
从收藏不看到搜索不到:为什么知识管理总是死循环?
我自己被这个问题困扰好久了:
-
读了很多文章,但跟人聊起相关内容还是说不清楚,感觉啥都没记住 -
收藏夹攒了几百条"稍后看",归档速度跟不上收藏速度 -
笔记软件堆了几千条笔记,真要用的时候搜半天也找不到能用的内容
每天要忙的事实在太多了,分给定期整理乱知识库的时间太少了?通常剪藏俩礼拜,整个库就乱成垃圾堆,有时候连打开整理的勇气都没有。
还好赶上AI这波技术革命,终于有不用自己当苦力的知识管理模式了。
以前大家搞知识管理基本都是死循环:读一篇文章 → 点收藏 → 需要时搜索 → 重新从头到尾读一遍。等于每次都要从原始材料里重新挖信息,啥沉淀都留不下。
Andrej Karpathy 在 2026 年 4 月提出了一个更聪明的模式——LLM Wiki Pattern。他的核心洞察特别戳人:
AI知识库应该是结构化、可迭代、持久化,不是每次查问题的时候才临时凑出来的零散碎片。
说人话就是:你看过的内容AI会提前帮你整理好重点、串清楚关联,永久存到知识库里,下次要用直接拿,不用每次问问题都得把之前的原文翻出来重新读一遍重头捋。
这就是本文要分享的内容:如何用大模型构建一个真正能用起来的个人知识库,不用自己天天整理,AI帮你把脏乱差的知识库理得明明白白。
TL;DR:
技术栈: OpenClaw + SearXNG + crawl4ai + Obsidian + Gitea (NAS Self-hosted)
这套方法,我用了一周后的样子
1. 方法论:LLM Wiki Pattern
1.1 核心思想
传统的 RAG(检索增强生成)模式是这样的:
用户提问 → 检索原始文档 → LLM 拼凑答案 → 答案用完就丢
每次问答都是从零开始,没有任何积累。LLM 每次都要找并拼凑相关片段,但什么都留不下。
Wiki 模式完全不同:
用户提问 → LLM 基于已有 Wiki 回答 → Wiki 持续更新扩充 → 越积累越丰富
知识编译一次,然后保持最新。跨引用已经存在,矛盾已被标记,综合内容已反映你读过的所有内容。每添加一个源,Wiki 就变得更丰富。
1.2 三层架构
Karpathy 提出了经典的三层架构:

三层职责:
|
|
|
|
|---|---|---|
| Raw Sources |
|
|
| Wiki |
|
|
| Schema |
|
|
类比:
-
Obsidian = IDE -
LLM = 程序员 -
Wiki = 代码库
1.3 两种知识库的对比
|
|
|
|
|---|---|---|
| 知识形态 |
|
|
| 累积性 |
|
|
| 矛盾处理 |
|
|
