


小测了一下DeepSeek V4 pro 的真实写代码能力和Agent能力,对比的是 GPT-5.3 codex high。整体结果:GPT-5.3 codex high > DeepSeek V4 pro
本文测试结果仅供参考
这次测试选取了DeepSeek V4 Pro(通过 Claude Code 调用)、GPT-5.3 Codex High测试。评估模型为 GPT-5.5 thinking。
整个测试分成两轮。
第一轮是算法题,TypeScript 实现 LRU Cache。
在 LRU 这道题上:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
第二轮是更接近真实工程的 Agent 任务,TypeScript 实现一个本地 Markdown 文章分析 CLI 工具。
这轮 Markdown CLI 任务:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
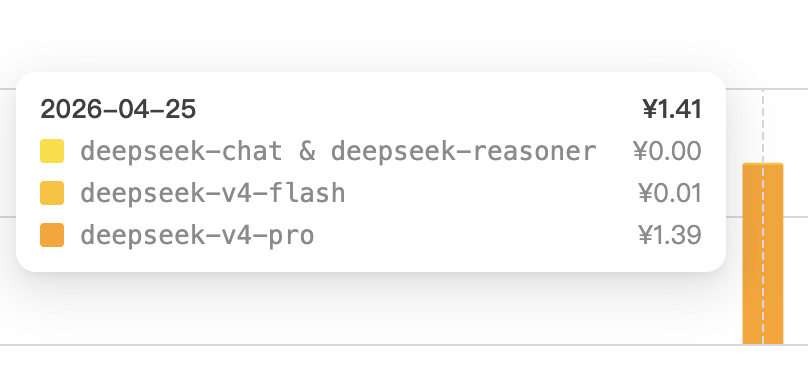
由于昨晚deepseek推出API 2.5折,所以测试只花了1.4
从 GPT-5.3 Codex 到 GPT-5.4,再到 GPT-5.5,OpenAI 基本是以月更节奏在推前沿模型:2 月 24 日上线 GPT-5.3 Codex,3 月 5 日上线 GPT-5.4,4 月 23 日上线 GPT-5.5。 所以比较GPT-5.3 Codex high 和V4 pro是一个合理选择。
以下是详细过程:
第一轮:LRU Cache,测的是基础代码能力
第一道题是:
用 TypeScript 实现一个 LRU Cache。
要求:
1. get 和 put 都是 O(1)
2. 支持 capacity
3. capacity 为 0 时也要正确处理
4. 写出完整代码
5. 给出 5 个测试用例
这道题不算特别难,很适合筛模型。
因为弱模型很容易在这些地方翻车:
-
• 用数组实现,导致不是 O(1) -
• get 之后忘记刷新最近使用顺序 -
• put 已有 key 时只更新值,不刷新顺序 -
• capacity 等于 0 时逻辑出错 -
• 用 if value 判断命中,导致 0、false、空字符串被误判 -
• 测试只写 happy path -
• TypeScript 类型随便糊
这道题的关键不只是会不会写 LRU,而是能不能把边界写稳。
DeepSeek V4 Pro:第一版就给标准答案
DeepSeek V4 Pro 第一版直接使用了标准方案:
Map 加双向链表。
这是语言无关的经典 LRU 实现方式。
它的结构大致是:
class ListNode {
key: number;
val: number;
prev: ListNode | null = null;
next: ListNode | null = null;
}
class LRUCache {
private capacity: number;
private map = new Map<number, ListNode>();
private head: ListNode;
private tail: ListNode;
}get 时从 Map 找节点,然后移动到链表头部。
put 时如果 key 已存在,就更新值并移动到头部;如果超容量,就淘汰 tail 前面的最久未使用节点。
它还处理了 capacity 为 0、capacity 为 1、更新已有 key、LeetCode 经典用例等测试。
第一版评分是:
8.2 分。
优点很明确:
-
• 数据结构选得对 -
• get 和 put 真的是 O(1) -
• capacity 为 0 处理正确 -
• 测试不是纯 happy path
但问题也有:
-
• 第一版只支持 number key 和 number value,不是泛型 -
• 没有校验非法 capacity,比如 NaN、Infinity、浮点数 -
• removeNode 后没有清理节点指针 -
• 测试方式比较原始 -
• 有一个更新 key 的测试说明不够精确
不过总体看,DeepSeek V4 Pro 第一反应很标准。
它没有走捷径,而是直接给出面试和算法题里最正统的答案。
DeepSeek 多轮追问后:从算法题解进化到工程实现
后续继续追问,要求它升级成工程版本:
-
• 支持泛型 key 和 value -
