

如果你还在写提示词(Prompt),并期望AI能完成复杂的项目,那你一定也体会过各种无奈!未来谁能用好AI,不在于提示词工程 (Prompt Engineering),而在于如何更好地编排智能体工作流 (Agentic AI Workflow)。
吴恩达这门课程,旨在教会你如何搭建一个能自我规划、使用工具、迭代改进的AI系统,真正让AI像有效的专家团队那样自主工作。本文将深入解读这门课程的核心内容,带你掌握构建Agentic AI系统的四大设计模式和实战工程化技巧。
一、为什么需要自主智能体 (Agentic AI)?
-
规划多步骤流程:将大任务拆解成可执行的小步骤。 -
迭代执行:在每一步执行后进行检查和改进。 -
自我优化:通过自我反思和工具使用来提升最终输出的质量。
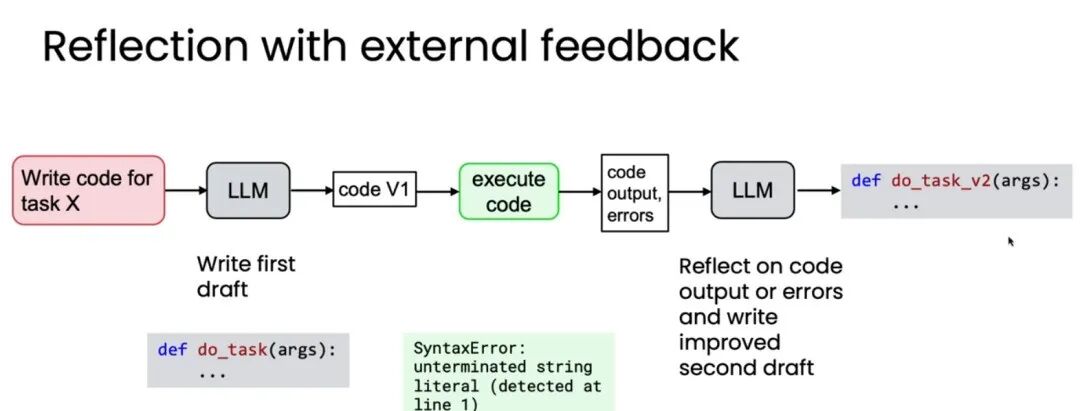
反射 (Reflection) 允许AI评估自己(或其他AI)的工作并反馈结果,让AI系统自主迭代和自我改进。大白话讲,就是将AI生成的内容作为输入,给到(不同)AI进行审查并输出审查结果。
反射能基于预设标准,也可引入外部反馈(external feedback)。比如把AI生成的代码在外部运行,将运行结果与代码一起交给AI审核,能大大提高反射的准确性和可靠性。
