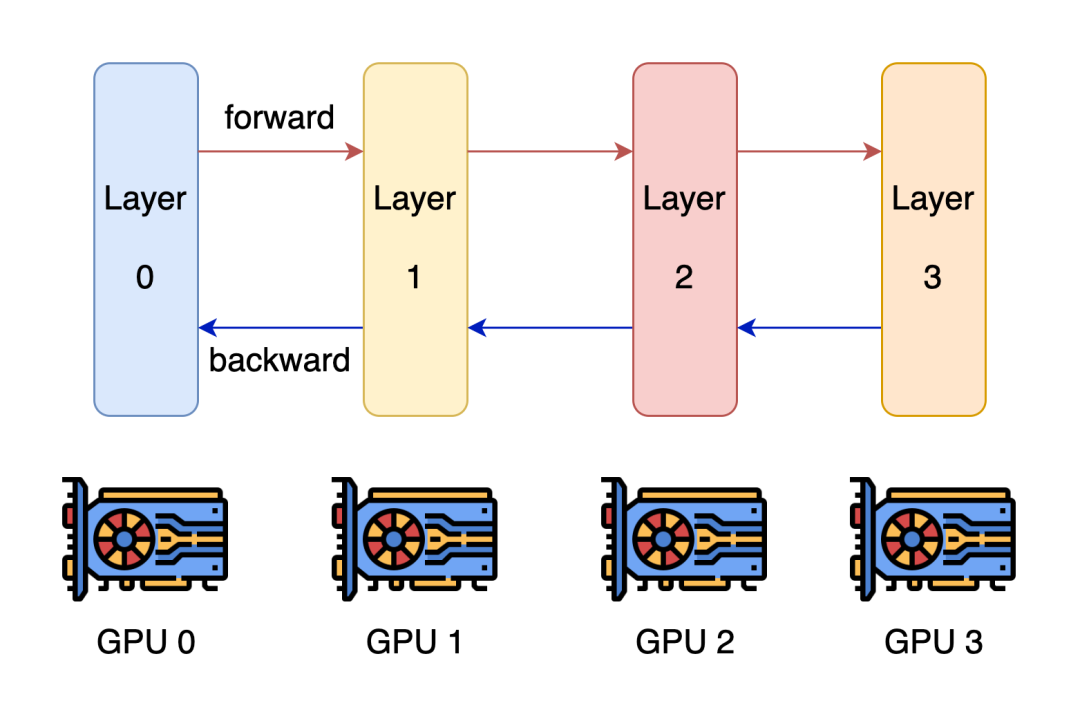
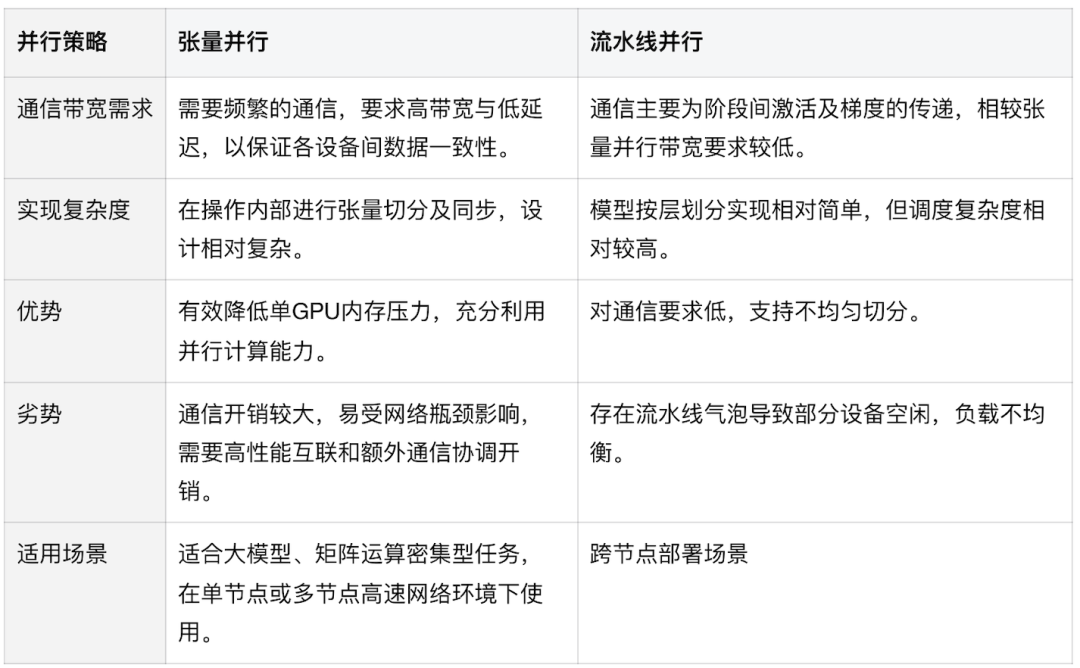
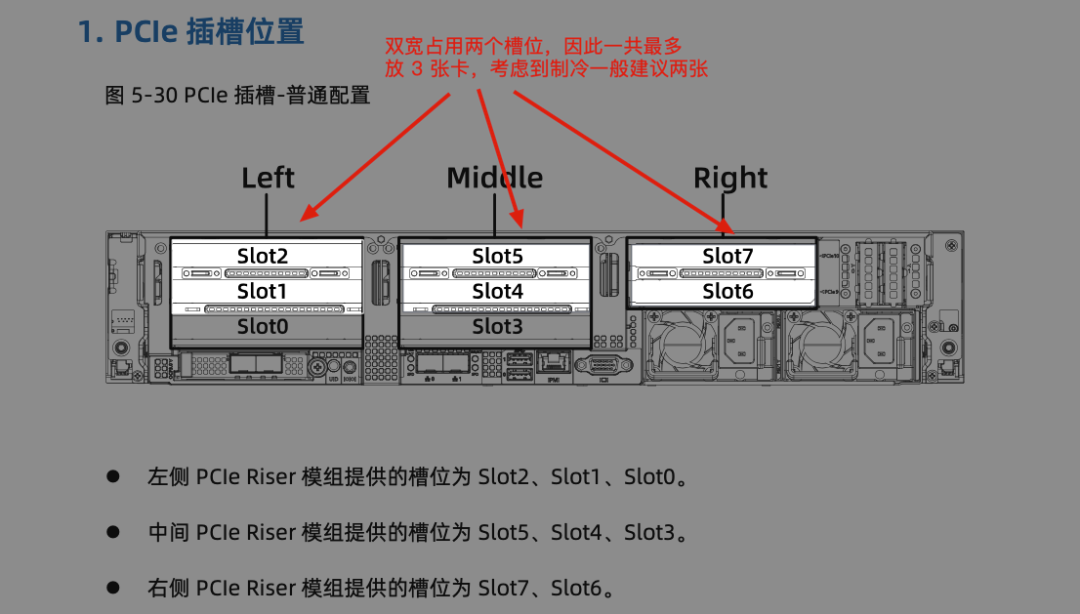
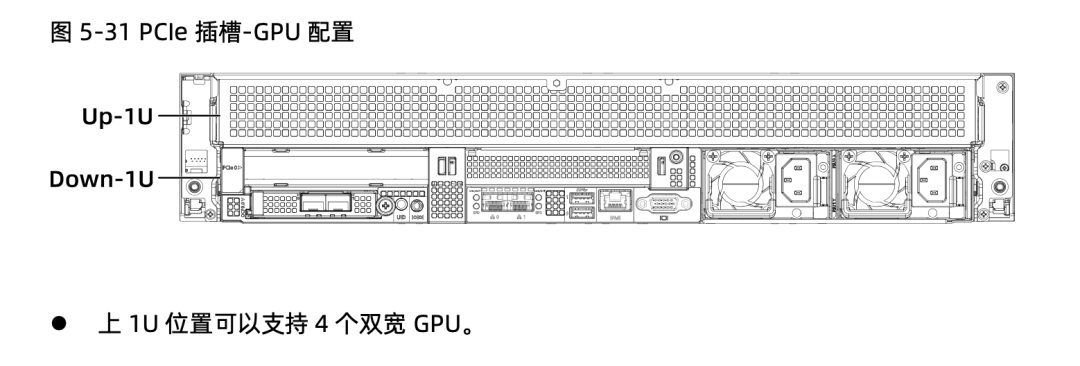
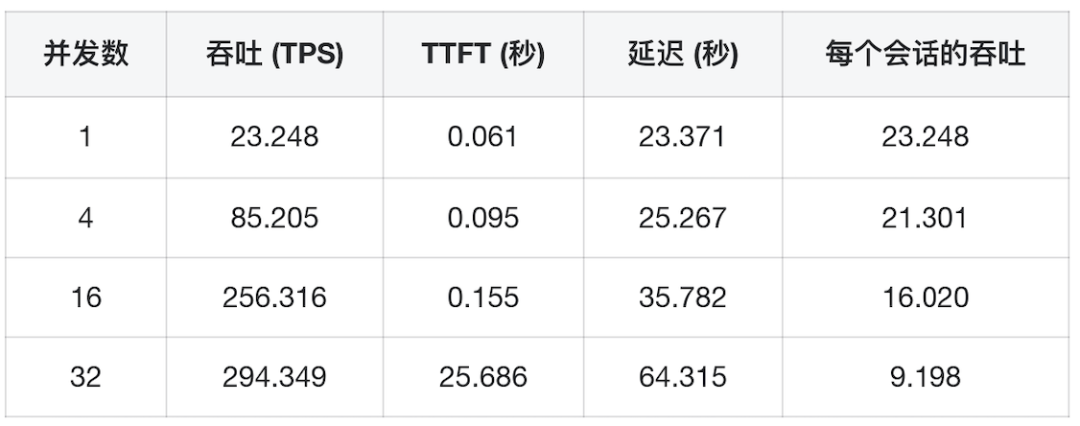
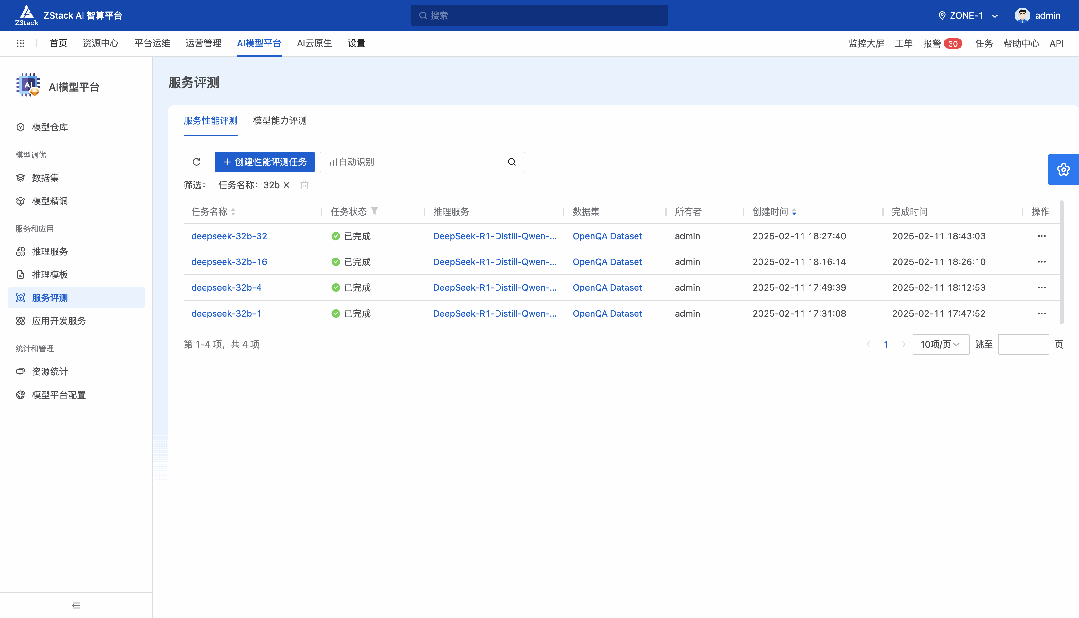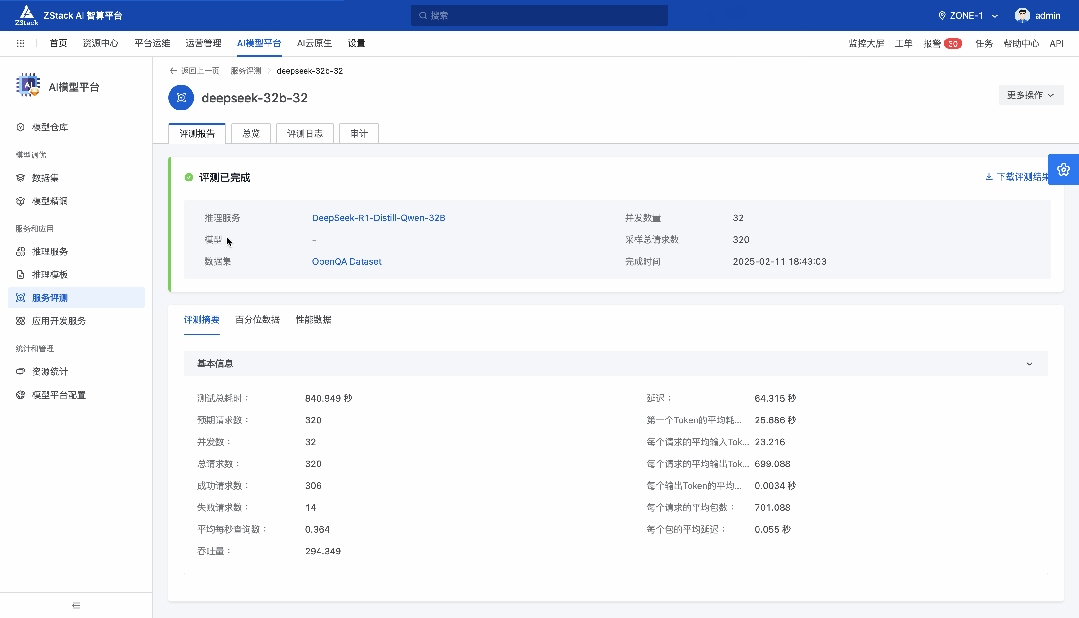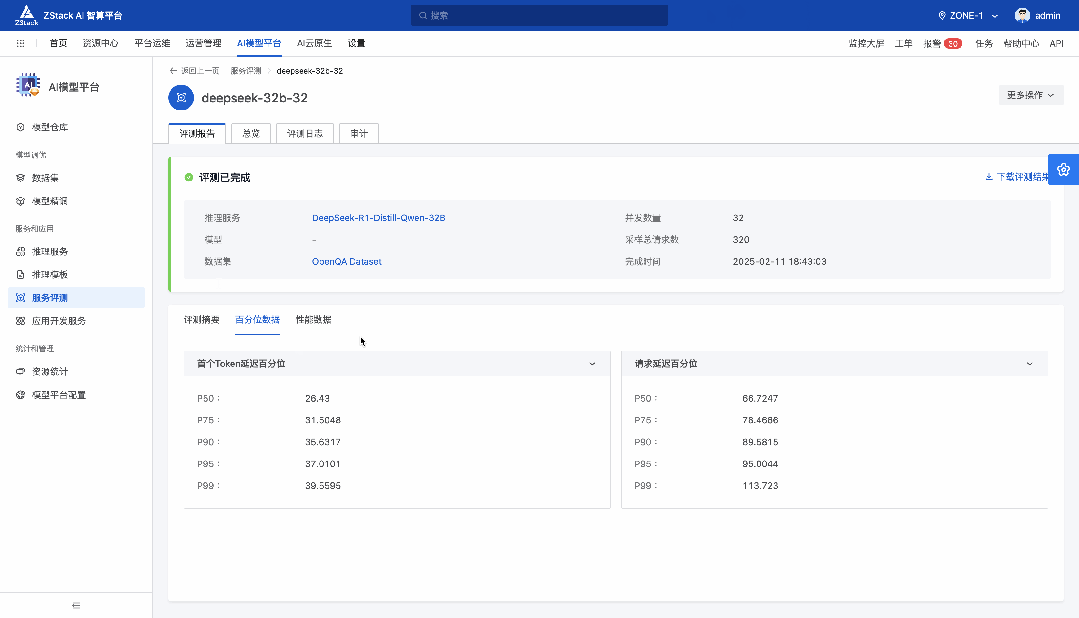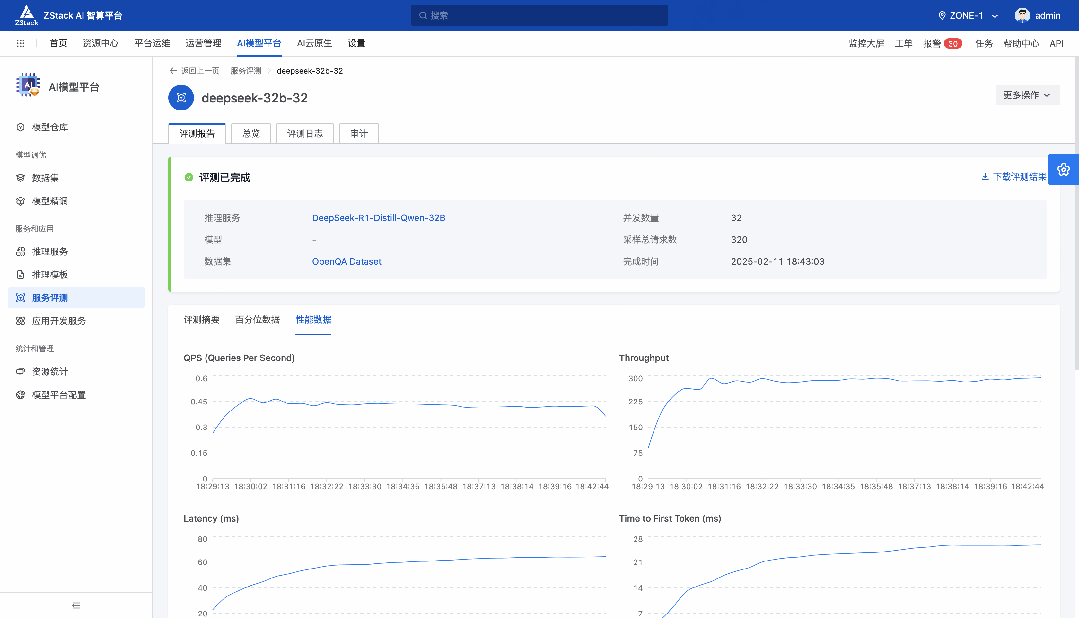
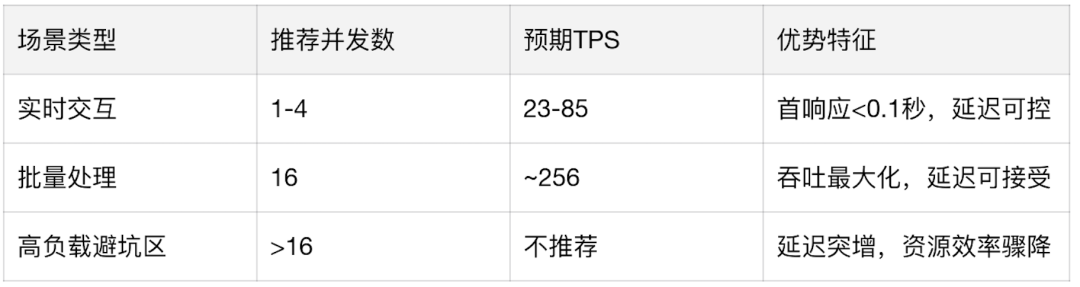
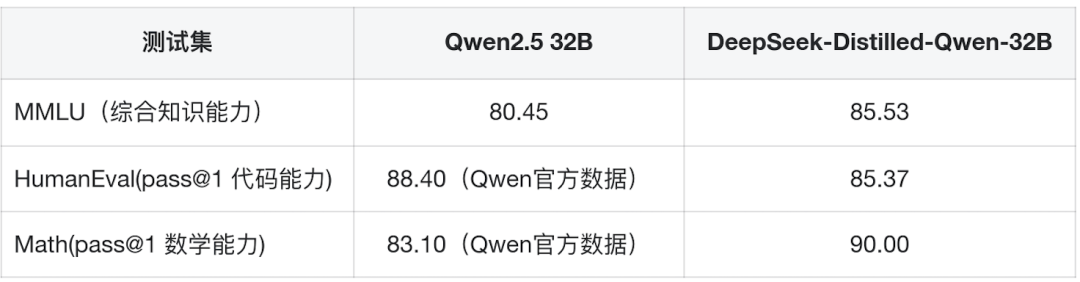