• 不依赖 JS Map 插入顺序 -
• constructor 校验 capacity -
• removeNode 后清理节点指针 -
• 增加 size、clear、has -
• 用 Vitest 写测试 -
• 说明复杂度
DeepSeek V4 Pro 完成得不错。
它改成了泛型版本:
export class LRUCache<K, V>然后补了:
-
• capacity 非负整数校验 -
• size -
• has -
• clear -
• Vitest 测试 -
• 泛型对象测试 -
• capacity 为 0 和 1 -
• 更新已有 key 后刷新顺序 -
• 不依赖 Map 插入顺序
这一版评分提升到:
8.7 分。
但它也暴露了典型问题:
为了创建哨兵节点,它用了:
null as unknown as K这能跑,但类型建模不够干净。
后来继续追问,它把节点拆成了两类:
class LinkEntry {
prev: LinkEntry | null = null;
next: LinkEntry | null = null;
}
class DataEntry<K, V> extends LinkEntry {
constructor(public key: K, public val: V) {
super();
}
}这样哨兵节点只负责链表指针,真实数据节点才有 key 和 value。
这个设计更符合 TypeScript 类型系统。
继续追问后,它还补了 get 和 tryGet 的 API 设计。
因为 get 返回 undefined 时,如果缓存值本身就是 undefined,就无法区分命中和未命中。
DeepSeek 的做法是:
-
• get 保留简单用法,返回 V 或 undefined -
• tryGet 提供严谨用法,返回 found true 或 found false
这个设计比较工程化,既保留易用性,也解决了类型歧义。
最后,DeepSeek V4 Pro 在 LRU 多轮测试里的最终表现大概是:
9.0 分。
它的特点是:
第一响应标准,后续能持续工程化。
但也不是没有问题。
它曾经写过一个伪测试,声称测试了淘汰节点的 prev 和 next 被置空,但公开 API 根本拿不到内部节点,所以这个测试实际上只能证明 key 被淘汰,不能证明指针被清理。
被指出后,它删掉了这个伪测试,并把压力测试名称从不退化 O(1)改成批量读写下的 LRU 淘汰正确性。
这说明它能修,但不一定一开始就主动全局自查。
GPT-5.3 codex high:第一版标准,追问后也能工程化,但完整度略弱
5.3第一版也用了 Map 加双向链表。
第一版大致结构是:
class ListNode<K, V> {
key: K;
value: V;
prev: ListNode<K, V> | null = null;
next: ListNode<K, V> | null = null;
}测试覆盖:
-
• 基本 put 和 get -
• 超容量淘汰 -
• get 刷新顺序 -
• put 已有 key 更新并刷新 -
• capacity 为 0
第一版评分:
7.8 分。
它的问题主要是:
-
• capacity 用 Math.max 处理,NaN 仍有问题 -
• 哨兵节点使用 null as unknown -
• get 返回 undefined,有命中歧义 -
• 测试没有覆盖非法 capacity 和 undefined value
追问后,5.3改成了 circular sentinel 设计:
class LinkNode {
prev: LinkNode;
next: LinkNode;
constructor() {
this.prev = this;
this.next = this;
}
}真实数据节点继承 LinkNode:
class DataNode<K, V> extends LinkNode {
constructor(
public key: K,
public value: V,
) {
super();
}
}这个设计不错。
它去掉了 null as unknown,也做了 capacity 校验,并把 get 改成:
type GetResult<V> = { hit: true; value: V } | { hit: false };还补了 Vitest 测试:
-
