

01。
概述
02。
性能改进的背景
03。
v0.2.0版本的性能提升
-
动态SIMD指令集检测:得益于highway库的动态调度特性,Vectorlite现在可以在运行时检测到最佳可用的SIMD指令集。这意味着,即使是在向量维度较小(<=128)的情况下,Vectorlite也能保持高效的性能,尽管会有一点点运行时开销。 -
向量距离实现的优化:在我的PC上(支持AVX2的i5-12600KF Intel CPU),当向量维度较大(>=256)时,Vectorlite的向量距离实现比hnswlib的实现快1.5倍至3倍。这一提升主要得益于Vectorlite能够充分利用AVX2的Fused-Multiply-Add操作。然而,当向量维度较小(<=128)时,Vectorlite的速度略慢于hnswlib,这是由于动态调度的成本。 -
ARM平台的SIMD加速:在ARM平台上,Vectorlite现在也支持SIMD加速,这是以往版本所不具备的。 -
向量归一化的加速:向量归一化现在保证是SIMD加速的,比标量实现快4倍至10倍,这对于使用余弦距离的向量搜索任务尤为重要。
04。
E2E基准测试
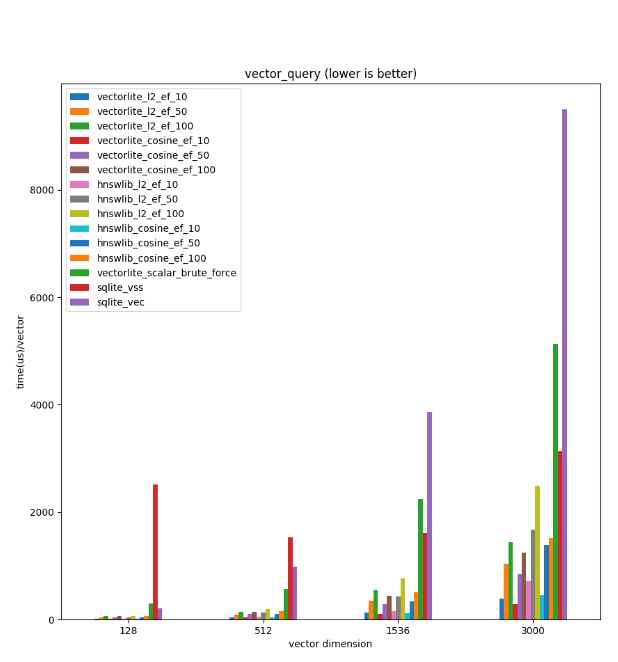
05。
结论
-
支持向量标量量化 -
在更大的数据集上进行基准测试 -
支持用户提供的元数据(rowid)过滤器
