
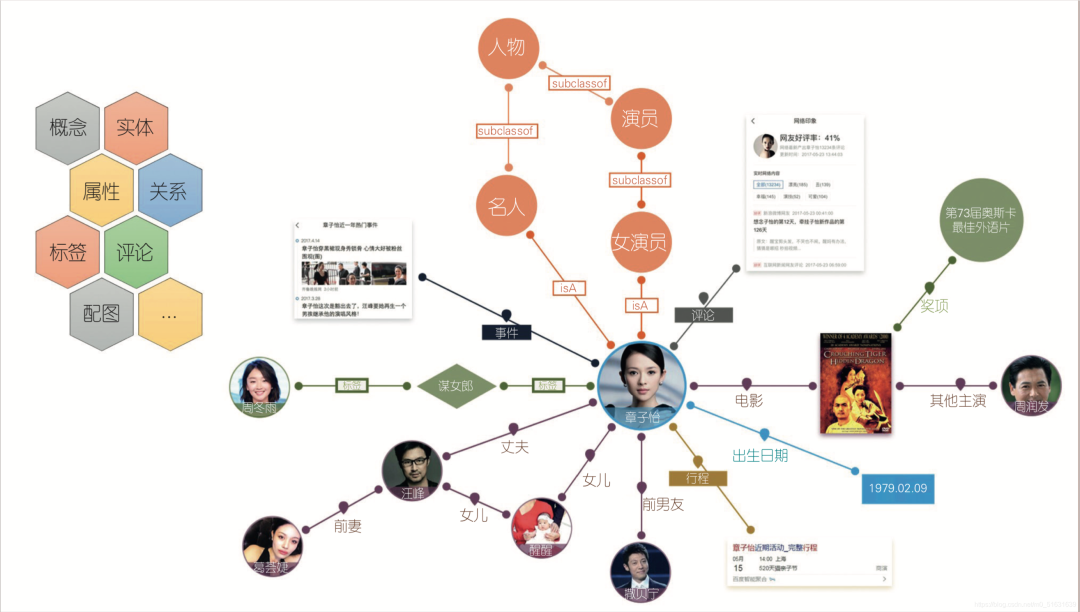
一、知识图谱推理
-
节点:代表现实世界中的实体(如人、地点、事物、概念等),每个实体通常由一个唯一的标识符表示。
-
边:表示这些实体之间的关系。

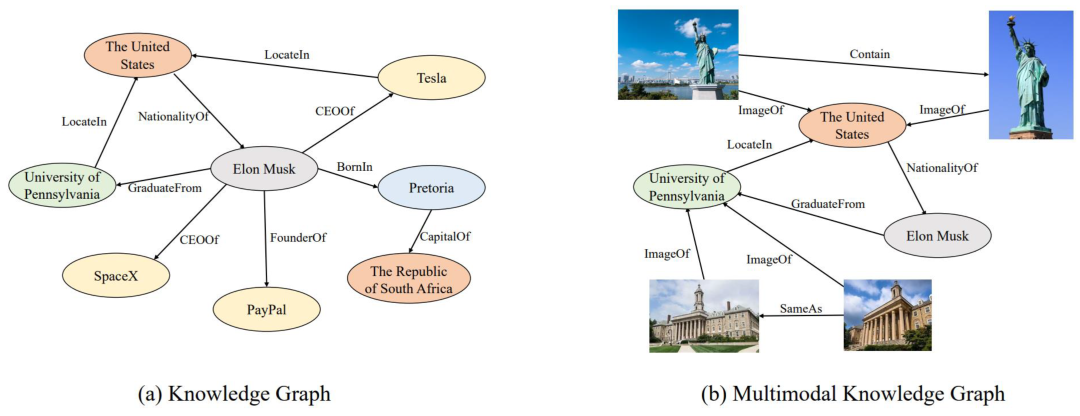
知识图谱推理在多个领域都有广泛的应用,包括但不限于:
1. 企业投资风险研究:通过股权投资关系寻找持股比例最大的股东,辨别由最终控制人操纵的关联交易,洞悉商业风险。
2. 信贷风控:识别贷款申请者之间的异常流水和单位,从而发现风险点。
3. 智能保顾机器人:根据症状、疾病和理赔范围的逻辑去判断保险理赔事宜。
4. 挖掘人物关系:在纪检知识图谱中发现人物之间的异常关联。
5. 问答机器人:基于农业领域知识图谱和逻辑推理模型,使问答对话更加顺畅自然。
6. 动态属性生成:在智能交易中心设置统计值和计算逻辑,实现各节点关系计算结果。
2. 基于归纳的知识图谱推理:通过统计学习方法从数据中归纳出新的模式和关系。
此外,知识图谱推理还包括基于规则的推理、基于分布式表示的推理、基于神经网络的推理和混合推理等方法。下面分别介绍
二、多模态推理任务
多模态推理任务是指利用多种感知模态的信息进行综合分析和判断的过程。多模态推理涉及至少两种不同的感知模态,最常见的是视觉和语言。这两种模态的信息可以是图片和文本、视频和语音等。多模态推理的目标是从不同模态的信息中获取更全面、更准确的理解和知识,以支持各种任务,包括视觉问答、视觉常识推理、视觉语言导航等。

1. 人机交互:通过结合语音、图像和文本等多种输入方式,提高人机交互的自然性和效率。
2. 机器人控制:在机器人技术中,多模态模型可以帮助机器人更好地理解和响应复杂的环境输入。
3. 多模态情感分析:充分利用多个模态数据中的情感信息,提高情感分析的水平。
4. 多模态事件检测:检测不同模态数据中发生的事件,并对事件进行分类和定位。
