
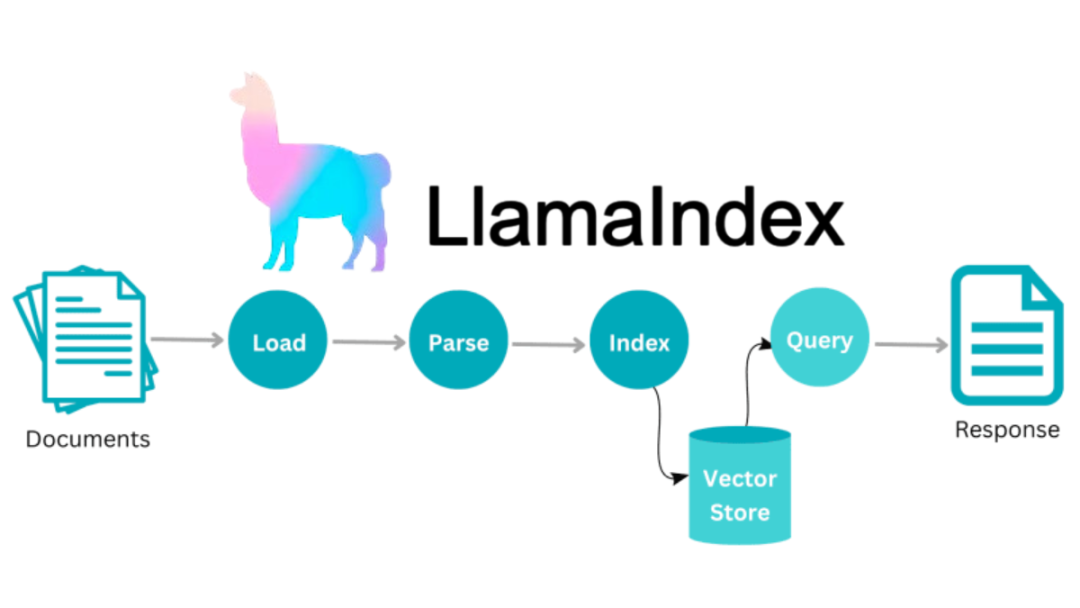
想象一下,有一个私人研究助手不仅能理解你的问题,还能智能地决定如何找到答案。对于某些问题,它会深入你的文档库中查找答案,而对于其他问题,它则会生成富有创意的回应。这听起来是不是很酷?其实,这一切都可以通过使用 Agentic RAG(检索增强型生成) 和 LlamaIndex TypeScript 系统来实现。
无论你是想创建一个文献分析系统、技术文档助手,还是任何知识密集型应用,本文介绍的方法都将为你提供一个实用的基础框架。接下来,我们将通过一个实际的动手项目,带你一步步构建这样一个系统,从设置本地模型到实现专门的工具,最终交付令人惊叹的结果。
为什么选择 TypeScript?
TypeScript 是一种强大的编程语言,它为构建基于 LLM(大型语言模型)的 AI 应用提供了诸多优势:
-
类型安全:TypeScript 的静态类型检查可以在开发过程中捕捉错误,而不是等到运行时才发现。 -
更好的 IDE 支持:自动补全和智能提示让开发过程更快捷。 -
提高可维护性:类型定义让代码更易读,也更具自文档性。 -
无缝 JavaScript 集成:TypeScript 可以与现有的 JavaScript 库无缝对接。 -
可扩展性:随着你的 RAG 应用不断扩展,TypeScript 的结构化特性有助于管理复杂性。 -
框架支持:Vite、NextJS 等强大的 Web 框架与 TypeScript 无缝连接,让构建基于 AI 的 Web 应用变得轻松且可扩展。
LlamaIndex 的优势
LlamaIndex 是一个强大的框架,用于构建基于 LLM 的 AI 应用。它提供了以下优势:
-
简化数据加载:通过 LlamaParse,可以轻松加载和处理本地或云端的文档。 -
向量存储:内置支持嵌入和检索语义信息,支持与 ChromaDB、Milvus、Weaviate 和 pgvector 等行业标准数据库的集成。 -
工具集成:可以创建和管理多个专业工具。 -
代理插件:你可以轻松构建或插入第三方代理。 -
查询引擎灵活性:可以根据不同的用例定制查询处理。 -
持久化支持:可以保存和加载索引,提高重复使用的效率。
什么是 Agentic RAG?
