

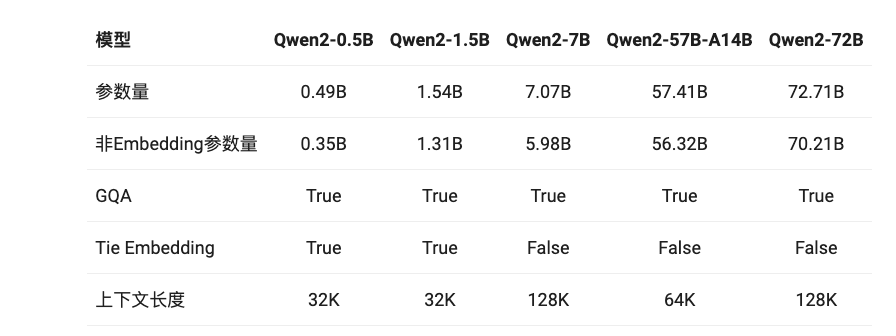
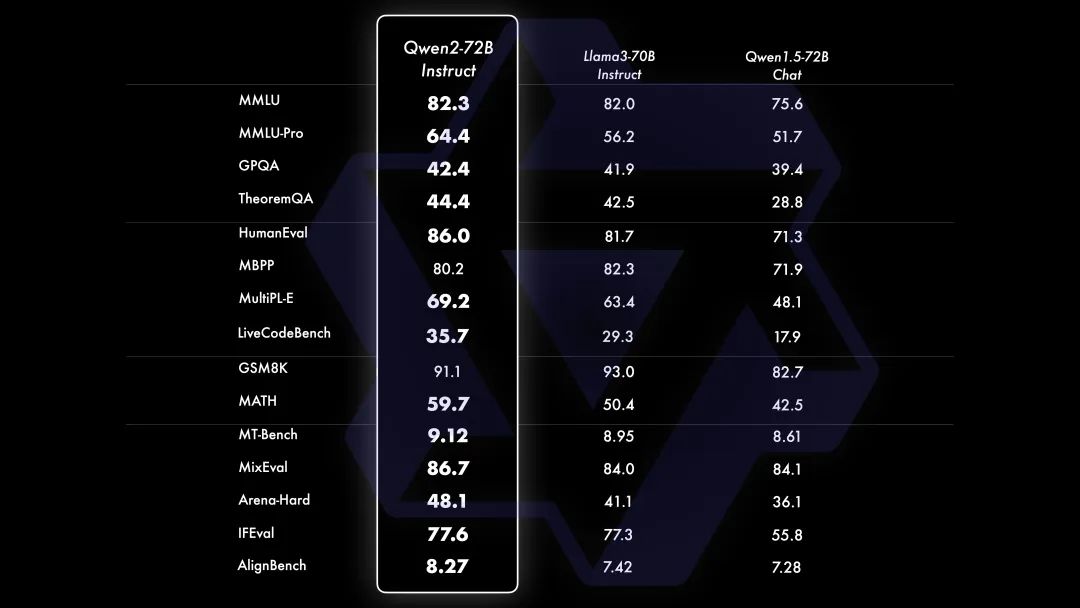
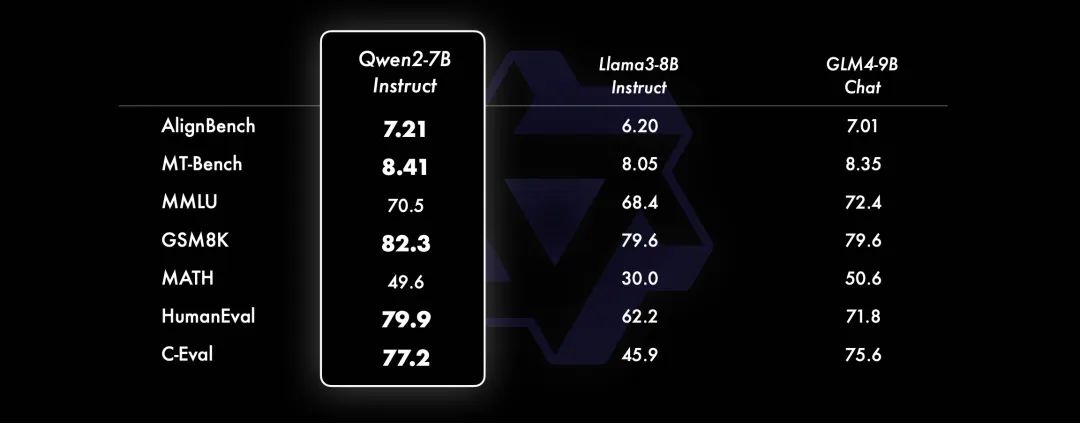
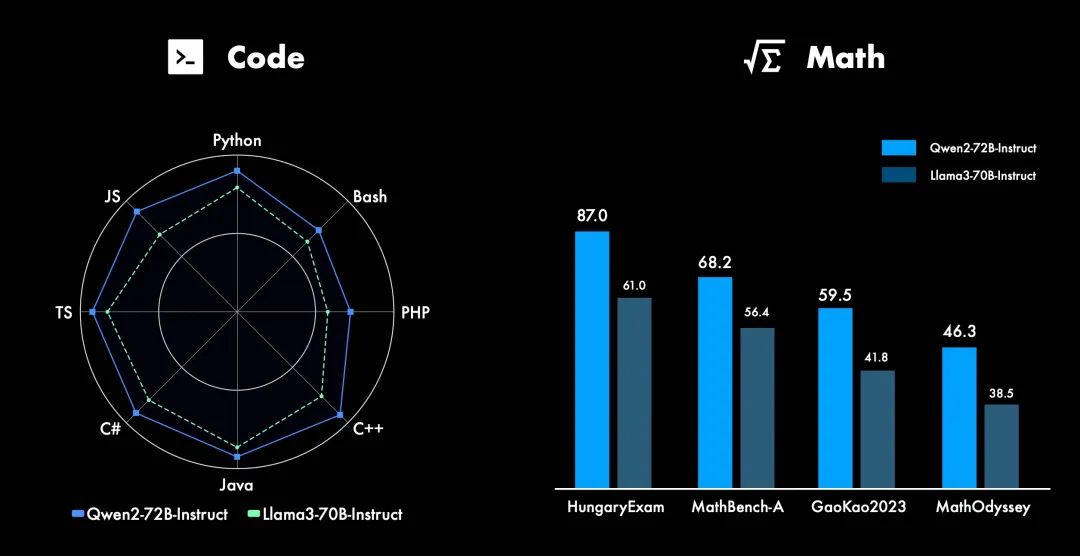
经过数月的努力,阿里云今天发布了Qwen2,包括: 5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B; 在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据; 多个评测基准上的领先表现; 代码和数学能力显著提升; 增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。 目前,Qwen2已在Hugging Face和ModelScope上同步开源。以下是核心信息:
//



