

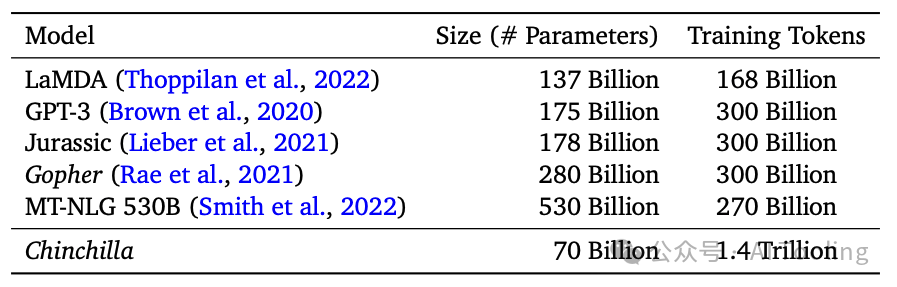
 训练计算优化大型语言模型 (Deepmind)
训练计算优化大型语言模型 (Deepmind)
 多级中间表示 (MLIR)
多级中间表示 (MLIR)

XKCD – 编译
-
仅在必要时分配内存:我们知道从磁盘内存映射大数据(如权重)比将数据复制到 malloc 的块中更有效率。 -
没有哈希或唯一性:我们不要检查 2 GB 数据块的相等性;权重应该通过名称来标识,而不是通过内容来隐式地唯一化。 -
启用内联变异:如果数据只有一个用户,我们应该能够量化、转换和操作数据,而不是先复制它。 -
启用释放:我们正在处理的数据非常庞大,当对数据的最后一个引用被销毁时,我们需要释放它。 -
快速序列化:无论是 JITing、搜索优化参数,还是只是在本地迭代,我们都会出于多种原因缓存 IR,而且它应该很快。