5. 多模态生成任务:生成具有多个模态的数据,比如文本和图像的生成、音频和视频的生成等。
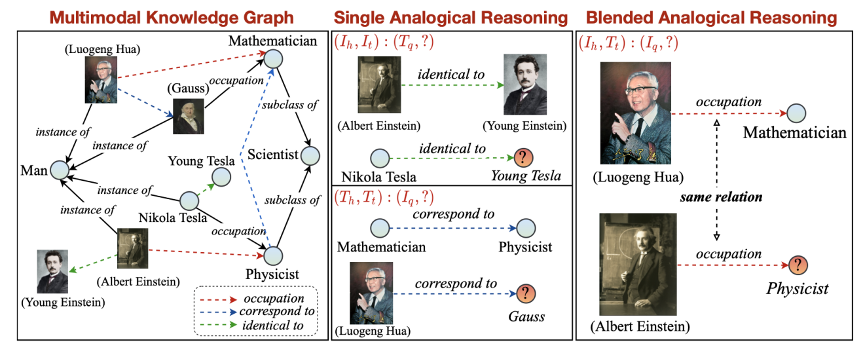
多模态推理的技术手段包括:
1. 表示学习:将不同模态的数据转换为统一的特征表示,使得模型能够同时处理和理解这些模态。
2. 对齐(Alignment):研究不同模态元素间的对齐关系,包括显式对齐和隐式对齐。
3. 融合(Fusion):整合来自不同模态的特征信息,以提高模型的决策能力。
4. 协同推理(Cooperative Reasoning):不同模态的信息协同工作,共同支持复杂任务的推理过程。
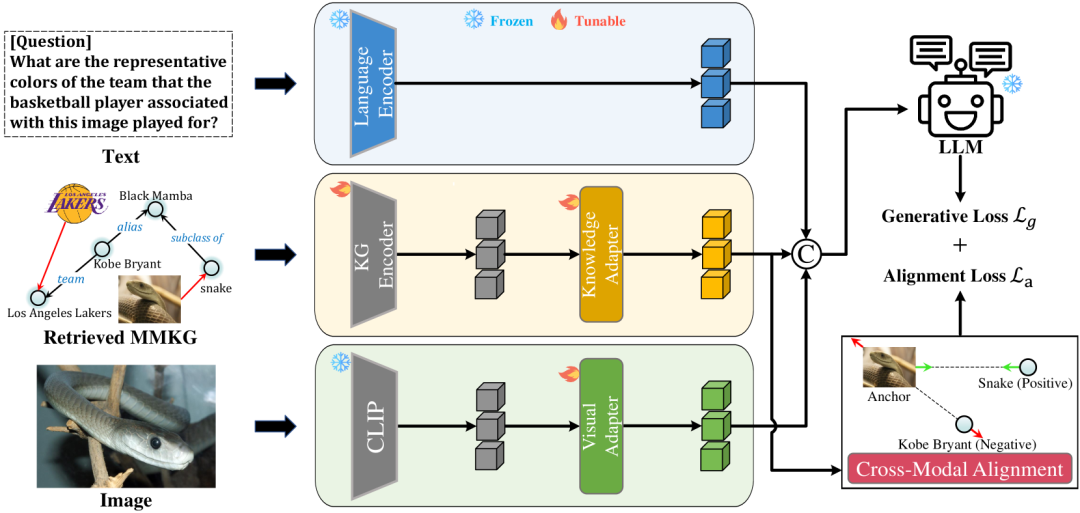
视觉问答(Visual Question Answering,VQA)
-
VQA是一个典型的多模态问题,融合了计算机视觉(CV)与自然语言处理(NLP)的技术,计算机需要同时学会理解图像和文字。
-
为了回答某些复杂问题,计算机还需要了解常识,并基于常识进行推理(common-sense resoning)。
二、视觉常识推理(Visual Commonsense Reasoning,VCR)
视觉常识推理需要在理解文本的基础上结合图片信息,基于常识进行推理。给定一张图片、图中一系列有标签的bounding box,VCR实际上包含两个子任务:{Q->A}根据问题选择答案;{QA->R}根据问题和答案进行推理,解释为什么选择该答案。
-
VCR数据集由大量的“图片-问答”对组成,主要考察模型对跨模态的语义理解和常识推理能力。
-
预训练任务可能包括将BERT经典的MLM和NSP预训练任务扩展到多模态场景等。
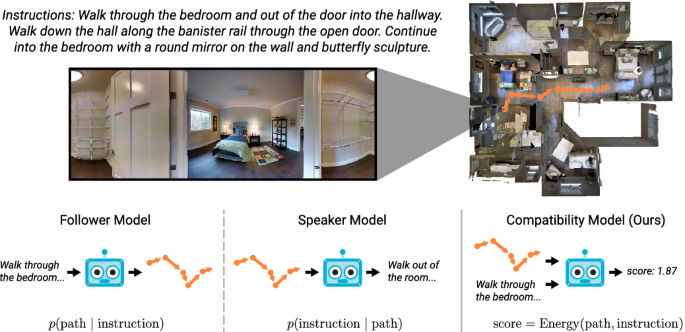
三、视觉语言导航(Vision Language Navigation)
视觉语言导航是一种技术,它结合了计算机视觉、自然语言处理和自主学习三大核心技术,使智能体能够跟随自然语言指令进行导航。