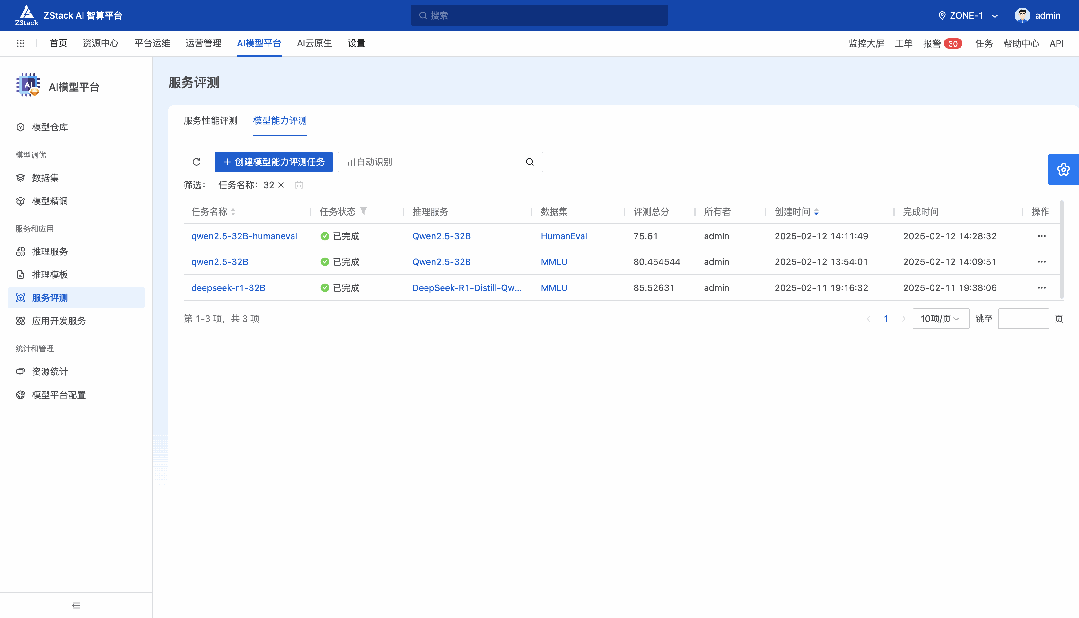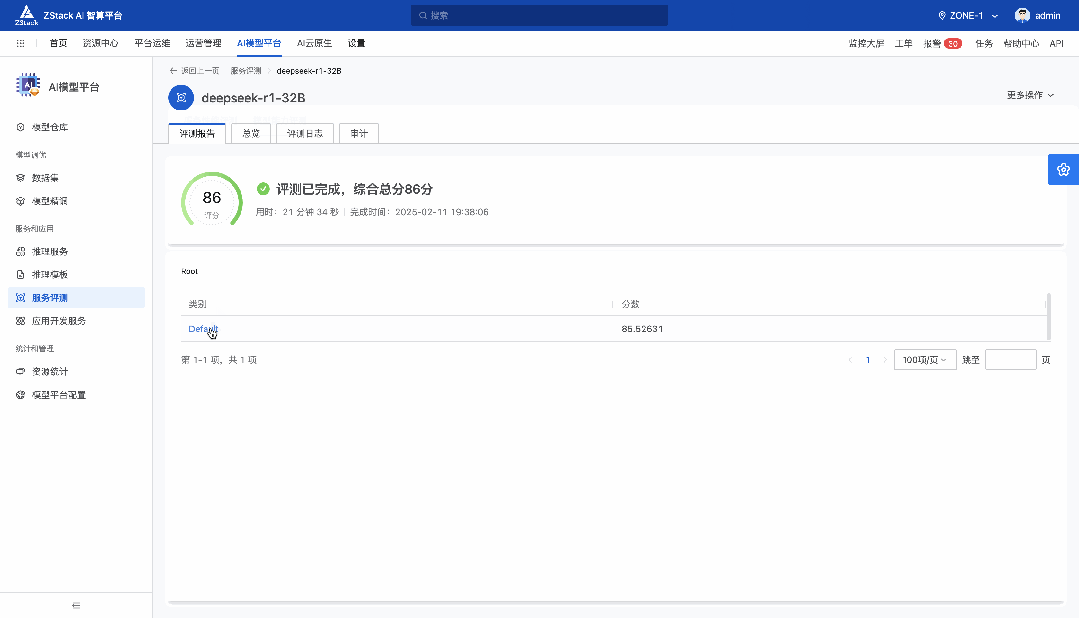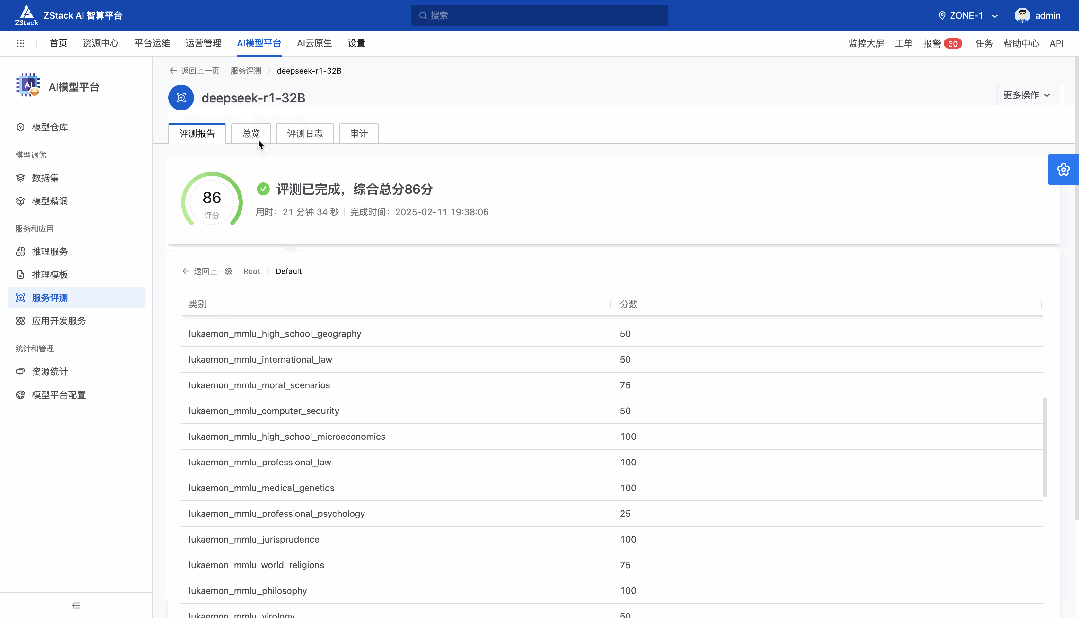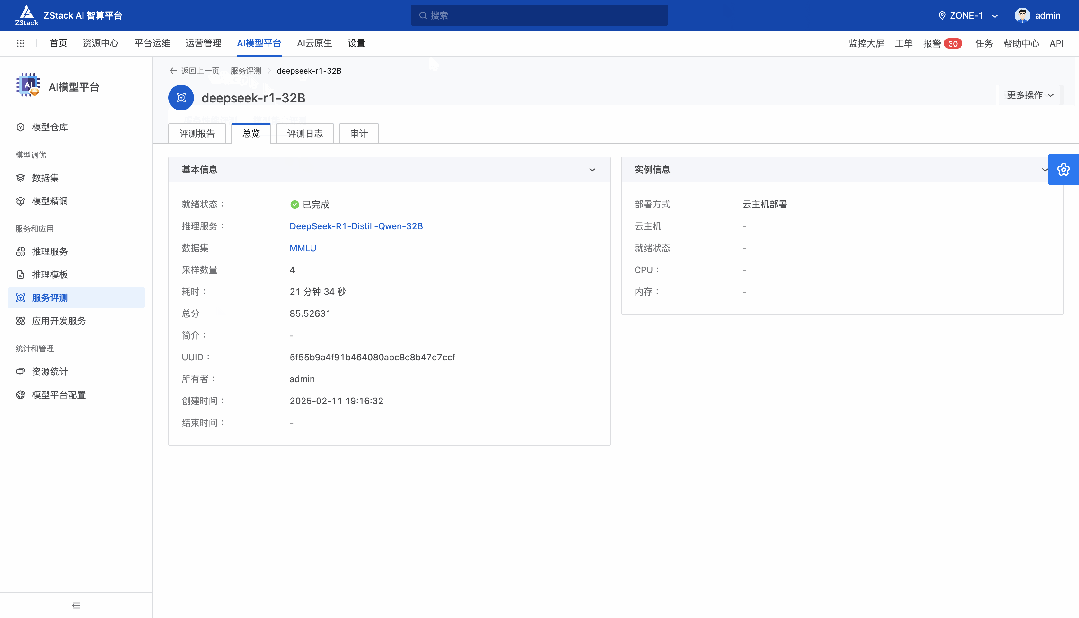
前言 在《深入理解 DeepSeek 与企业实践(一):蒸馏、部署与评测》文章中,我们详细介绍了深度模型的蒸馏、量化技术,以及 7B 模型的部署基础,通常单张 GPU 显存即可满足7B模型完整参数的运行需求。然而,当模型的参数量增长至 32B (320亿) 级别时,单卡显存往往难以支撑其完整运行。这时,我们需要引入多卡并行推理的概念,同时考虑服务器能否支持多卡的硬件架构等问题。 本篇文章将以部署 DeepSeek-Distilled-Qwen-32B 为例,深入探讨多卡并行的原理、服务器多卡硬件部署的注意事项。此外,我们还将对 32B 模型的运行性能、推理能力进行评估,对该模型适合的场景进行分析和建议。 本文目录 一、32B 模型部署所需显存评估 二、多卡推理的原理解析 三、服务器硬件部署与 GPU 配置 四、在 AIOS 智塔上一键部署 DeepSeek-Distilled-Qwen-32B 五、能力评测 : MMLU、HumanEval 