| 维护成本 |
|
|
| 适合场景 |
|
|
1.4 Wiki 模式的操作流程
Ingest(摄取):把新源丢到 raw 集合,告诉 LLM 处理它
-
LLM 读取源 -
与你讨论关键要点 -
在 wiki 写摘要页 -
更新索引 -
更新相关实体和概念页 -
添加日志条目
单个源可能涉及 10-15 个 wiki 页面。
Query(查询):针对 wiki 提问
-
LLM 搜索相关页面、读取、合成答案并引用 -
答案可以是 markdown、比较表、幻灯片、图表 -
好答案可以归档回 wiki 作为新页面
Lint(检查):定期让 LLM 做健康检查
-
页面间的矛盾 -
被新源取代的陈旧主张 -
没有入站链接的孤立页面 -
缺失的交叉引用
1.5 应用场景
这个模式可以应用到很多场景:
|
|
|
|
|---|---|---|
| 个人成长 |
|
|
| 深度研究 |
|
|
| 读书 |
|
|
| 团队/商业 |
|
|
| 竞品分析 / 尽职调查 / 旅行规划 / 课程笔记 |
|
|
1.6 两种导航文件
随着 wiki 增长,两个特殊文件帮助 LLM(和你)导航:
index.md(内容导向)
-
wiki 的目录——每个页面列出链接、一行摘要、可选元数据(日期、来源数) -
按类别组织(实体、概念、来源等) -
LLM 每次摄取时更新 -
回答查询时,LLM 先读索引找相关页面,再深入阅读 -
在中等规模(~100 来源、~数百页面)下效果出奇好,不需要 RAG 基础设施
log.md(时间顺序)
-
只追加的操作记录——摄取、查询、lint -
每条以一致前缀开头(如 ## [2026-04-02] ingest | Article Title) -
可用简单 unix 工具解析: grep "^## [" log.md | tail -5 -
日志是 wiki 演进的时间线,帮助 LLM 理解最近做了什么
1.7 Obsidian 技巧
Obsidian Web Clipper:浏览器扩展,将网页文章转为 markdown,快速将来源加入 raw 集合。
图片本地化:设置 → 文件和链接 → 附件文件夹路径设为 raw/assets/,绑定热键(Ctrl+Shift+D)下载所有图片。LLM 可以直接查看和引用本地图片,而不是依赖可能失效的 URL。
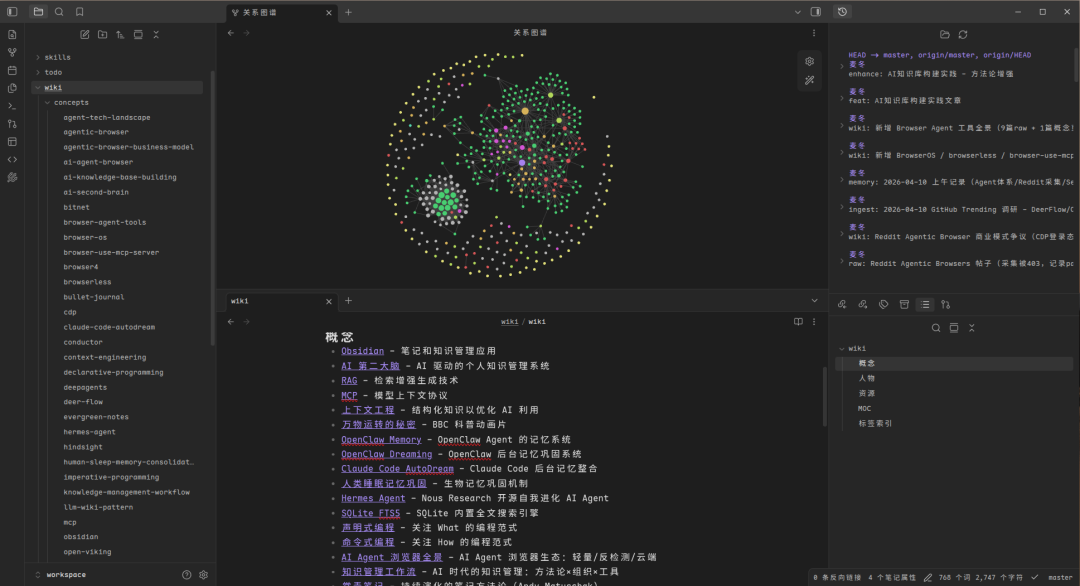
Graph View:查看 wiki 的形状——哪些页面互联了、谁是中心页面、谁是孤立页面。
Marp:基于 markdown 的幻灯片格式,Obsidian 有插件,可以直接从 wiki 内容生成演示文稿。