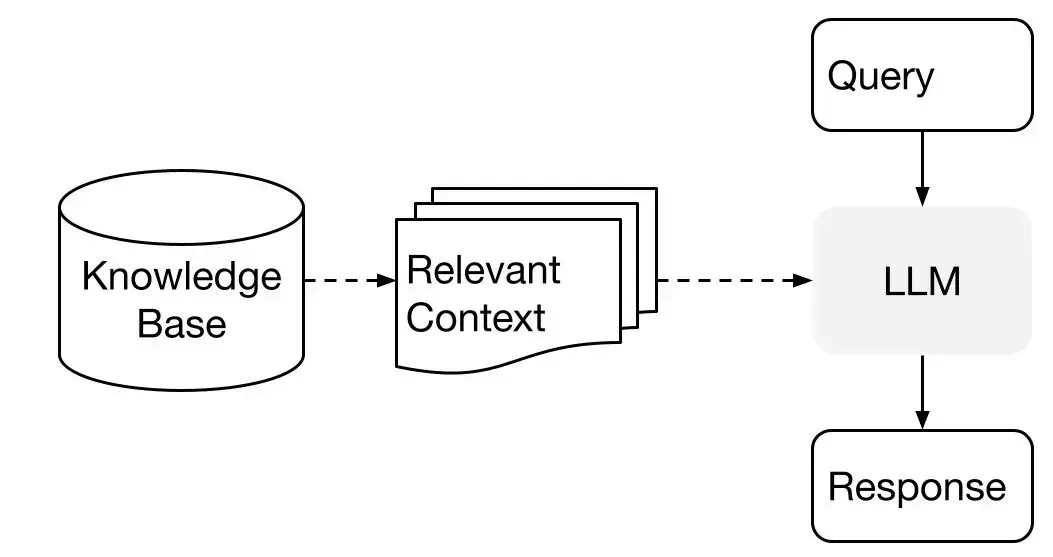
在深入实现之前,我们先来了解一下 Agentic RAG 是什么。RAG(检索增强型生成)是一种技术,通过从知识库中检索相关信息来增强语言模型的输出,然后利用这些信息生成更准确、更符合事实的回应。而 Agentic 系统则涉及 AI 根据用户查询决定采取哪些行动,有效地作为一个智能助手,选择合适的工具来满足请求。
Agentic RAG 系统结合了这两种方法,创建了一个既能从知识库中检索信息,又能根据需要使用其他工具的 AI 助手。根据用户问题的性质,它会决定是使用内置知识、查询向量数据库,还是调用外部工具。
开发环境搭建
安装 Node.js
在 Windows 上安装 Node.js 的步骤如下:
# 下载并安装 fnm
winget install Schniz.fnm
# 下载并安装 Node.js
fnm install 22
# 验证 Node.js 版本
node -v # 应输出 "v22.14.0"
# 验证 npm 版本
npm -v # 应输出 "10.9.2"
其他系统可以参考 官方文档。
从简单数学代理开始
让我们先从一个简单的数学代理开始,了解 LlamaIndex TypeScript API 的基本用法。
第一步:设置工作环境
创建一个新目录,进入该目录并初始化一个 Node.js 项目,安装必要的依赖:
$ md simple-agent
$ cd simple-agent
$ npm init
$ npm install llamaindex @llamaindex/ollama
我们将为数学代理创建两个工具:
-
一个加法工具,用于计算两个数字的和。 -
一个除法工具,用于计算两个数字的商。
第二步:导入必要的模块
在你的脚本中添加以下导入:
import { agent, Settings, tool } from "llamaindex";
import { z } from "zod";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
第三步:创建 Ollama 模型实例
实例化 Llama 模型:
const llama3 = new Ollama({
model: "llama3.2:1b",
});
现在,你可以通过 Settings 直接为系统设置主模型,或者在代理中直接使用不同的模型。
Settings.llm = llama3;
第四步:创建数学代理工具
创建加法和除法工具:
const addNumbers = tool({
name: "SumNumbers",
description: "使用此函数计算两个数字的和",
parameters: z.object({
a: z.number().describe("第一个数字"),
b: z.number().describe("第二个数字"),
}),
execute: ({ a, b }: { a: number; b: number }) => `${a + b}`,
});
这里我们使用了 Zod 库来验证工具的参数。同样地,我们创建一个除法工具:
const divideNumbers = tool({
name: "divideNumber",
description: "使用此函数计算两个数字的商",
parameters: z.object({
a: z.number().describe("被除数"),
b: z.number().describe("除数"),
}),
execute: ({ a, b }: { a: number; b: number }) => `${a / b}`,