等基准测试 六、32B 模型的应用场景与展望 七、展望:更大参数模型的部署策略 一、32B 模型部署所需显存评估 在部署 32B 模型时,不同的精度、上下文长度和 batch size 对显存和算力的需求有着显著影响。其核心影响因素我们在前文有过介绍,这里不再重复介绍而直接给出评估的值: 考虑到现在各种量化方法的复杂性(例如数据打包、FP8 格式量化等等),写 Int8、Int4 已经不太准确,所以在这里简单用 8 位量化、4 位量化 来估计。 此外可能还会因为不同层的量化策略、数据结构的精度、是否开启 KV Cache 量化,或者使用不同的推理框架也可能导致数据存在出入。 二、多卡推理的原理解析 根据前面的计算可以发现当使用很大的上下文、特别是精度比较高的数据精度时,单卡很难满足其显存需求。目前常见的民用卡显存普遍为 24GB 以内,常用的推理卡为 48GB,少数较为高端的 GPU 可以达到 64~141GB 的显存)。 因此,在 32B 及其以上参数的模型服务上,多卡推理基本上是必然选择,目前主要的多卡并行策略包括张量并行(Tensor Parallel)和流水线并行(Pipeline Parallel)。 1. 张量并行(Tensor Parallel) 将单个张量按维度拆分,跨多个 GPU 并行计算相同的操作。 优点:计算和通信可以重叠,提升效率。 缺点:实现复杂度高,对 GPU 间的通信带宽和延时要求较高,需要按 2 的整数次幂如 2、4、8、16 来拆分。 2. 流水线并行(Pipeline Parallel) 将模型的不同层分配到不同的 GPU,上下游 GPU 按序传递激活值,类似生产线的方式。 优点:减少了同步通信的开销,对通信带宽和延迟要求更低。 缺点:可能出现流水线空泡,导致资源浪费。 3. 并行策略对比 根据上面的表格,可以理解为张量并行更有利于提升整体的吞吐,但是流水线并行实现相对简单也适合 CPU、GPU 混合推理的场景,因此 llama.cpp(ollama 所采用的推理引擎)使用了流水线并行,这也是 llama.cpp 的多卡性能相对比较弱的原因。 三、服务器硬件部署与 GPU 配置 1. 2U 服务器安装多 GPU 的挑战 根据前面的内容,我们可以发现服务器安装 GPU 最好是 2 的整数次幂,例如 2、4、8、16 卡,这样可以通过张量并行最好发挥性能,然而对于当前用户常用的 2U 服务器来说,安装 