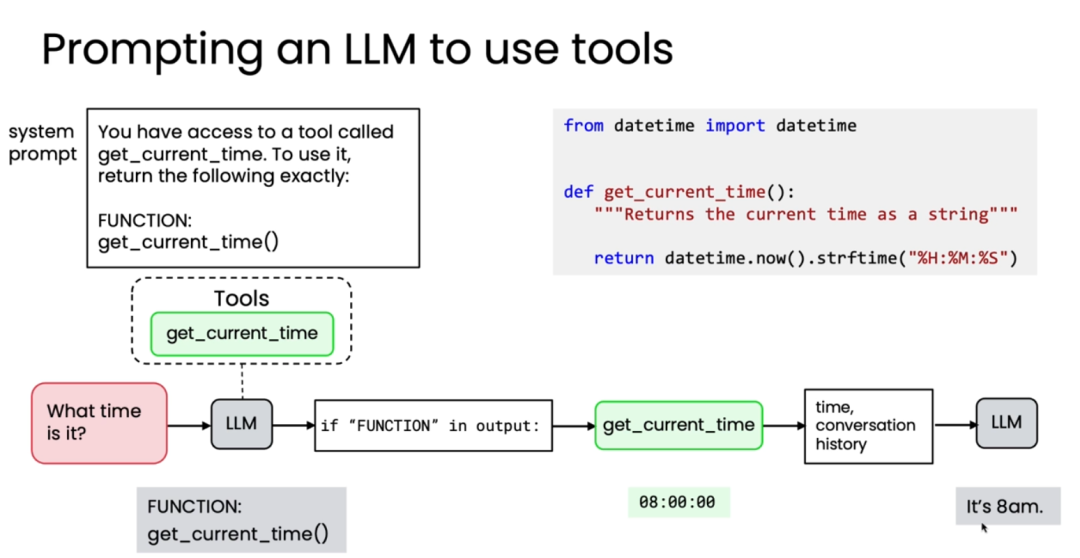
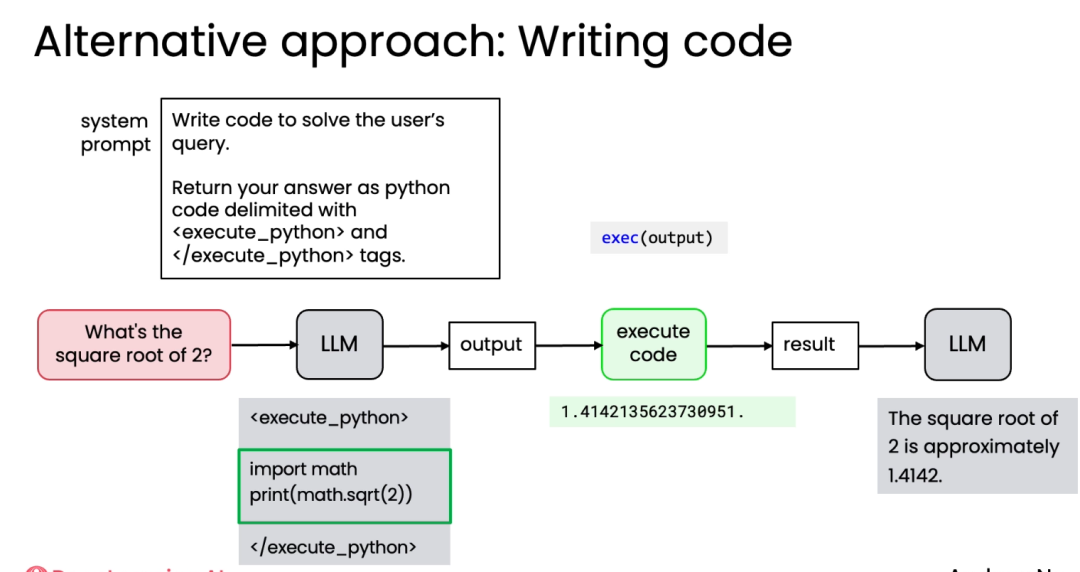
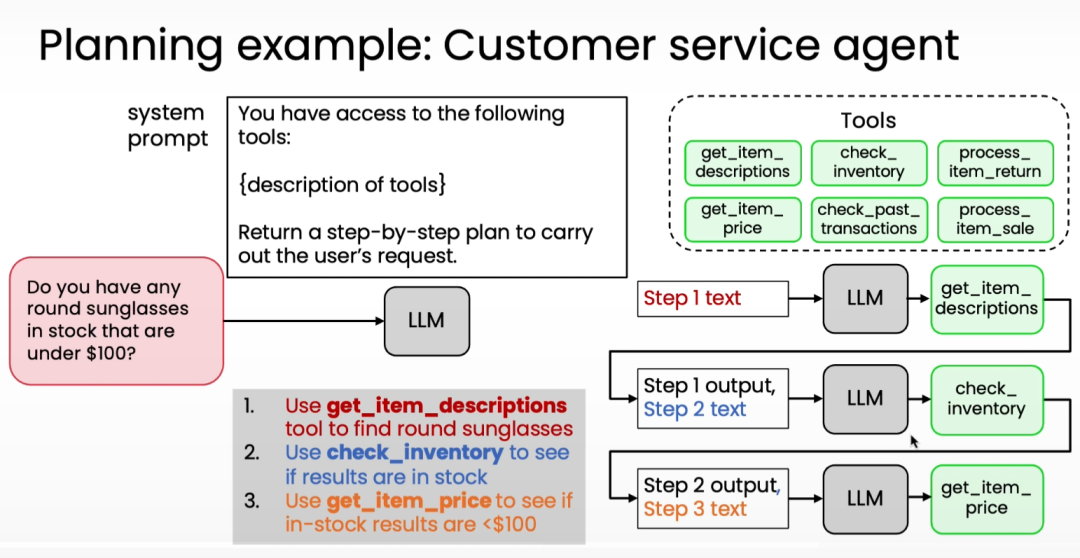
-
步骤怎么分, 怎么编排?这不仅是技术问题,更是对业务知识和常识的考验。这也是AI时代对技术同事的新要求。课程中也提到对于部分场景,可交由LLM实时进行规划。 -
步骤间交付/传递什么?从效果来讲,代码 > JSON格式输出 > 自然语言
