

一、引言:RAG 技术的兴起和挑战
1.1、从关键词搜索到 RAG
1.1、从关键词搜索到 RAG
1.2、现有 RAG 框架存在的问题
-
部署和维护的复杂性: 许多 RAG 框架缺乏对生产环境的优化,部署和维护一个完整的 RAG 系统需要开发者具备专业的知识和技能,例如配置向量数据库、管理语言模型等。 -
缺乏灵活性和可定制性: 许多框架只提供了固定的功能模块,开发者难以根据实际需求进行定制化开发,例如支持不同的数据源、语言模型或向量数据库。 -
查询服务部署:从查询生成答案的代码需要包装在 API 服务器中,并部署为可扩展的服务,该服务可以处理多个并发查询并随着流量自动扩展,目前还没有此类内置支持。 -
语言模型和嵌入模型部署:RAG 框架中缺乏真正的生产级支持,其中模型作为单独的服务托管,并通过 API 调用。 -
向量数据库部署:RAG 框架应考虑提供内置支持,以更具可扩展性和可靠性的方式部署数据库。 -
缺乏端到端的完整解决方案: 一些框架只关注 RAG 流程中的某些部分,例如检索或生成,缺乏将整个流程整合起来的完整解决方案,开发者需要自行拼凑不同的工具和库。 -
用户体验不佳: 许多框架缺乏用户友好的界面和工具,难以与非技术人员进行协作和交互。
二、Cognita:解决 RAG 痛点的利器
2.1、什么是 Cognita
2.1、什么是 Cognita
2.2、Cognita 的优势
2.2、Cognita 的优势
-
全面性: 提供从数据加载、解析、嵌入到查询和响应生成的完整 RAG 流程,无需拼凑不同的工具和库。 -