• NaN -
• Infinity -
• 负数 -
• 浮点数 -
• capacity 为 0 -
• capacity 为 1 -
• value 为 undefined -
• 更新已有 key 刷新顺序
这一版评分:
8.6 分。
它已经是工程版合格偏强。
但相比 DeepSeek 它还有差距:
-
• 测试数量偏少 -
• 缺少基础正常路径回归测试 -
• 没有解释 API 设计取舍 -
• 没有充分解释 circular sentinel 设计 -
• 工程完整度不如前者后期
但 LRU 还不够:真正的 Agent 能力要看工程交付
LRU 题能测数据结构、边界、类型设计和测试意识。
但它不能充分测试 Agent 能力。
真实代码 Agent 要做的不是写一个函数,而是:
-
• 读需求 -
• 拆任务 -
• 建项目结构 -
• 写多文件代码 -
• 处理文件系统 -
• 做 CLI -
• 写测试 -
• 跑类型检查 -
• 处理错误路径 -
• 自己审查实现不足
所以第二轮换成了一个更真实的工程题:
实现一个本地 Markdown 文章分析 CLI,叫 md-inspector。
它要递归扫描目录下所有 Markdown 文件,并输出文章质量报告。
需要统计:
- 文件路径
- 第一个一级标题
- 字数
- 链接数量
- 图片数量
- fenced code block 数量
- 是否包含摘要
- 标题是否过长
还要处理:
- 空目录
- 不存在目录
- 没有一级标题
- 多个一级标题
- 图片不能算普通链接
- 代码块里的链接和图片不能计数
- Windows 和 macOS/Linux 路径兼容
- 文件读取失败不能让程序崩溃,要进入 warnings
工程要求包括:
- TypeScript
- Node 内置模块
- 合理拆分文件
- 至少 8 个 Vitest 测试
- 说明如何运行
- 说明如何验证
- 列出需求假设
- 最后自我审查这个题比 LRU 更能测真实 Agent 能力。
因为它不是单点算法,而是一个小工程闭环。
GPT-5.3 Codex High:这轮最像成熟代码 Agent
在 Markdown CLI 任务中,表现最强的是 GPT-5.3 Codex High。
它的最终评分是:
8.7 分。
它先列出了假设:
-
• wordCount 按正文可读内容统计,所以排除 fenced code block 后再统计 -
• 中英混合标题过长规则按任一条件触发 -
• 只把 “` 当作 fenced code block 分隔符,不扩展到 ~~~ -
• 输出路径统一为相对输入目录的 POSIX 风格
然后给出实现计划:
-
1. 初始化 TypeScript CLI 工程 -
2. 拆分目录扫描、Markdown 分析、报告组装、CLI 入口 -
3. 实现空目录、不存在目录、无 H1、多 H1、代码块排除、读取失败 warning -
4. 补测试,跑 vitest 和 tsc -
5. 自我审查
项目结构也比较清楚:
package.json
tsconfig.json
vitest.config.ts
src/index.ts
src/file-scanner.ts
src/markdown-analyzer.ts
src/path-utils.ts
src/report.ts
src/types.ts
tests/report.test.ts它的测试有 10 个,覆盖:
-
• 空目录 -
• 不存在目录 -
• 无一级标题 warning -
• 多个一级标题只取第一个 -
• 图片不计入普通链接 -
• 代码块里的链接和图片不计数 -
• 标题过长 warning -
• 中文、英文、数字词数规则 -
• 文件读取失败写 warning 且不中断 -
• 路径标准化
实测结果:
-
• npm test 通过,10 个测试全部 pass -
• npx tsc –noEmit 通过 -
• CLI 对不存在目录输出 JSON warning,而不是直接崩溃 -
• 空目录输出空报告
这几个点很关键。
尤其是 tsc 通过和不存在目录进入 JSON warnings。
这说明它不是只写了看起来像样的代码,而是更接近真实工程交付。
扣分点也有:
-
• Markdown 解析仍是正则级别,不是 AST -
• wordCount 排除代码块是它自己的假设,虽然说明了 -
• 文件权限失败测试用 chmod 000,跨平台稳定性一般 -