Dataview:对 frontmatter 运行查询的插件,如果 LLM 添加了 YAML frontmatter(标签、日期、来源数),Dataview 可以生成动态表格和列表。
1.8 可选 CLI 工具
当 wiki 增长时,你可能需要一些小工具帮助 LLM 更高效地操作 wiki:
qmd:本地 markdown 搜索引擎,混合 BM25/向量搜索 + LLM 重排,全部本地运行。有 CLI(LLM 可以调用)和 MCP 服务器(作为原生工具)。
自己 vibe-code 一个简单搜索脚本也是可以的——LLM 可以帮你快速搭建。
1.9 为什么 LLM 维护 Wiki 是革命性的
维护知识库繁琐的部分不是阅读或思考——是记账(bookkeeping):
-
更新交叉引用 -
保持摘要最新 -
注意新数据何时与旧主张矛盾 -
维护数十个页面间的一致性
人类放弃 wiki 是因为维护负担增长快于价值。
LLM 不会无聊、不会忘记更新交叉引用、一次可以触及 15 个文件。维护成本接近零。
-
人类的工作:管理源、指导分析、提出好问题、思考一切意味着什么 -
LLM 的工作:其他一切
1.10 与 Vannevar Bush Memex 的关系
这个想法在精神上与 Vannevar Bush 的 Memex(1945) 相关——一种个人策划的知识存储,文档间有关联 Trails。Bush 的愿景更接近这个而非 Web 变成的样子:私人、积极策划,文档间的连接与文档本身一样有价值。
他无法解决的部分是谁来维护。LLM 解决了。
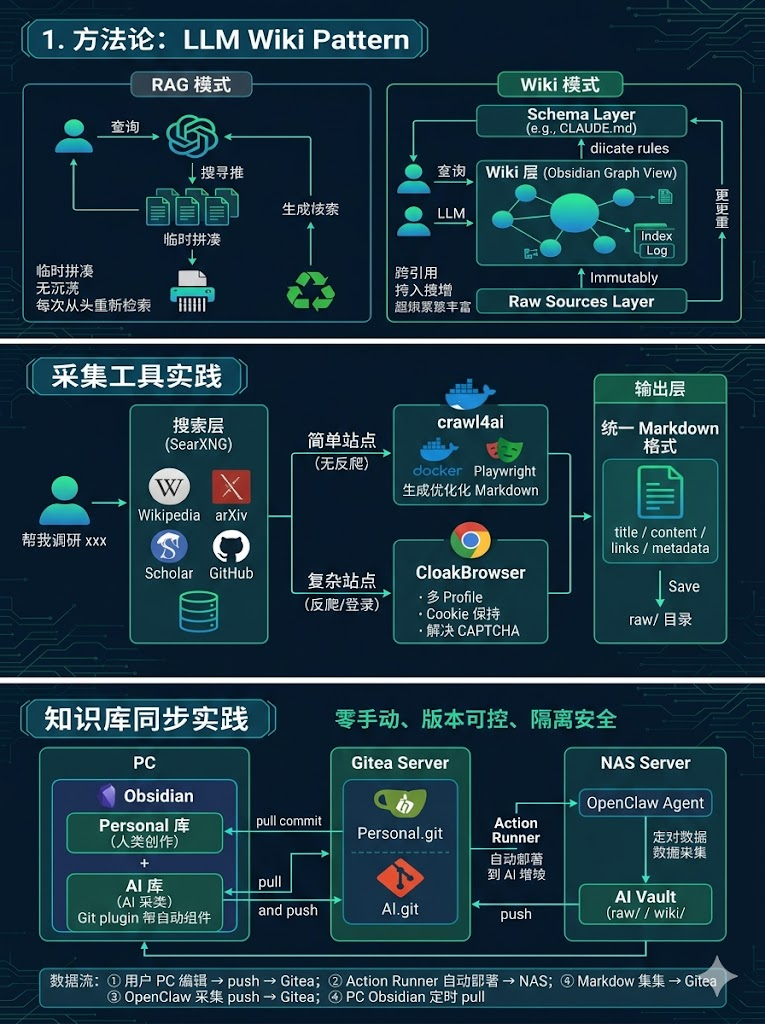
2. 采集工具实践
2.1 采集链路全景
采集是知识库的"源头活水"。没有持续的高质量输入,再好的知识库也会枯竭。
我的采集链路分为三层,各司其职:
2.2 为什么不用 Firecrawl?
最初考虑过 Firecrawl,但它太重了:
|
|
|
|
|---|---|---|
| 模块数 |
|
1 个镜像 |
| 内存需求 |
|
|
| 部署复杂度 |
|
低 |
| 适合场景 |
|
个人 NAS |
Firecrail 的问题:
-
需要部署 5 个独立服务 -
NAS 资源有限,跑不动 -
维护成本高
最终选择:crawl4ai,单容器,无外部依赖。
2.3 SearXNG:搜索聚合引擎
SearXNG 是一个开源的元搜索引擎,聚合 99 个搜索引擎:
-
Wikipedia、arXiv、Google Scholar -
GitHub、GitLab -
各种新闻站、技术博客
为什么用 SearXNG?