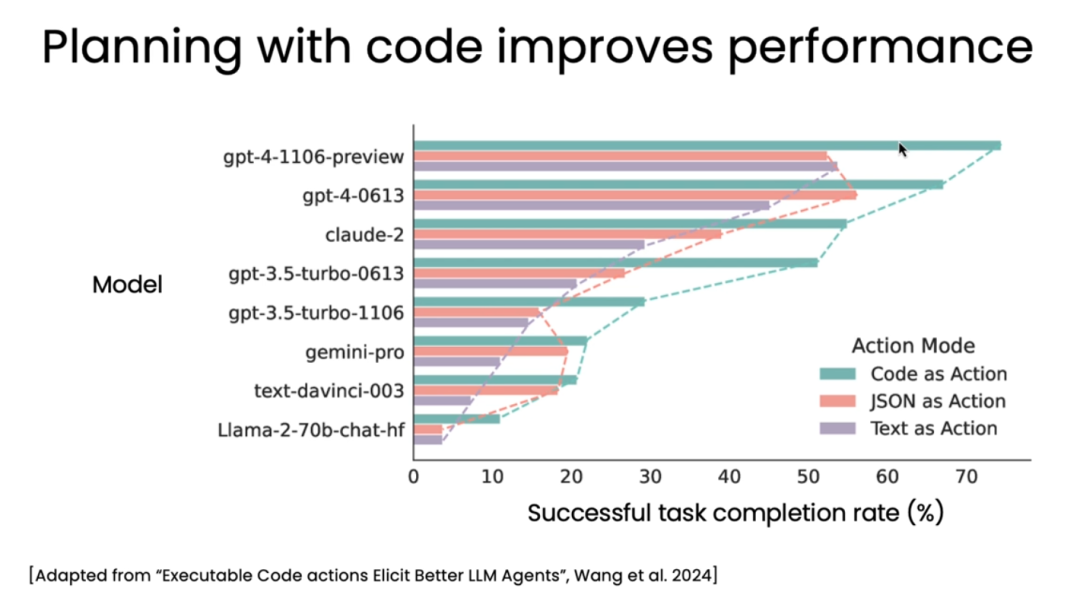
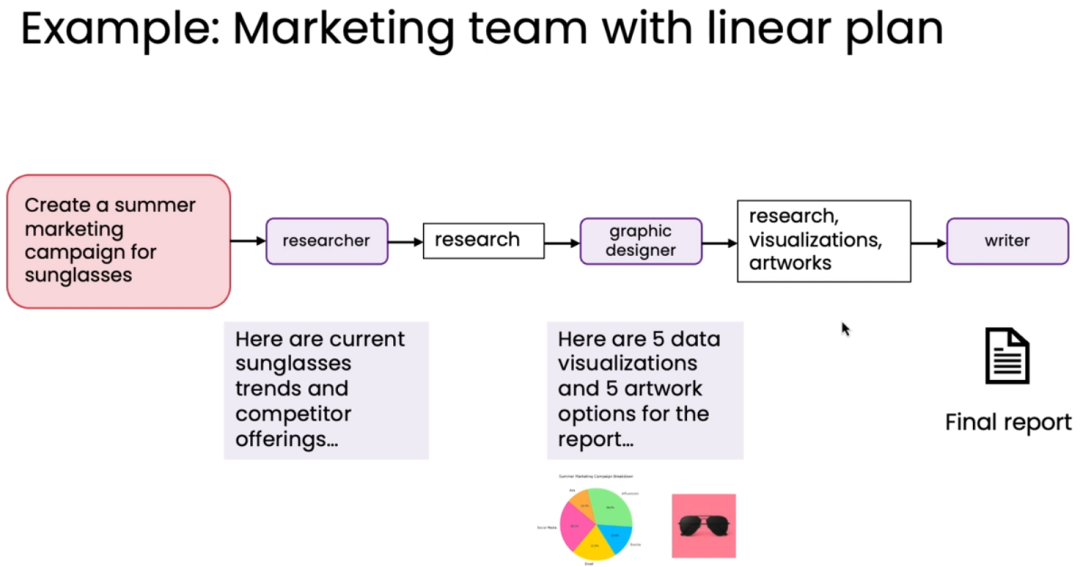
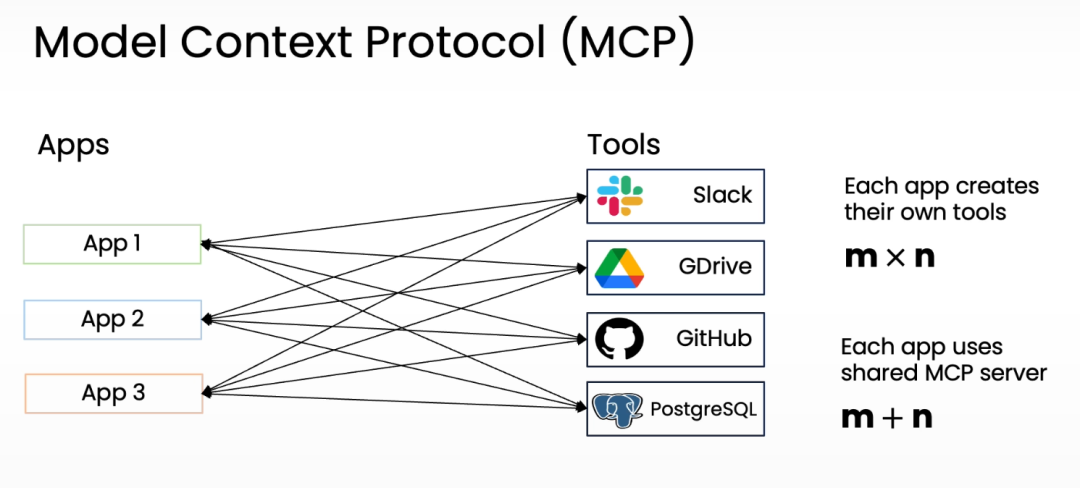
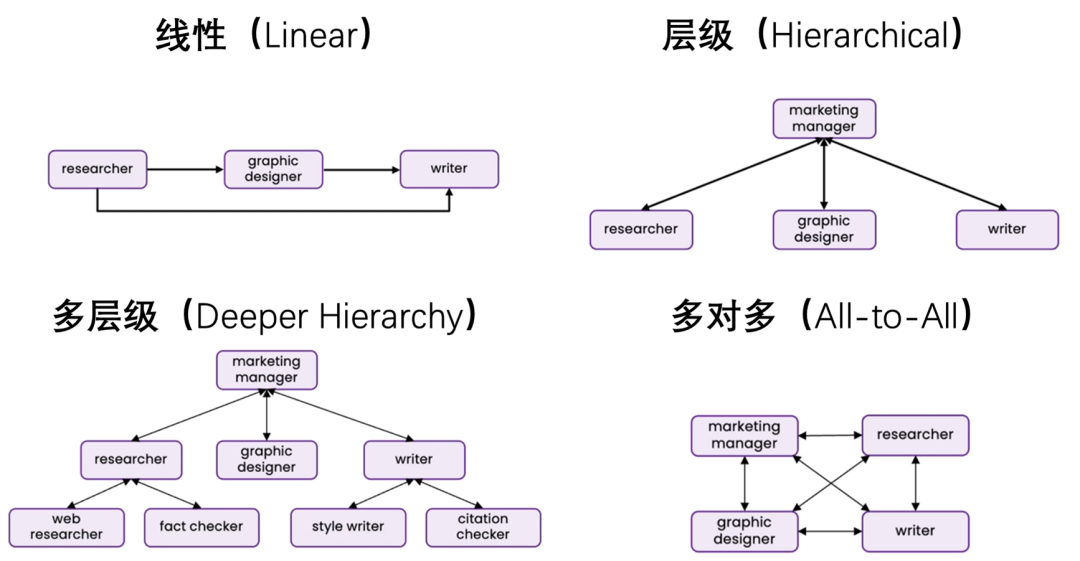
其中的要点在于如何设计多智能体系统间的沟通模式 (Communication patterns),从而实现更高效、更深入的协作。课程中提到了四种方式:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
