
这两个月我笔耕不辍,前前后后写了几十篇AI实战文章。没想到先后有两位出版社的策划编辑找上来,都想聊合作出书的事。
说实话挺意外的。
回头看了一下后台数据,我之前那篇Harness实战的文章被不少人转发分享。
Harness Engineering 实战:harness的最佳理解方式
我稍微调研了下,中文市场上确实没有一本系统讲Harness企业级实战的书。而且Claw Code的Rust版源码确实值得借鉴,它忠实还原了Claude Code的架构设计。
所以我做了一个决定:接下来一个半月,推出6-8篇Harness实战的系列文章。如果出版社合作谈得顺利,这些内容会整理成一本书。谈不成也没关系,最终会以完整的系列形式上架微信读书。
这篇是个引子。用同一个编码任务,分别丢给Claude Code、Codex和Claw Code三个Harness,观察下Harness架构本身的实战差异。
任务是这样的:Claw Code仓库里有一个CostTracker类,代码写好了但没被任何模块引用。我让三个Agent做同一件事,把它集成到Agent运行流程中,改三个文件,写测试,跑通现有用例。
三个Harness拿到的任务描述一模一样,都是同一份TASK.md。
先说Claude Code。
它的第一个动作是读CLAUDE.md,我专门为这个项目写的上下文文件。然后读TASK.md,接着自己去翻了三个源文件。
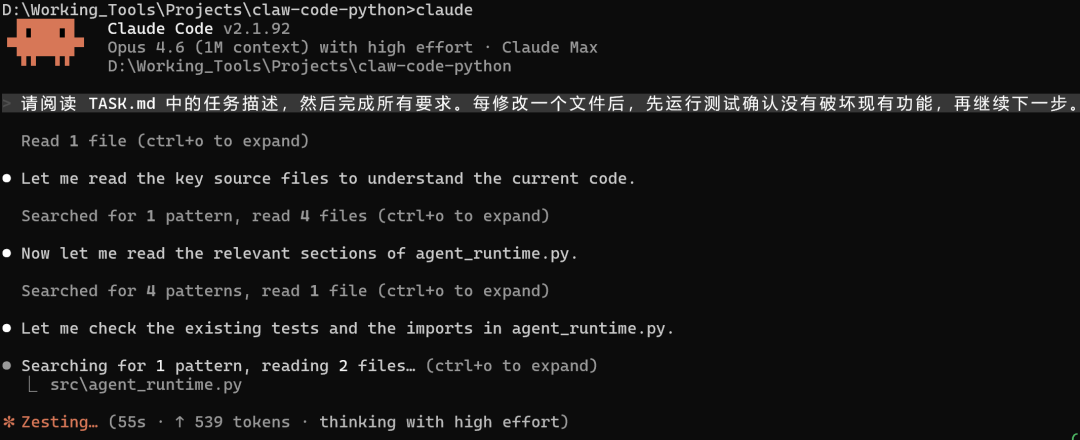
读完之后它发现已有测试里有个失败用例。我以为它会停下来问我怎么办。
它自己判断了一下,"这是pre-existing的,不影响我的任务"。继续干活。
改完cost_tracker.py之后,它开始改agent_runtime.py,把CostTracker的导入和调用插到了正确的位置。

写集成测试的时候出了个小插曲。mock了一个不存在的方法名,pytest报错。
它没有停下来等我指示,而是自己看了报错信息,说了一句"The method _build_tool_specs doesn't exist. Let me find the correct method name",然后自己修了重跑。
改、测、错、分析、再改、再测。这个循环是自动的。
最终488个测试全部通过。改了4个文件,新增13个测试。零次人工介入。
说说Codex。
Codex拿到任务后,第一件事是用rg --files扫项目结构。有意思的是,我专门准备了AGENTS.md这个文件,它完全没读。直接从文件列表和TASK.md里拿信息就够了。
权限交互跟Claude Code不一样,Codex会有一个独特的沙箱权限的弹出提醒。
中间遇到了一个坑。pytest在沙箱环境里被Windows防火墙拦了。Codex自己绕过去了,换了一种方式直接跑指定测试文件。
最终78个测试全部通过,跑了7分钟左右。比Claude Code慢,但也是一轮搞定。
最后是Claw Code + DeepSeek。
这一轮用的是Claw Code的Rust版本,通过DeepSeek的Anthropic兼容协议接入。启动画面说实话挺唬人的,ASCII艺术的CLAW logo,彩色TUI界面,看着跟Claude Code的体验很像。
DeepSeek读完TASK.md后列了一个很清晰的四步计划,甚至识别了"第574行附近"这样的具体位置。到这里为止,我觉得有戏。
然后问题来了。它想用bash命令扫描文件。
bash: program not found.
Windows上找不到bash。它自己切了策略,改用内置的read_file直接读源码。
接下来读完agent_runtime.py之后,要改文件的时候,屏幕上弹出一行红色报错。
炸了。
它还试图继续,改了cost_tracker.py,说"现在我已经完成了步骤1,接下来是步骤2"。但上下文已经超限了,后面注定失败。
这里面最让我在意的,不是它失败了,是同样接DeepSeek,Claude Code就没这个问题。
为什么?
我去读了Claw Code的Rust源码。crates/api/src/providers/mod.rs第208行,有个model_token_limit函数。里面只注册了Claude和Grok两个系列。
_ => None, // deepseek-chat走到这里,返回None
返回None之后,第227行的preflight预检函数直接跳过了。不认识这个模型,那就不检查了。
请求带着64000的max_output_tokens发出去。DeepSeek只有128K窗口,光输出就占了一半。加上几轮对话累积的上下文,直接超了。
API返回400,Claw Code把它当成普通错误终止了。没有尝试压缩上下文重试。
而Claude Code为什么没事?因为它在发请求之前就做了上下文预算管理,快到窗口限制时主动压缩。这套机制在Claw Code的源码里也有,conversation.rs的maybe_auto_compact函数。
架构完全一样。
就是模型注册表里少了几行配置,三道防线全部失效。
反观Qwen Code(阿里的开源CLI工具)的同一份功能,tokenLimits.ts里覆盖了十几家模型,DeepSeek、GLM、Kimi、MiniMax全在。
简单总结一下这次实验:
Claw Code翻译了Claude Code的架构。Prompt Cache边界、三层权限、条件式上下文注入、双重压缩机制,都在。
卡就卡在最后一公里的工程化上。
这也是我做这个系列的原因。后续文章会按这个节奏展开:
第二篇:Claw Code源码拆解。逐层拆Claw Code的Rust版架构,重点分析四个模块:权限门控、上下文发现、Prompt Cache边界设计、反应式压缩机制。这是后续所有实战的基础。
第三篇:国产模型接入实战。动手修复Claw Code的模型注册表和Provider接线,让DeepSeek和Qwen跑通同样的任务。把今天失败的Round 3变成成功。
第四篇:用Harness做遗留系统重构。选一个真实的开源项目,用Harness驱动Agent完成跨文件重构,全程记录约束设计、验证机制、回退策略。
后续还有:自动化测试生成、多Agent协作、成本控制与可观测性。每一篇都是从源码出发,在真实场景落地。
如果你对AI应用的底层实现感兴趣,对怎么让Agent从"能跑"变成"靠谱"这件事有需求,这个系列应该能帮到你。
当然你有特别关注的实战场景也欢迎随时联系我。
架构是骨架,细节是血肉。少了哪个,Agent都站不起来。