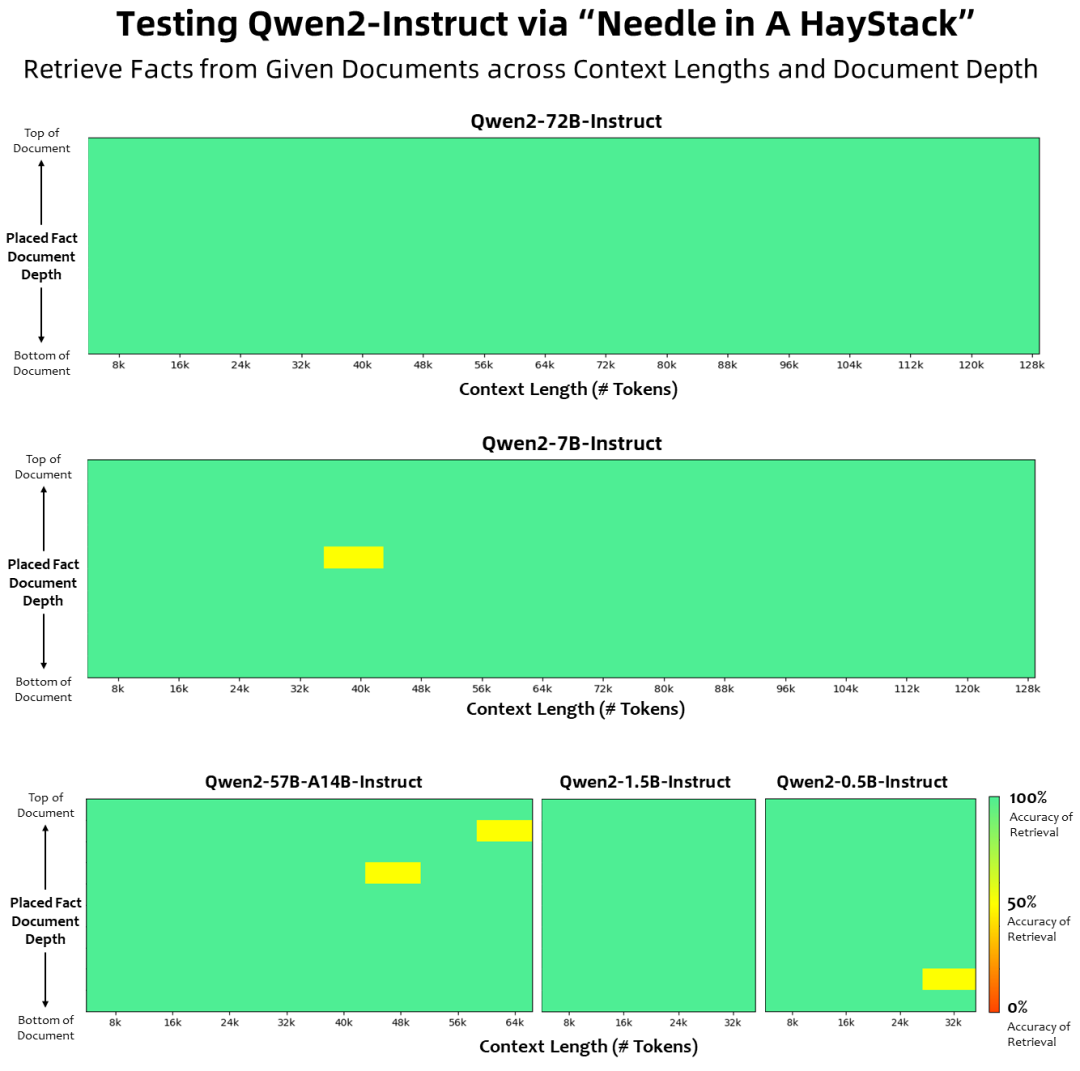

3.Qwen2的下一步是什么?
Qwen团队表示,还在训练更大的模型,继续探索模型及数据的Scaling Law。此外,还将把Qwen2扩展成多模态模型,融入视觉及语音的理解。在不久的将来,还会继续开源新模型。
– end –
