
01
检索场景 ,如何降低搜索型 Token 消耗
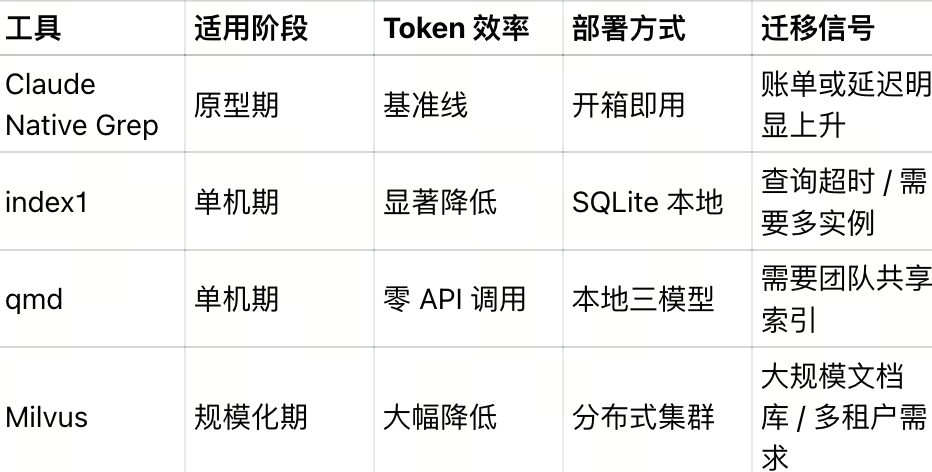
02
记忆场景,如何让构建可控的长期记忆,进一步压缩Token消耗

-
透明可控:所有记忆都是本地明文Markdown(MEMORY.md手写长期记忆、YYYY-MM-DD.md自动生成每日日志),打开就能看、不满意直接改,保存后自动重新索引,无需调API; -
团队协作友好:Markdown文件可直接用Git管理,谁改了什么、什么时候改的,git log一目了然,甚至能通过PR评审AI的记忆内容; -
迁移自由:纯明文Markdown存储,迁移零成本——换电脑复制文件夹、换embedding模型重新索引、换向量数据库改一行配置,Markdown文件无需改动; -
人机共创:AI自动记录执行细节(每日日志),人类手动提炼长期原则(MEMORY.md),无需懂代码,打开文件就能协作编辑,这是传统向量数据库方案无法实现的。