});
第五步:创建数学代理
在主函数中,我们创建一个数学代理,使用这些工具进行计算:
async function main(query: string) {
const mathAgent = agent({
tools: [addNumbers, divideNumbers],
llm: llama3,
verbose: false,
});
const response = await mathAgent.run(query);
console.log(response.data);
}
// 驱动代码,运行应用
const query = "Add two number 5 and 7 and divide by 2";
void main(query).then(() => {
console.log("Done");
});
如果你直接通过 Settings 设置 LLM,那么你不需要在代理中显式指定 LLM 参数。如果你希望为不同的代理使用不同的模型,那么必须显式指定 llm 参数。
运行这段代码后,你将得到如下输出:
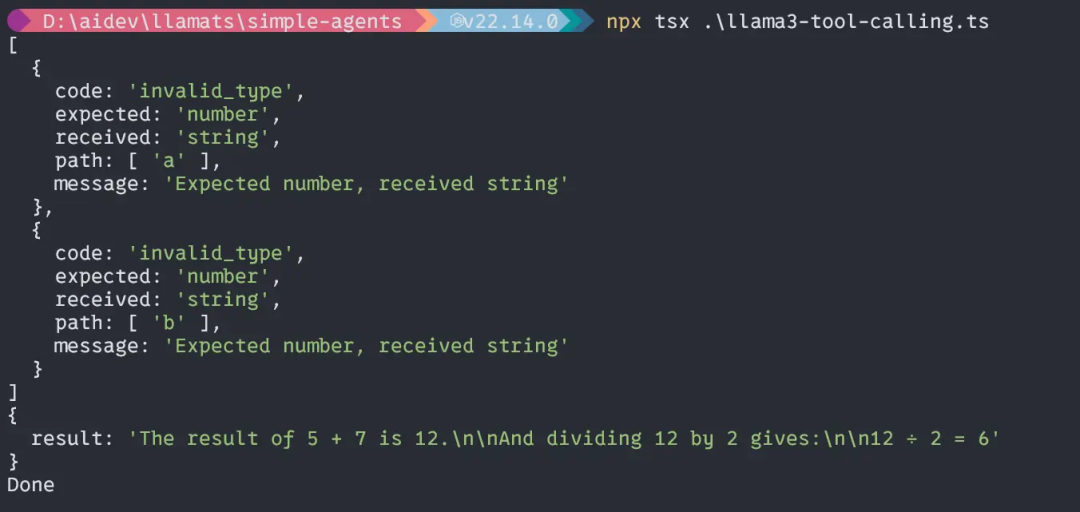
接下来,我们尝试一个更复杂的查询:
const query = "If the total number of boys in a class is 50 and girls is 30, what is the total number of students in the class?";
void main(query).then(() => {
console.log("Done");
});
输出:
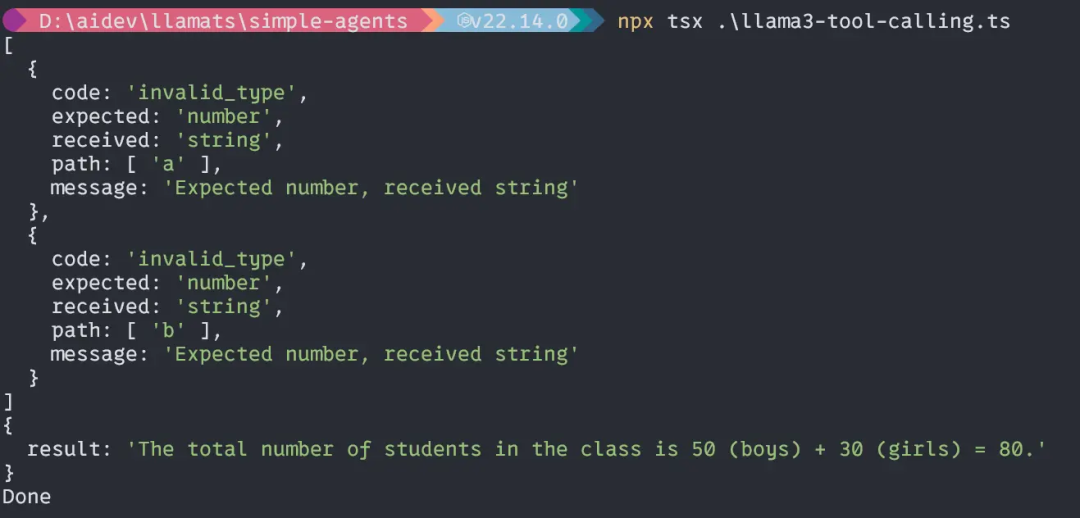
哇,我们的小 Llama3.2 1B 模型表现得相当出色,能够准确地处理代理任务并进行计算!现在,让我们深入到项目的主体部分。
构建 Agentic RAG 应用
开发环境搭建
按照以下步骤设置开发环境:
$ md agentic-rag-app
$ cd agentic-rag-app
$ npm init
$ npm install llamaindex @llamaindex/ollama
同时,从 Ollama 中拉取必要的模型,例如 Llama3.2:1b 和 nomic-embed-text。
在我们的应用中,我们将有四个模块:
-
load-index:用于加载和索引文本文件。 -
query-paul:用于查询 Paul Graham 的文章。 -
constant:用于存储可重用的常量。 -
app:用于运行整个应用。
首先,创建 constant.ts 文件和 data 文件夹:
// constant.ts
const constant = {
STORAGE_DIR: "./storage",
DATA_FILE: "data/pual-essay.txt",
};
export default constant;
这是一个包含必要常量的对象,将在整个应用中多次使用。创建一个 data 文件夹,并将文本文件放入其中。你可以从 这里 下载数据源。
实现加载和索引模块

以下是加载和索引模块的实现流程:
导入必要的包
import { Settings, storageContextFromDefaults } from "llamaindex";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
import { Document, VectorStoreIndex } from "llamaindex";
