


一、Policy 模块:给 Agent 装 “权限防火墙”,精准管控每一次工具调用
核心能力:细到参数级的精准管控
简单说,Policy 能明确界定 “什么角色的 Agent,在什么网关下,调用什么工具时,满足什么参数条件才能通过”。比如电商场景中,可直接设置 “仅‘退款 Agent’能调用退款工具,且单笔金额低于 200 美元才允许执行”,从源头避免越权操作和资金风险。
实用亮点拉满
-
规则定义门槛低:无需复杂编码,支持 Cedar 策略语言或自然语言生成,可实现工具级、操作级、参数级的多层级管控
-
智能策略校验:自动识别过宽、过严或无法满足的无效规则,规避权限漏洞与业务阻塞风险
-
高效灵活部署:毫秒级权限评估响应,不影响 Agent 运行效率;支持生产环境强制执行与调试环境日志输出双模式,适配全开发周期
-
按需付费模式:无预付要求与最低消费限制,单次授权请求收费 0.000025 美元,每 1000 个输入 Token 收费 0.13 美元,中小团队可轻松负担
竞品对比:力压 AgentKit,权限管控更极致
目前 AgentKit Gateway 尚未支持工具级、操作级、参数级的细粒度控制,仅能做基础权限管理;而 AgentCore 已实现全链路精准管控,且底层联动网关可直接落地,反观 AgentKit 还在规划权限网关 + 策略池方案,短期内难以追平差距。
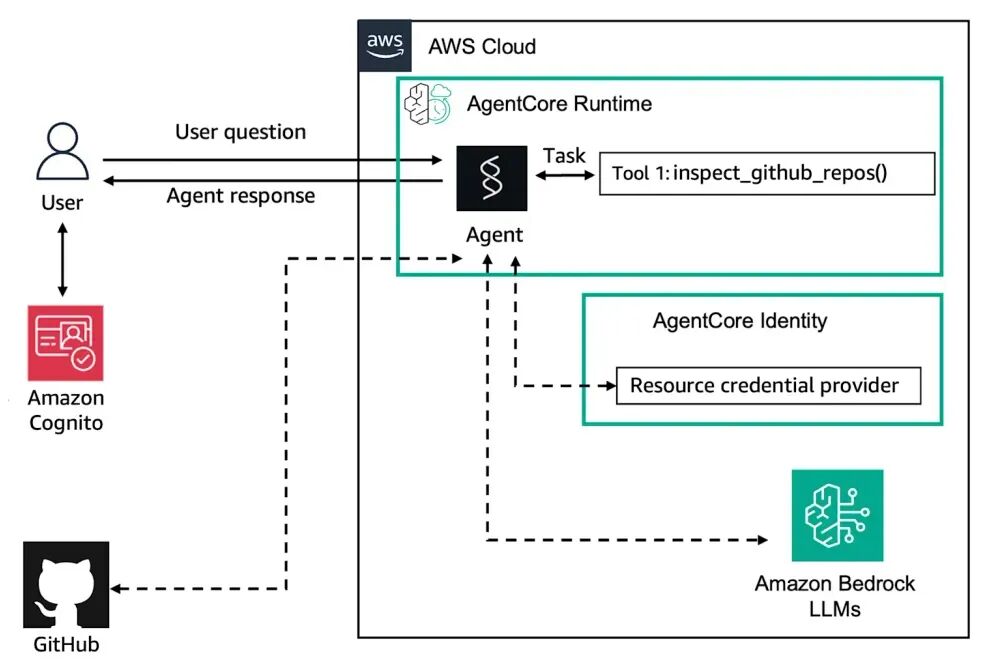
二、Evaluation 模块:双模式评测,打通 “开发 – 上线 – 监控” 全闭环
AI Agent 质量参差不齐,上线后效果不可控?Evaluation 模块直接给出解决方案,支持 On-Demand 和 Online 两种评测模式,覆盖从开发到运维的全场景:
两大核心评测模式
- On-Demand Evaluation(按需评测)
适配 CICD 场景,Agent 上线前做 “质量准出” 检测,支持轨迹评测(过程合规性)和端到端结果评测(效果达标率),避免不合格 Agent 流入生产 - Online Evaluation(线上评测)
基于 AgentCore 观测的日志数据,实时监控线上 Agent 运行质量,及时发现权限异常、工具调用失效等问题
评测能力灵活适配
内置 13 个预置评估器,覆盖合规性、准确性、效率等核心维度,还支持自定义模型评估器,满足企业个性化业务场景需求。对比来看,火山评测虽支持 50 + 预置评估器和代码评估器,但 AgentCore 的双模式评测更贴合 “开发 – 上线” 闭环,且能与自身可观测性模块深度联动,数据流转更高效。