模块化: 将 RAG 流程分解为可插拔的组件,方便开发者根据需求进行定制和扩展,例如使用不同的数据源、语言模型、向量数据库等。 -
易用性: 提供用户友好的界面,方便非技术人员上传文档、执行问答等操作,降低了 RAG 技术的使用门槛。 -
面向生产环境: 支持批量索引、增量索引等特性,能够高效处理海量文档,并保证系统的稳定性和可扩展性。
2.3、Cognita 如何解决这些问题
2.3、Cognita 如何解决这些问题
-
模块化架构: 将 RAG 流程分解为一系列可插拔的模块化组件,开发者可以根据需求自由选择和组合不同的组件,例如数据加载器、解析器、嵌入器、向量数据库等,轻松实现定制化开发。 -
简化部署和维护: Cognita 对各个组件进行了高度抽象和封装,并提供了多种部署方式,简化了 RAG 应用的部署和维护流程,降低了开发者的技术门槛。 -
简化的部署:Cognita 抽象了在生产中部署 RAG 系统的复杂性,处理诸如分块和嵌入作业、查询服务部署、语言模型托管和向量数据库管理等任务。 -
提供端到端的完整解决方案: Cognita 涵盖了 RAG 流程的各个环节,从数据加载、解析、嵌入到查询和响应生成,提供了一个完整的解决方案,开发者无需自行拼凑不同的工具和库。 -
优化面向生产环境的性能和稳定性: Cognita 支持批量索引、增量索引等特性,能够高效处理海量数据,并提供了多种部署方式,以满足不同场景的需求。 -
提升用户体验: Cognita 提供了用户友好的界面和工具,方便开发者与非技术人员进行协作和交互,例如上传文档、执行问答等操作。
