

环境搭建
实践会用到的安装包如下:
langchain==0.2.9 torch html2text paddlepaddle paddleocr
文本提取
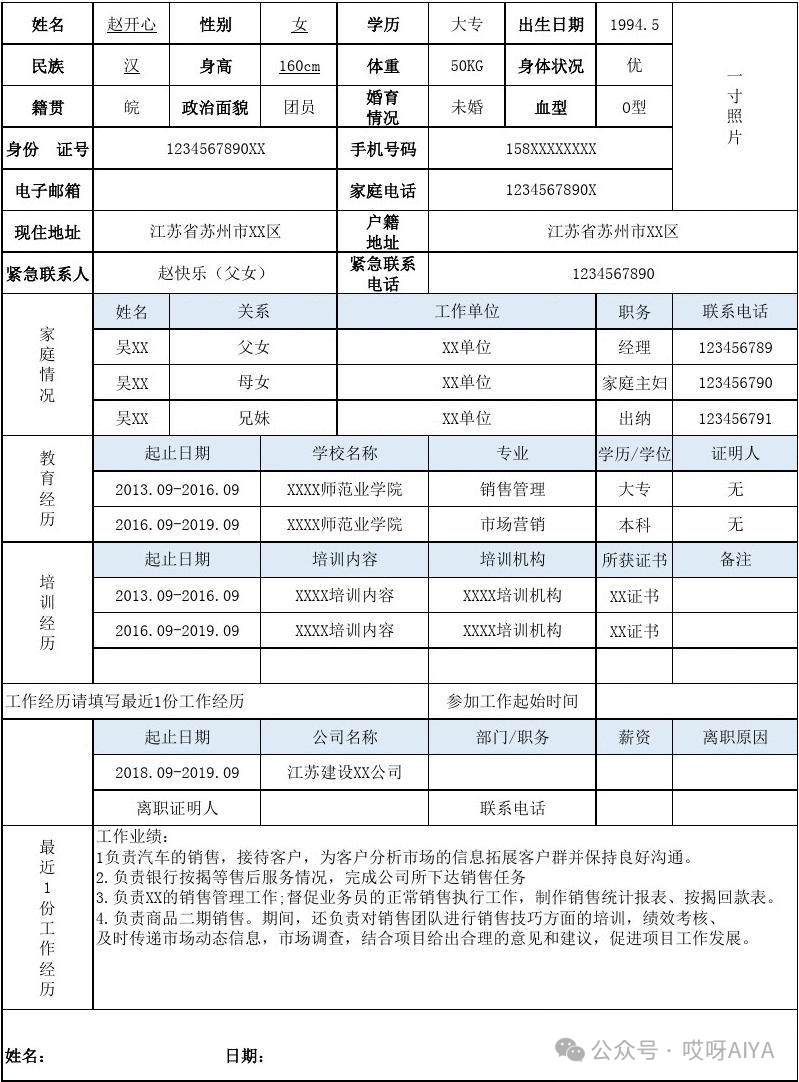
我们使用paddleocr进行图片表格识别,这个过程会识别出格式信息和文本:
import cv2from paddleocr import PPStructuretable_engine = PPStructure(show_log=True, use_gpu=False, lang='ch')img_path = r'./2.jpg'img = cv2.imread(img_path)result = table_engine(img)html = result[0]['res']['html']print(len(html))# 2723
提取的文本是html格式的,占据了很多无用的格式提示词,我们将它转为markdown格式,这样可以有效的减少输入长度:
import html2textmarkdown = html2text.html2text(html)print(len(markdown))# 1051
定义模型
我们可以使用OpenAI的接口,模型构建代码为:
from langchain_openai import ChatOpenAIchat_model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0.0)
也可以加载自己的模型,可参考RAG:Langchain中使用自己的LLM大模型:
from langchain_huggingface import HuggingFacePipelinefrom langchain_huggingface import ChatHuggingFacellm = HuggingFacePipeline.from_model_id(model_id="./Qwen/Qwen2-0.5B-Instruct",task="text-generation",pipeline_kwargs=dict(max_new_tokens=512,do_sample=False,),)chat_model = ChatHuggingFace(llm=llm)
这样我们就构建好了自己的模型,后面的应用流程可以灵活配置。
要素提取
下面我们展示Qwen2-0.5B的例子,搭建LangChain问答pipeline:
from langchain_core.prompts import ChatPromptTemplate# 创建Prompt模板chat_prompt_template = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant"),("user", "根据表格内容回答下面问题:n表格内容:n{context}nQuestion: {question}nAnswer:")])# 流程搭建chain = chat_prompt_template | chat_model.bind(skip_prompt=True)# 问答运行res = chain.invoke({"context": markdown, "question": "姓名是什么?"})# res.content# 赵开心res = chain.invoke({"context": markdown, "question": "婚姻状况?"})# res.content# 婚姻状况为未婚。
由于0.5B的模型比较小,我们做要素问答效果比较好,如果想一次性提取,那么可以使用更大的模型。下篇文章将介绍怎么做一次性结构化提取,prompt该怎么写。
