

想让 ChatGPT 不再“答非所问”?想打造属于你自己的 AI 助理,读懂你的资料?
本文手把手带你用 LlamaIndex 构建一个“可读PDF/Word文件”的问答系统,无需大模型训练,不用写一堆代码,新手也能搞定!
🔧 一、你将搭建一个什么系统?
我们要搭的,是这样一个 AI 应用:
📝 你上传一份文档(比如《员工手册》或《产品说明书》)
💬 然后你就可以对它提问,比如:“试用期有几个月?”、“产品适合哪些用户?”
🤖 AI 会准确回答你问题,就像它已经“读过”文档一样聪明!
这个系统的幕后英雄,就是 —— LlamaIndex + OpenAI 大模型(或本地大模型)
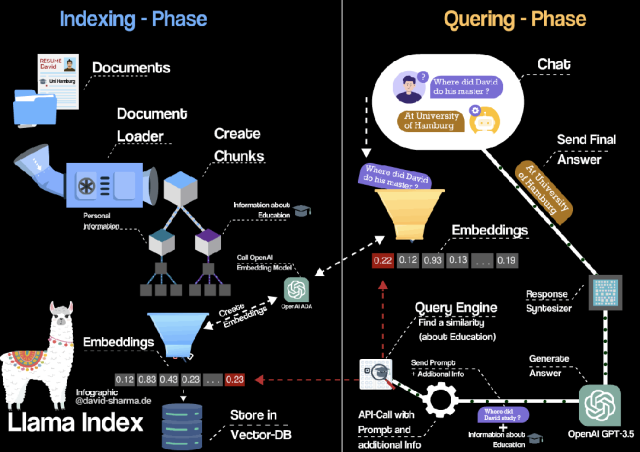
📦 二、准备工作:这些你得先搞定
1. 基础环境准备(推荐用Python虚拟环境)
pip install llama-index openai
🚨 如果你用的是本地模型(如 Ollama、DeepSeek、ChatGLM),可用
llama-index-llms-xxx模块适配。
2. 设置 OpenAI Key(如使用 ChatGPT 模型)
import osos.environ["OPENAI_API_KEY"] = "你的key"
🧱 三、5步搭建问答系统(超详细)
✅ 步骤 1:加载文档
from llama_index import download_loaderPDFReader = download_loader("PDFReader")loader = PDFReader()documents = loader.load_data(file="your_file.pdf") # 支持 .pdf、.docx、.md 等格式
✅ 步骤 2:构建索引(建图书馆目录)
from llama_index import VectorStoreIndexindex = VectorStoreIndex.from_documents(documents)
这一步会把文档切分为段落、计算向量、建立索引,方便快速搜索。
✅ 步骤 3:创建问答引擎
query_engine = index.as_query_engine()
LlamaIndex 默认会将你的问题自动转化成“智能检索+生成回答”的模式。
✅ 步骤 4:开始提问
response = query_engine.query("试用期员工有哪些规定?")print(response)
你会看到一个准确且贴合文档内容的回答!
💡 四、可拓展玩法:再高级一点点
1. 支持多文档问答
from llama_index import SimpleDirectoryReaderdocuments = SimpleDirectoryReader("./my_documents").load_data()
将多个文件放入同一文件夹,实现企业级资料整合!
2. 自定义 Prompt & 模型接口
你可以接入自己的本地模型:
from llama_index.llms.ollama import Ollamallm = Ollama(model="llama3")query_engine = index.as_query_engine(llm=llm)
还可以自定义提示词:
from llama_index.prompts import PromptTemplatecustom_prompt = PromptTemplate("请根据以下文档内容认真回答问题:{context_str}n问题是:{query_str}")query_engine = index.as_query_engine(text_qa_template=custom_prompt)
3. 接入 Web UI(如 Gradio)
想部署到网页?配合 Gradio,几行代码搞定:
import gradio as grdef chat_with_doc(question): response = query_engine.query(question) return str(response)gr.Interface(fn=chat_with_doc, inputs="text", outputs="text").launch()
🧠 五、写在最后:这就是你的“私人ChatGPT”
你不需要训练模型、不需要大数据集,只要一份文档,加上 LlamaIndex,你就可以:
-
构建 个人笔记问答系统;
-
构建 企业知识库机器人;
-
构建 教育类智能答疑助手;
未来你甚至可以配合 LangChain、Agent 模型、向量数据库,做出更智能的工作流!
💬 一句话总结:
LlamaIndex 就像给 ChatGPT 装了一个“读书器”,让它终于能读懂你自己的文档!