2 张 GPU 一般是没太大问题的,但 4 张 GPU 可能就会存在挑战 如上图,我们常用的 GPU 为双宽尺寸,也就是要占用两个 PCIe 槽位,然而即使我们不考虑其他设备占用槽位的情况,也只能在常见的 2U 服务器上安装三张 GPU,由于不符合 2 的整数次幂,因此只有两张能发挥最大作用。 2. 解决方案 减少前面板硬盘数量:为散热和空间腾出位置,使用大容量硬盘替代多个小容量硬盘。 采用针对安装多 GPU 模组:对于一些服务器厂商,其设计有专门的 GPU 模组,将整个上面 1U 空间留作 GPU 安装,此时可以最多并排放入 4 双宽张 GPU。 此时,我们的前面板需要预留风道散热,因此前面板只能放 8 个 3.5 寸硬盘,需要采用较大容量的硬盘以确保容量充足。 如果希望还有更多的硬盘或者更好的散热的话则需要 3U 或 4U 或更高的服务器了,具体可以结合机柜供电、GPU 功耗来确认最佳方案。 四、在 AIOS 智塔上一键部署 1. 部署步骤 环境配置 部署步骤 环境准备:安装 ZStack AIOS 智塔,确保系统满足运行要求 一键部署: 使用 ZStack AIOS 智塔选择模型并进行加载 指定运行该模型的GPU规格和计算规格后即可部署 测试运行:在体验对话框中可以尝试对话体验或者通过 API 接入到其他应用 2. 