

这次聊的是StoryDiffusion这款AI工具,它是由字节跳动和南开大学合作推出的,最大的特点就是生成一致性图像,也就是你提供一个故事情节,它能根据这个故事情节生成多张图片,这些图片的风格基本都是一致的,看起来就跟看真实的漫画的一样。
毋庸置疑,这款AI工具又带来了很多的商机,比如实现之前很火的AI故事绘本,或是直接用小说情节生成图片,然后利用剪映等工具生成我们常见的小说短视频。
值得一提的是,StoryDiffusion虽然能生成视频,但是它的视频并非是直接根据提示词生成的(像Sora一样),而是先生成多张风格一致的图片,然后再通过加速形成视频(视频的原理)。

那StoryDiffusion能生成什么风格的图片?
目前根据官网放出的图片来看,卡通动物、卡通人物以及真实人物的图片都能生成,取决于你使用的模型。
1、卡通动物示例图

2、卡通人物示例图

3、真实人物示例图

注:从上图也可以看到,StoryDiffusion生成的图片是可以同时拥有多个角色的(比如上面的人和狗),并非单一角色
那如何体验 StoryDiffusion 呢?这应该是大家比较着急的问题
1、方式一:自己部署
综合来看这种方式是不太推荐的,一是显卡要求较高,目测显存至少要20G(比之前腾讯混元的高多了),不过官方只是说大于20G用起来会比较好,没说低于20G就不能跑,但最少得多少就真没测过。二是部署也要花费一定时间成本,对不熟悉编程的朋友也不太友好。
2、方式二:Colab部署
这种方式看起来一般,官方在Github上提供了一份 Comic_Generation.ipynb,如果你熟悉Google的Colab的话,也可以直接丢在上面跑,Colab也提供了免费的GPU羊毛,不过据说这个免费羊毛的显存为15G,CPU为12G,估计也不够跑,等有空可以验证下
3、方式三:HuggingFace
目前 StoryDiffusion 在HuggingFace有免费的体验地址,但高峰期的话要等待,因为是多人抢占GPU,而且生成失败的概率也蛮高,但胜在不用自己部署 ?
体验地址:https://huggingface.co/spaces/YupengZhou/StoryDiffusion
偶尔蹲一下也是能成功的

哎,果然穷处处受限制呀!
现在只有最后一个问题了,假设部署后,如何使用StoryDiffusion 呢?
假设你部署成功后,浏览器应该会弹出这样的界面(假设你是用gradio),左边是参数调整区,右边是出图区
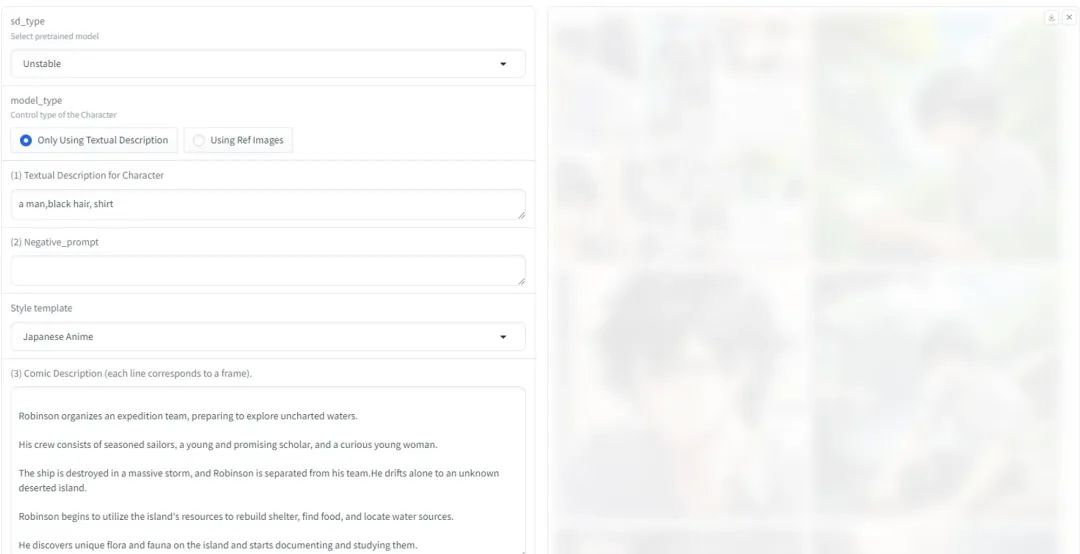
1、sd_type
这个参数其实就是让你选生图大模型,有点像我们提到的Stable Diffusion的底模
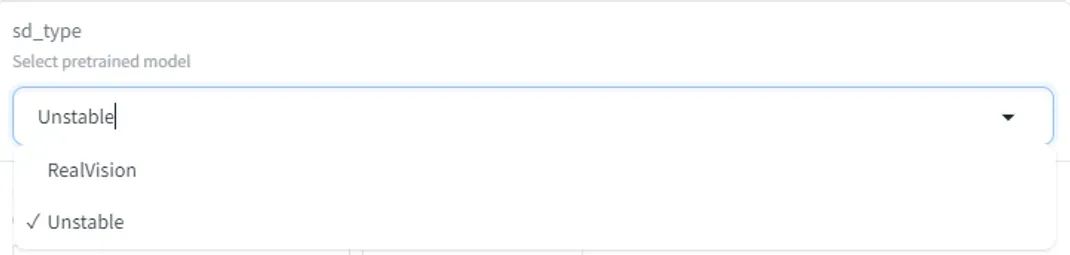
目前huggingface的只有两种,但如果你看Comic_Generation.ipynb,其实有四种
models_dict = { :, : , : , : }
而且据官方的说明,模型这块是可插拔的,兼容所有SD1.5和SDXL-based的模型,所以没准还能用C站的模型替换 ?

2、model_type
这个其实类似 Stable Diffusion的文生图和图生图。
3、Textual Description for Character
撰写角色提示词的地方,也就是你对图片角色的描绘,比如
man,black hair, shirt
Negative_prompt:反向提示词
4、Style template
这个也比较好理解,就是出图风格

5、Comic Description
这个就是故事情节的描述了,每一行对应一帧,也就是一张图片,这块可以借助各种AI工具生成
6、Tune the hyerparameters
这块的参数看起来是控制模型层数,没看太懂,有空研究下
7、Seed + steps
种子和步数,了解过Stable Diffusion的应该都比较清楚
8、height + width
如果是用huggingface 体验的话,建议可以调小一点,比如512,出图的成功率应该会高些
9、Typesetting style
这个控制的是图片的排版风格
最后如果对StoryDiffusion出图感兴趣的朋友,建议看下它的Huggingface,有比较多的注意事项,以及出图的提示词Example。