2.4、Cognita 架构概览
2.4、Cognita 架构概览
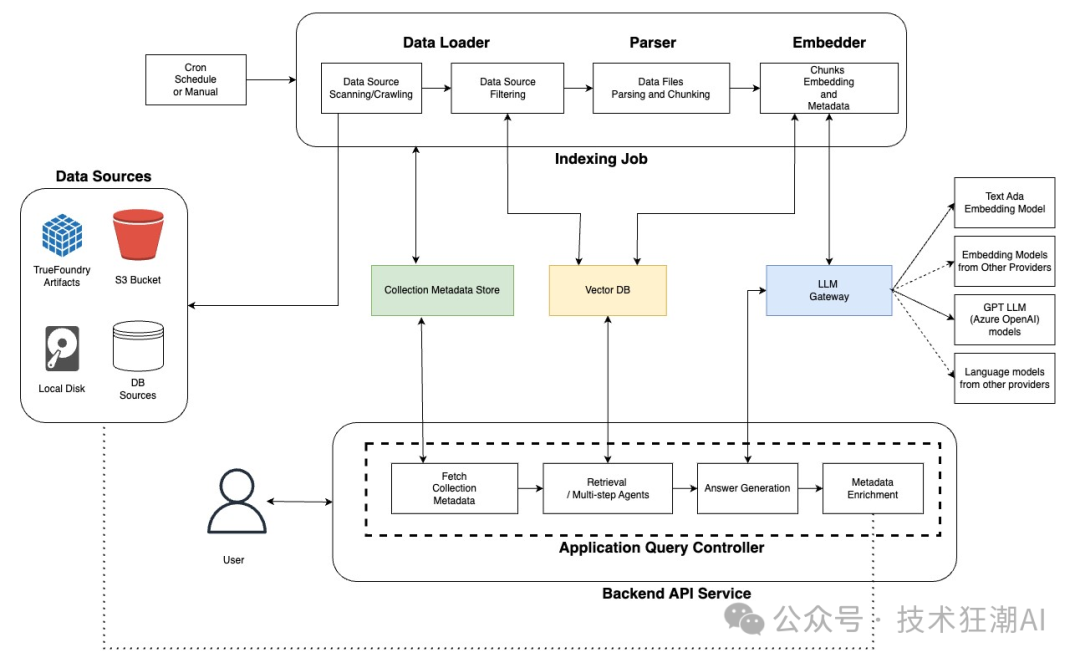
-
数据源:指文档所在的位置,例如计算机硬盘、云存储或内部数据库。 -
元数据存储:类似于图书馆目录,用于跟踪有关文档集合的信息。它会记录集合名称、文档存储位置以及用于分析的所选嵌入模型等详细信息。 -
LLM 网关(可选):充当于来自不同提供商的各种大语言模型 (LLM) 和嵌入模型交互的中心枢纽。您可以将其视为一个通用翻译器,允许 Cognita 与不同的 AI 服务进行无缝通信。 -
向量数据库:这个高性能数据库存储由分析器生成的文档嵌入。它允许 Cognita 根据用户查询有效地检索相关文档。您可以将其视为一个超级强大的搜索引擎,它可以根据含义和上下文(而不仅仅是关键字)查找信息。 -
索引作业:在后台运行,自动处理您的文档。它从数据源检索文档、分析它们、创建嵌入,并将它们存储在向量数据库中。 -
API 服务器:系统的核心。它接收用户查询,与其他组件交互以查找相关信息,并使用 LLM 网关(如果适用)生成响应。
三、Cognita 实战:快速构建问答系统
-
准备文档:将您希望 Cognita 分析的文档整理到集合中(例如,研究论文、客户电子邮件)。 -
索引:Cognita 会自动完成索引过程。它会分析您的文档、创建嵌入,并将它们存储在向量数据库中。这可能需要一些时间,具体取决于集合的大小。 -