• 子目录读取失败等扫描阶段局部失败还能更细
但总体看,GPT-5.3 Codex High 是这轮最完整的代码 Agent。
它不只是写功能,还完成了:假设声明、实现计划、模块拆分、测试、类型检查、运行验证、自我审查。
DeepSeek V4 Pro:能写可用工程,但收尾不如 Codex
DeepSeek V4 Pro 在 Markdown CLI 任务里也不错。
最终评分:
8.0 分。
它的项目结构合理:
md-inspector/
├── package.json
├── tsconfig.json
├── vitest.config.ts
├── src/
│ ├── index.ts
│ ├── types.ts
│ ├── scanner.ts
│ ├── parser.ts
│ ├── analyzer.ts
│ └── reporter.ts
└── tests/
├── index.test.ts
└── fixtures/它有 14 个测试,覆盖:
-
• 正常文章解析 -
• 无一级标题 -
• 英文标题过长 -
• 中文标题过长 -
• 摘要检测 -
• 代码块内链接和图片不计数 -
• 多个一级标题只取第一个 -
• 图片不算普通链接 -
• 空文件处理 -
• 中英文数字混合计数 -
• 纯数字串计数 -
• 集成测试 -
• 空目录 -
• 不存在目录检测
它也给出了运行方式:
npm install
npx tsx src/index.ts <目标目录>
npm test自我审查也比较具体,列出了:
-
• 嵌套括号链接解析不完美 -
• URL 会被计入字数 -
• 不支持缩进代码块 -
• 未闭合代码块会影响统计 -
• 摘要检测过宽 -
• 不支持 glob -
• CJK 范围可能误判 -
• 大目录没有并发优化
这些说明它有交付意识。
但 DeepSeek 输给 Codex 的地方也比较明确。
第一,TypeScript 工程没收好。
npm test 通过,但 npx tsc –noEmit 失败,因为缺少 @types/node,导致 node:fs/promises、process 等类型无法识别。
对 TypeScript CLI 来说,这是明显扣分项。
第二,不存在目录的处理不完全符合题目。
题目要求错误进入 warnings。
但 DeepSeek 的实现是直接 stderr 加 exit,不是输出 JSON report 里的 warning。
第三,扫描阶段失败没有充分局部容错。
它处理了单文件 readFile 失败,但 readdir 这类扫描阶段异常可能导致整体失败。
第四,CLI 层测试不足。
更多测试集中在模块内部,没有充分验证真实命令行 stdout、exit code、参数缺失、不存在目录等行为。
所以 DeepSeek V4 Pro 这轮像是:
能写出可用初版项目,但工程收尾和验收不够完整。
如果它修掉 tsc 和错误处理语义,评分可以接近 8.7。
这轮比 LRU 更能说明 Agent 能力。
因为它考察的是完整链路:
-
• 是否理解需求 -
• 是否声明假设 -
• 是否合理拆模块 -
• 是否能处理文件系统 -
• 是否能输出 CLI JSON -
• 是否能处理错误路径 -
• 是否写有效测试 -
• 是否通过 TypeScript 检查 -
• 是否能自我审查 -
• 是否做到实际可运行
GPT-5.3 Codex High 赢在工程闭环。
DeepSeek V4 Pro 赢在代码组织和测试覆盖,但输在 tsc 和错误语义。
最终结论:
GPT-5.3 Codex High > DeepSeek V4 Pro,但差距不大。
不足:
测到的主要是工程代码生成能力,还不是真正完整的 Agent 能力。Markdown CLI 测的是小型工程交付能力, GPT-5.3 Codex High 在这个小型 TypeScript CLI 工程交付任务中强于DeepSeek V4 Pro ,不能直接扩大成所有 Agent 场景。
还没充分测试:
-
• 工具调用策略 -
• 网络搜索 -
• 长链路任务 -
• 真实 repo 大规模修改 -
• 依赖冲突处理 -
• 多轮测试失败修复 -
• PR 质量 -
• Git 操作 -
• API 文档查阅 -
• 任务中途环境变化 -
–end–
最后记得⭐️我,每天都在更新:如果觉得文章还不错的话可以点赞转发推荐评论
/…@作者:你说的完全正确(YAR师)