性能评估 借助 ZStack AIOS 智塔的性能评测,可以快速对模型在当前硬件上的性能进行评测,数据总结如下: 结合上述评测的结果我们可以对当前环境的情况进行一个分析。 吞吐量(TPS)与并发数的关系 并发数从1提升到16时,TPS呈现显著增长(23→256),但达到32并发时TPS增速大幅放缓(仅提升15%) 推荐并发区间:4-16并发可获得较好的吞吐收益 峰值拐点:当并发超过16时,系统接近性能瓶颈 响应延迟的关键发现 TTFT(首响应时间)在32并发时剧增至25秒(对比1并发时的0.06秒) 总延迟在32并发时超过64秒,是低并发的2.7倍 实时性场景建议:对响应速度敏感的场景(如对话系统)应保持并发≤4 资源效率分析 单并发的会话吞吐为23.248,而32并发时降至9.198(降幅60%) 每个新增会话的边际效益在16并发后明显衰减 资源优化建议:建议通过16并发*多实例部署的方式扩展,而非单实例高并发 不同场景的推荐配置 结合ZStack AIOS 智塔提供的模型评测功能,结合实际环境,更容易得出合适的业务规划和部署模式 注:测试数据显示系统在16并发时达到最佳吞吐/延迟平衡点,超过该阈值后性能劣化明显。