import fs from "fs/promises";
import constant from "./constant";
创建 Ollama 模型实例
const llama3 = new Ollama({
model: "llama3.2:1b",
});
const nomic = new OllamaEmbedding({
model: "nomic-embed-text",
});
设置系统模型
Settings.llm = llama3;
Settings.embedModel = nomic;
实现 indexAndStorage 函数
async function indexAndStorage() {
try {
// 设置持久化存储
const storageContext = await storageContextFromDefaults({
persistDir: constant.STORAGE_DIR,
});
// 加载文档
const essay = await fs.readFile(constant.DATA_FILE, "utf-8");
constdocument = new Document({
text: essay,
id_: "essay",
});
// 创建并持久化索引
await VectorStoreIndex.fromDocuments([document], {
storageContext,
});
console.log("索引和嵌入文件已成功存储!");
} catch (error) {
console.log("索引过程中发生错误:", error);
}
}
这段代码将创建一个持久化存储空间,用于存储索引和嵌入文件。然后,它将从项目的数据目录中加载文本数据,并使用 LlamaIndex 的 Document 方法创建一个文档对象。最后,它将使用 VectorStoreIndex 方法从该文档创建一个向量索引。
导出函数
export default indexAndStorage;
实现查询模块
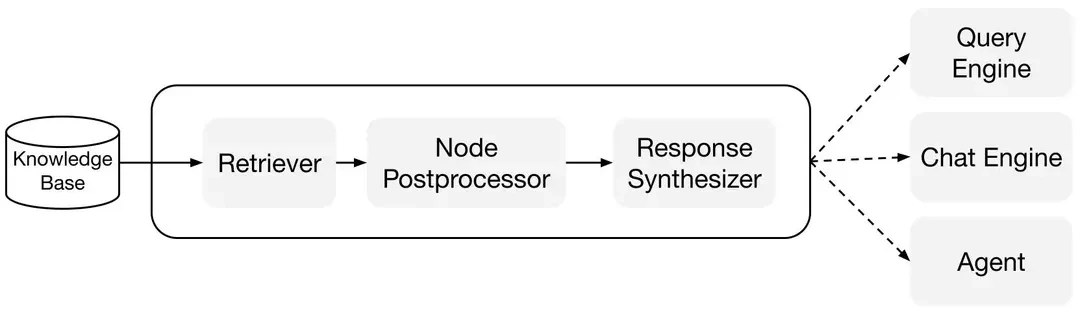
接下来,我们实现查询模块。创建一个名为 query-paul.ts 的文件。
导入必要的包
import {
Settings,
storageContextFromDefaults,
VectorStoreIndex,
} from "llamaindex";
import constant from "./constant";
import { Ollama, OllamaEmbedding } from "@llamaindex/ollama";
import { agent } from "llamaindex";
创建和设置模型
创建和设置模型的方式与前面相同。
实现 loadAndQuery 函数
async function loadAndQuery(query: string) {
try {
// 从持久化存储中加载索引
const storageContext = await storageContextFromDefaults({
persistDir: constant.STORAGE_DIR,
});
// 加载已有的索引
const index = await VectorStoreIndex.init({ storageContext });
// 创建检索器和查询引擎
const retriever = index.asRetriever();
const queryEngine = index.asQueryEngine({ retriever });