提出您的问题:索引完成后,您可以通过用户界面或 API 与 Cognita 交互。只需提出您的问题,Cognita 就会搜索您的文档,检索最相关的信息,并提供一个经过深思熟虑的答案。
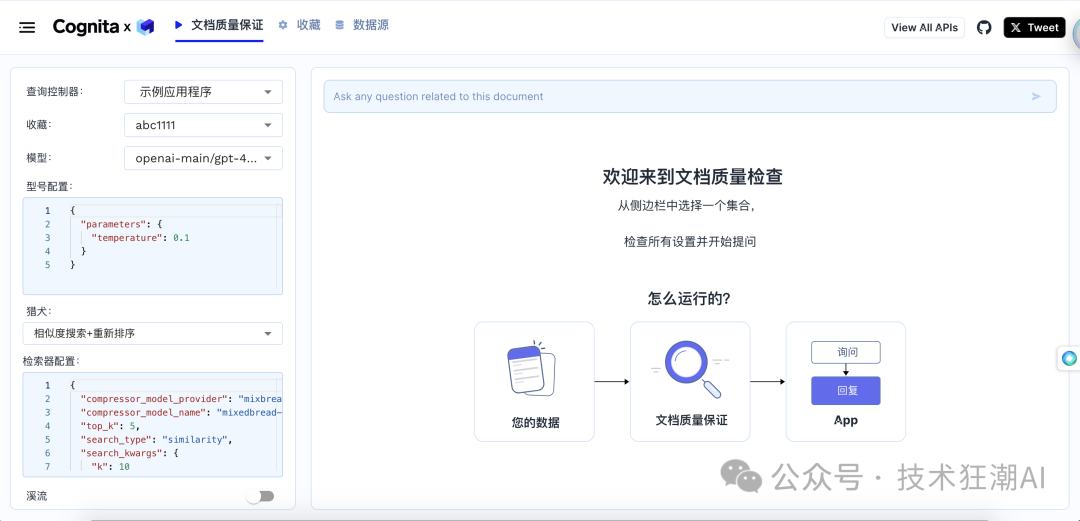
-
创建数据源: 上传包含您领域知识的 PDF 文档。
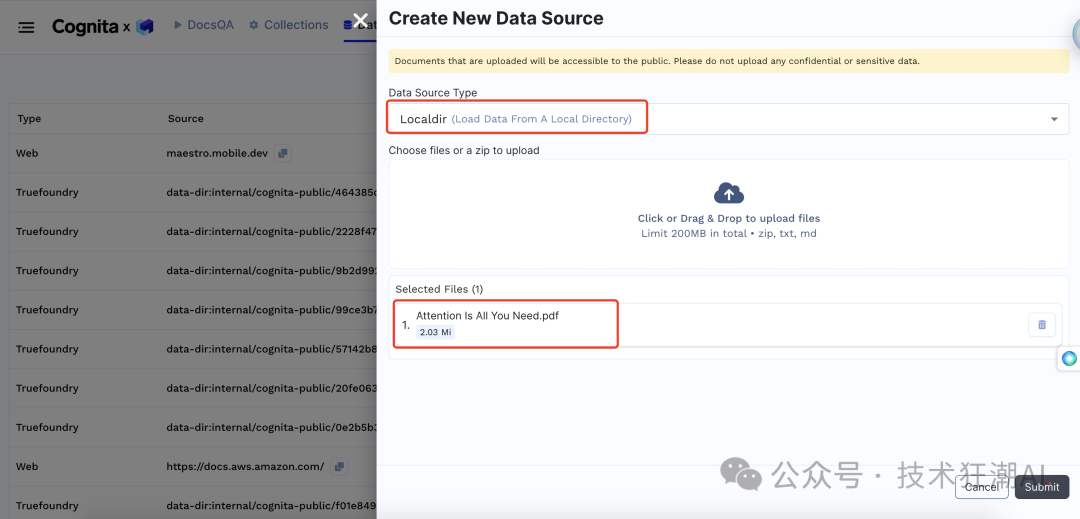
-
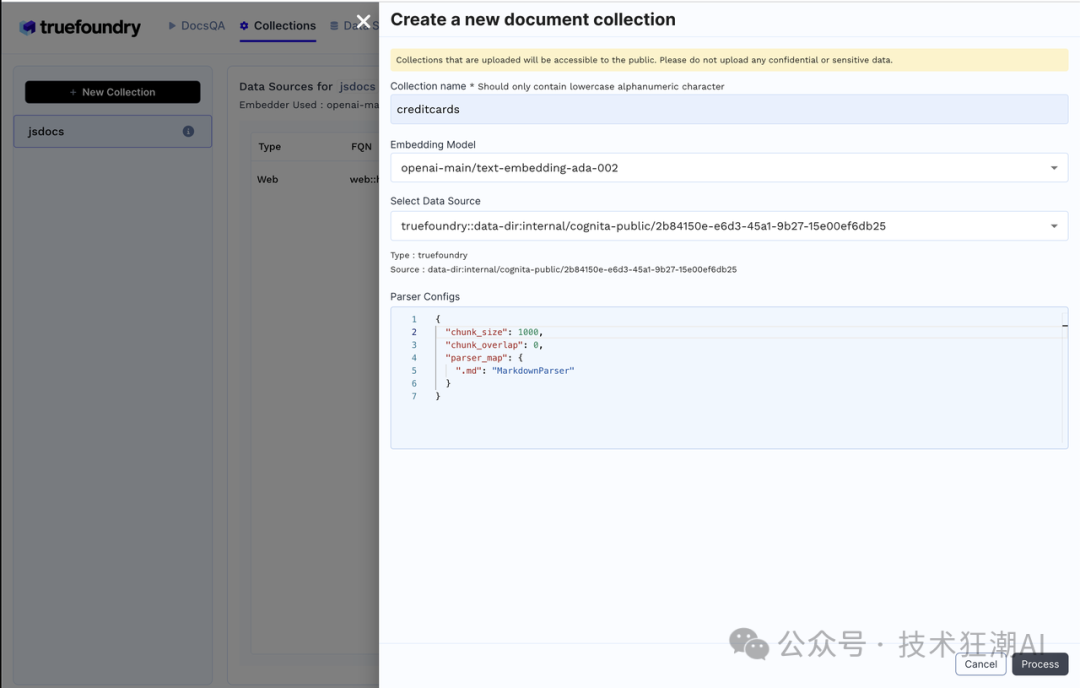
创建集合: 选择合适的嵌入模型,例如 openai-main/text-embedding-ada-002,并将数据源添加到集合中。点击 "Process" 按钮,Cognita 会自动完成文档解析、嵌入和索引。
-
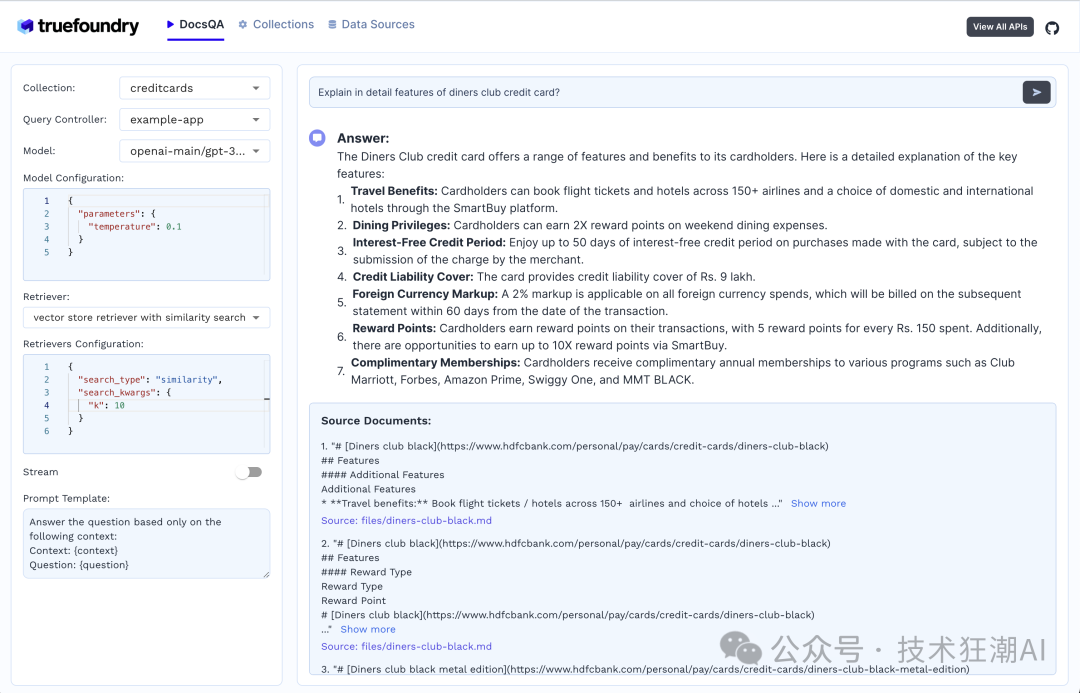
进行问答: 在 "Query" 界面,输入您的问题,例如 "when layer type is Convolutional, what is the Maximum Path Length?",并选择合适的语言模型和检索器。点击 "Generate" 按钮,Cognita 会返回基于您文档的答案。
四、Cognita 部署
-
本地部署:直接在您自己的机器上运行 Cognita,以用于私有用例。 -
云部署:利用 TrueFoundry 的云平台轻松部署和管理您的 Cognita 实例。这对于需要可扩展性和协作的场景非常理想。
五、总结