-
不依赖单一搜索 API:分布式搜索,避免被封 -
支持指定引擎:可以只搜学术资料或只搜 GitHub -
开源可控:部署在自己 NAS上 -
MCP 协议支持:可以接入 OpenClaw 作为工具
工作流程:
2.4 crawl4ai:轻量级网页采集
crawl4ai 是一个开源的网页采集工具,特点:
-
单容器部署:只需要一个 Docker 镜像 -
内置 Playwright:自动渲染 JS 页面 -
LLM Markdown 优化:自动提取正文,生成高质量 Markdown -
异步设计:支持大规模并发采集
适用场景:
-
技术博客(结构清晰) -
文档站点 -
GitHub 项目页 -
没有强反爬的网站
2.5 CloakBrowser:复杂站点采集
CloakBrowser 是一款反检测浏览器,适合采集"难缠"的站点:
核心能力:
-
多 Profile 管理:每个站点独立 Cookie 环境 -
登录态保持:一次登录,后续自动携带 Cookie -
Web UI 可视化:能看见浏览器在做什么,方便调试 -
CDP 协议:支持远程控制
适用场景:
-
微信公众号:需要微信 UA + 登录态 -
Cloudflare 拦截站:需要绕过浏览器指纹检测 -
需要验证码的站点:手动过验证码后自动采集
2.6 三层采集对比
|
|
|
|
|
|---|---|---|---|
| 搜索层 |
|
|
|
| 简单采集 |
|
|
|
| 复杂采集 |
|
|
|
2.7 采集后的处理
采集只是第一步,更重要的是结构化:
raw/ → wiki/ 的转换由 OpenClaw 自动完成:
-
读取 raw/ 中的 Markdown -
LLM 提取关键概念 -
生成结构化 wiki 页面 -
建立双向链接 -
更新索引和日志
3. 实践:我的双库架构
3.1 Obsidian 双库设计
我的方案是用 Obsidian 分两个库,职责分离:
Personal 库(个人笔记主库)
-
使用 PARA 组织法(Projects, Areas, Resources, Archives) -
存放自己的创作、项目笔记、随手记录 -
以人类写作为主
AI 库(AI 采集知识库)
-
存放 AI 采集和编译的内容 -
内部再分 raw/和wiki/两个目录 -
LLM 主要维护,人类可参与
为什么分开?
-
关注点分离:个人创作 vs 信息摄入 -
避免 AI 生成内容污染个人思考空间 -
两个库可以有完全不同的同步策略
3.2 数据同步架构
这是一个多端协同的架构,涉及 PC、NAS、Gitea、OpenClaw 四个角色:
同步流程详解:
-
用户本地创作
-
PC 上用 Obsidian 编辑 Personal 库和 AI 库 -
Git Plugin 自动 commit
-
Git 插件推送
-
定时 push 到 Gitea(Personal.git 和 AI.git) -
Gitea Action Runner 自动部署
-
检测到 AI.git 提交 -
自动执行脚本 pull 到 NAS 服务器 -
OpenClaw 采集写入
-
OpenClaw 运行在 NAS 上 -
执行采集任务后,写入 AI 库的 raw/ 和 wiki/ -
完成后 push 到 Gitea -
本地 Obsidian 同步
-
Git Plugin 定时 pull Gitea -
获取 OpenClaw 的最新采集结果 -
零手动同步:一切都是自动的,Git 就是同步中枢 -
版本可控:所有改动都有 commit history,可回滚 -
多端一致:PC、NAS、Gitea 三端永远同步 -
隔离安全:Personal 库和 AI 库独立,不互相干扰 -
有 NAS 服务器 -
愿意用 Obsidian + Git 管理笔记 -
希望 AI 能自动采集和整理信息
3.3 为什么这样设计?
优点:
适合人群:
4. 工具部署:Ansible 自动化
为了方便管理和迁移,我用 Ansible Playbook 管理所有工具:
# 核心 playbook 结构
├── searxng.yml # SearXNG 部署 + MCP 配置
├── crawl4ai.yml # crawl4ai Docker 部署
├── cloakbrowser.yml # CloakBrowser + Profile 管理
└── update.yml # 增量更新脚本
优势:
-
一键部署 / 升级 -
修改后同步到多台机器 -
版本可控,可回滚 -
基础设施即代码
5. 实验计划
目标:用 2 个月验证 LLM Notebook 的可行性
核心指标:
-
知识库条目数 -
交叉链接数 -
实际提问使用率 -
Wiki 被 LLM 引用的频率
当前进展:
-
✅ 采集链路打通(SearXNG + crawl4ai + CloakBrowser) -
✅ Git 同步流打通(PC ↔ Gitea ↔ NAS) -
✅ OpenClaw 定时任务配置(每天 3:00 / 12:00 自动调研) -
🔄 持续采集中
6. 总结
核心理念:
我只负责给 URL,AI 负责采集和构建。
搞通这个数据流程,就玩转起来了。天光云影共徘徊,唯有源头活水来。
技术栈总结:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
参考
-
Karpathy LLM Wiki Pattern -
crawl4ai GitHub -
SearXNG -
CloakBrowser