实际部署时建议结合硬件资源配置进行压力测试验证。 五、能力评测 : MMLU、HumanEval 等基准测试 1. 测试指标 回答准确率:模型在专业知识问答(MMLU)上的表现,体现模型的综合知识能力。 代码生成能力:在 HumanEval 基准上评测模型的编程能力,代码需要通过编译并通过单元测试。 数学推理能力:在 Math 评测集进行数学推理,体现模型的数学问题理解与推理能力。 2. 评测结果 六、32B 模型的应用场景与展望 32B 模型在多个方面展现出卓越的能力: 推理速度:通过优化,在多卡并行环境下,推理速度得到大幅提升,属于成本与能力较为平衡的推理模型。 数学能力:在复杂计算和公式推导上表现优异。 逻辑推理:能够理解和推理复杂的逻辑关系。 代码生成:具备高质量的代码编写和修正能力,但直接生成大段的完整代码相比更大参数模型会略有不足,更适合代码审查和代码补全。 因此我们总结了 DeepSeek-Distilled-Qwen-32B 可能适合的几种场景: 教学辅助 利用模型的知识储备和理解能力,提供教学内容的辅助讲解、答疑解惑等功能。 代码评审 借助模型的代码理解和生成能力,自动化地对代码进行审查,发现潜在问题,提供优化建议。 特定专业领域应用 在法律、医疗、金融等专业领域,提供高质量的文本生成、知识检索和决策支持。 七、展望:更大参数模型的部署策略 通过本文的探讨,我们深入了解了 DeepSeek-Distilled-Qwen-32B 模型的多卡并行部署方式、硬件配置要求,以及在不同精度和并行策略下的性能表现。32B 模型以其强大的能力,为企业级应用带来了新的可能性。未来,我们期待在更多的实际场景中,见证这类大型模型的价值和潜力。 在后续的文章中,我们将探讨: DeepSeek R1 模型的量化部署:如何在有限资源下部署如 671B 规模的模型。 DeepSeek R1 模型的全精度部署:在高性能计算环境下,如何充分发挥大型模型的能力。 通过对比不同规模和精度的模型,我们希望为企业级应用提供更加全面和细致的部署方案,帮助更多行业快速落地大语言模型技术,实现商业价值。

DeepSeek-Distilled-Qwen-32B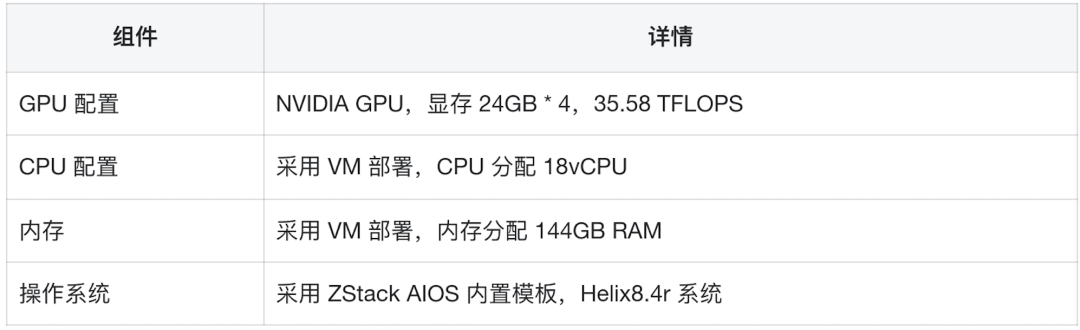
暂无讨论,说说你的看法吧