const tools = [
index.queryTool({
metadata: {
name: "paul_graham_essay_tool",
description: `此工具可以回答有关 Paul Graham 文章的详细问题。`,
},
}),
];
const ragAgent = agent({ tools });
// 查询已索引的文章
const response = await queryEngine.query({ query });
let toolResponse = await ragAgent.run(query);
console.log("响应:", response.message);
console.log("工具响应:", toolResponse);
} catch (error) {
console.log("检索过程中发生错误:", error);
}
}
在这段代码中,我们首先从 STORAGE_DIR 中加载存储上下文,然后使用 VectorStoreIndex.init() 方法加载已索引的文件。加载完成后,我们创建一个检索器和查询引擎。接下来,我们创建一个工具,该工具可以从已索引的文件中回答问题,并将其添加到名为 ragAgent 的代理中。
然后,我们通过查询引擎和代理分别查询已索引的文章,并将响应输出到终端。
导出函数
export default loadAndQuery;
实现 app.ts
现在,我们将所有模块整合到一个 app.ts 文件中,方便执行。
import indexAndStorage from"./load-index";
import loadAndQuery from"./query-paul";
function main(query: string) {
console.log("======================================");
console.log("正在索引数据....");
indexAndStorage();
console.log("数据索引完成!");
console.log("请稍候,正在获取响应或订阅!");
loadAndQuery(query);
}
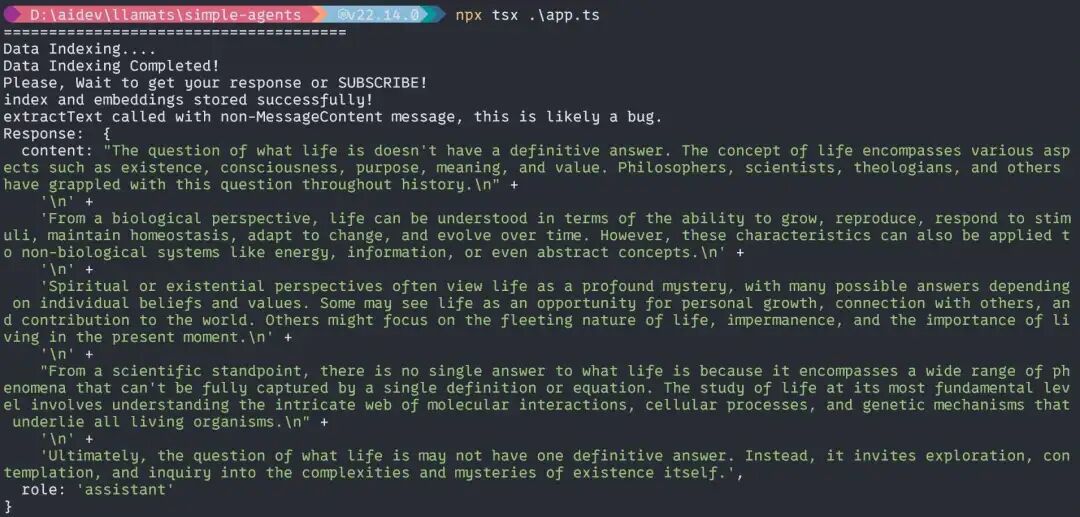
const query = "什么是生活?";
main(query);
在这里,我们导入所有模块,按顺序执行它们,并运行应用。
运行应用
在终端中运行以下命令:
$ npx tsx ./app.ts
首次运行时,可能会发生以下几件事:
-
它会提示你安装 tsx,请按照提示安装。 -
它会根据你的系统性能花费一些时间来嵌入文档(这是一次性的操作)。 -
最后,它会返回响应。
以下是首次运行的示例:

没有代理时,响应可能如下所示:
使用代理时,响应可能如下所示:
今天的分享就到这里。希望这篇文章能帮助你了解 TypeScript 的工作流程。
项目代码仓库
你可以在 这里 找到完整的项目代码。
总结
这是一个简单但功能强大的 Agentic RAG Using LlamaIndex TypeScript 系统。通过这篇文章,我想让你了解除了 Python 之外,还可以使用 TypeScript 来构建 Agentic RAG Using LlamaIndex TypeScript 或其他基于 LLM 的 AI 应用。Agentic RAG 系统是基本 RAG 实现的有力进化,能够根据用户查询提供更智能、更灵活的响应。使用 LlamaIndex 和 TypeScript,你可以以类型安全、可维护的方式构建这样的系统,并且它能够很好地与 Web 应用生态系统集成。