-
智能体不仅能够理解指令,还能理解指令与视角中可以看见的图像信息。
-
智能体需要在环境中对自身所处状态进行调整和修复,最终做出对应的动作,以达到目标位置。
多模态AI的实际应用
多模态AI已经在多个领域展现了强大的潜力,以下是一些实际应用的案例:
NO.01
医疗领域
多模态AI在医疗中的应用非常广泛,尤其是在医疗影像分析、病历记录整合等方面。通过将医学影像(如CT扫描、MRI等)和患者的文字病历数据结合,AI能够为医生提供更准确的诊断建议。这种多模态整合可以极大提升医生的诊断效率,减少误诊率。
NO.02
智能家居
多模态AI在智能家居中的应用非常广泛,尤其是在影像分析、IoT记录整合等方面。通过将影像(如CT扫描、MRI等)和者的文字数据结合,AI能够为医生提供更准确的设备连接建议。这种多模态整合可以极大提升家居的诊断效率,减少误诊率。
NO.03
虚拟助手
多模态AI使得虚拟助手变得更加智能,能够同时处理语音、文字和图像。未来的虚拟助手可能不只是听你说话,它们还能够“看”到你展示的图片或视频。例如,你可以向虚拟助手展示一个视频,询问它某个场景的详细情况,虚拟助手能快速理解并给出答案。
NO.04
教育与内容创作
多模态AI可以根据图像生成详细的文字描述,或者根据给定的文字生成相关的图像和视频。这种能力在教育领域特别有用,教师可以使用AI生成跨模态的教育材料,学生则可以更直观地理解复杂的概念。
多模态AI的未来与挑战多模态AI在开发和应用过程中面临多种挑战,但这些挑战也为未来的发展提供了机遇和方向未来研究方向包括:
2. 跨模态语义对齐:改善不同模态之间的语义对齐,以实现更准确的多模态信息整合。
3. 多模态AI的五大研究方向:包括视觉理解、视觉生成、统一视觉模型、LLM支持的多模态大模型、多模态Agent等。
多模态推理作为人工智能领域的一个重要分支,正不断发展和进步,其在实现更智能、更全面的交互系统方面具有巨大潜力。