课程中总结了一套简单的评估流程:
-
定义标准:明确什么是“好”输出,例如文本质量或数据准确性;
-
从小规模样本开始:先用 20~50 个样本快速发现问题,有时直接肉眼识别即可;
-
选择评估类型:客观评估 – 当任务有明确标准时,编写测试代码计算准确率;主观评估 – 用另一 LLM 根据评分标准打分,如图表是否有标题、是否使用合适的图表类型
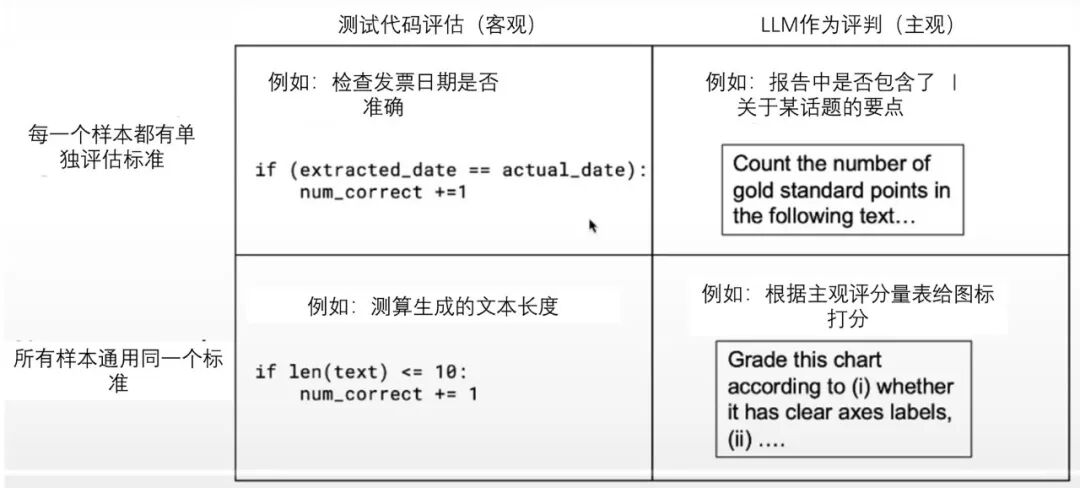
此外,评估可分为端到端和组件级。端到端测试适合体验整套工作流,但成本高;组件级评估则更有针对性,有助于快速定位问题。
