
一个在多个SOTA基准测试中表现卓越的企业级长期记忆操作系统
引言
在AI Agent时代,记忆不再是简单的"存储与检索",而是需要理解、推理和演化的能力。EverMemOS(EverMind Memory Operating System)作为一个智能记忆操作系统,在多个权威基准测试中取得了突破性成绩:
-
NQ320K检索任务:Recall@1达到75.5%,刷新SOTA记录 -
LoCoMo推理基准:92.3%准确率,超越现有方法 -
2wiki & Hotpotqa:ReRank模型分别达到0.758和0.7802的F1分数
更重要的是,EverMemOS提出了全新的记忆构建范式——从传统RAG的机械切分,转向LLM驱动的语义完整性记忆单元,让AI真正拥有"记忆"而非"缓存"。
一、核心创新:层次化记忆架构
1.1 MemCell:智能记忆的基石
与传统RAG系统按固定长度(如512 tokens)机械切分文本不同,EverMemOS引入了MemCell(记忆单元)概念。MemCell不是简单的文本片段,而是一个语义完整的结构化对象: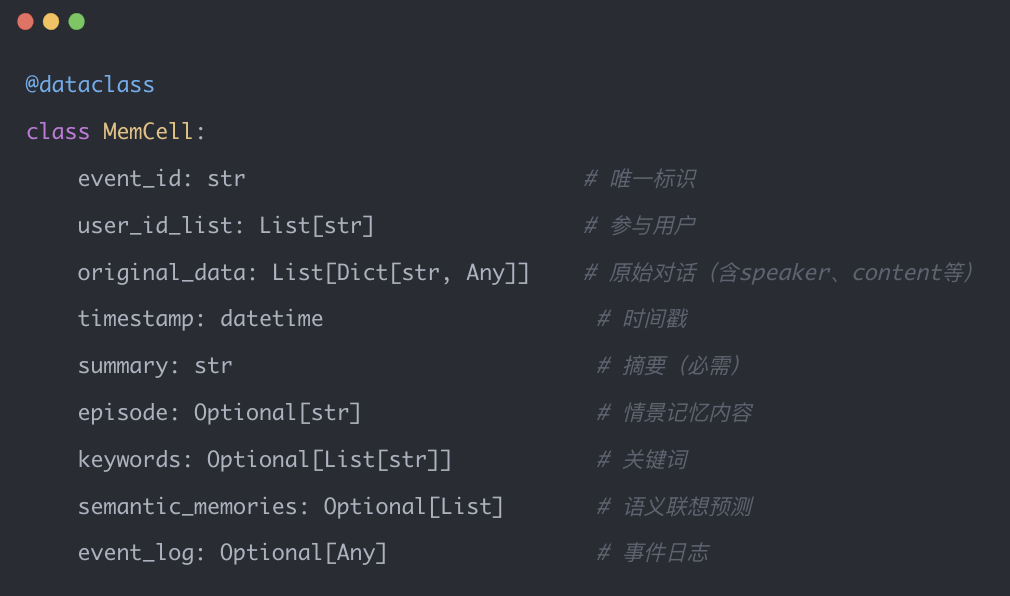
关键特性:
-
LLM驱动的边界检测:通过prompt引导LLM判断对话是否形成完整主题,返回 should_wait标志决定是否累积更多消息 -
保留对话上下文: original_data存储完整消息列表,包含speaker_id、speaker_name等元信息 -
前瞻性语义联想: semantic_memories字段预测用户未来行为变化(如"用户下周需要调整饮食习惯")
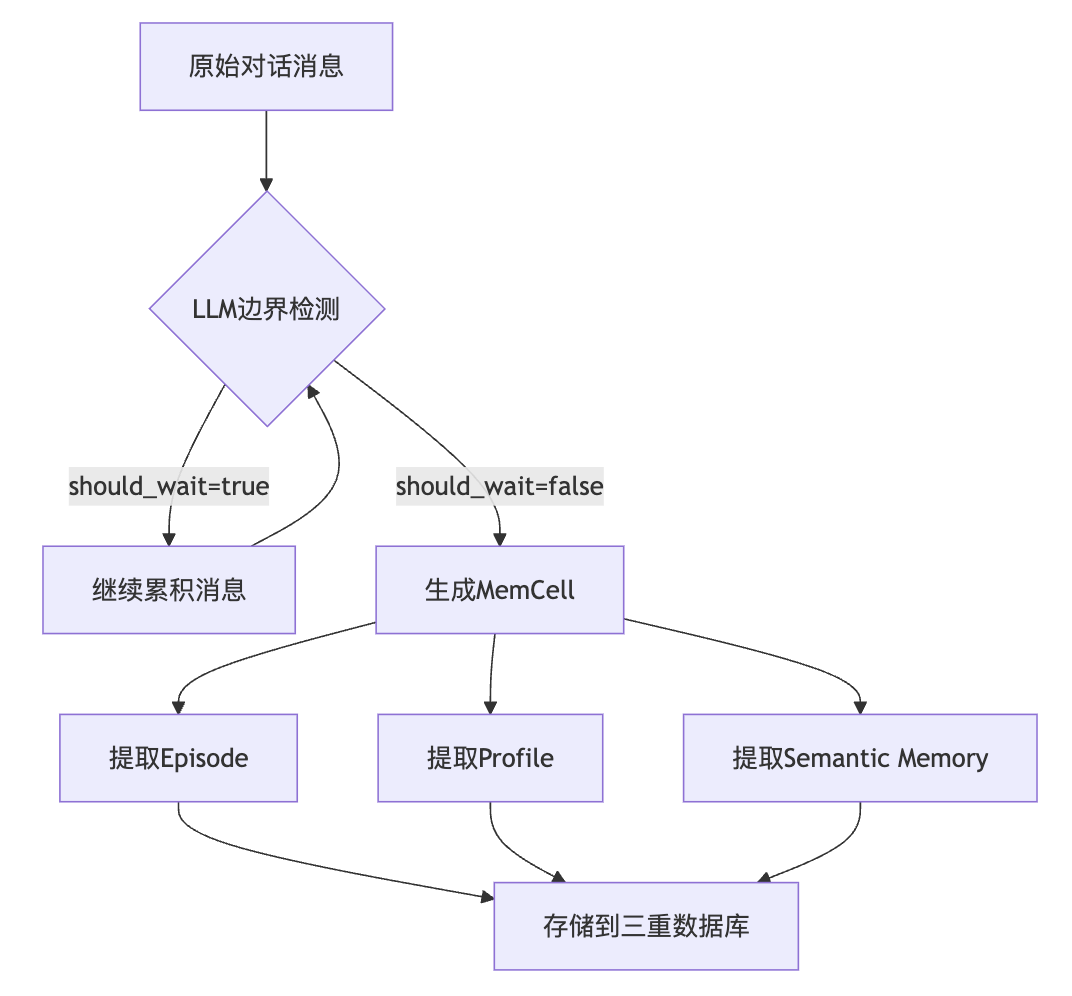
1.2 层次化记忆构建
EverMemOS采用三层记忆架构,每一层承担不同的认知职责: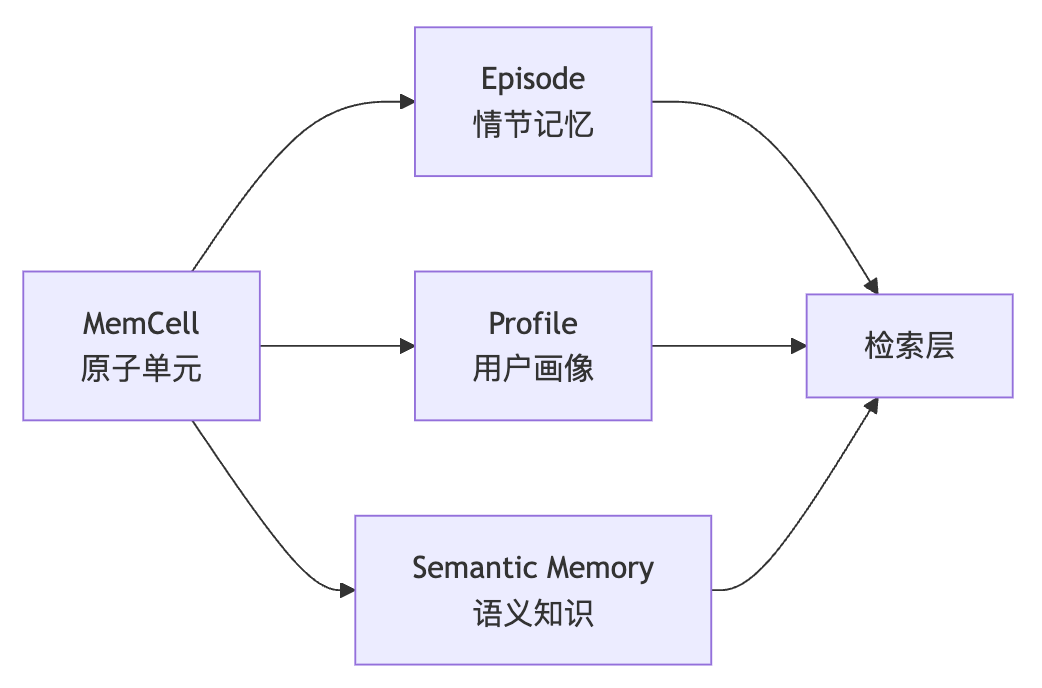
|
|
|
|
|
|---|---|---|---|
| MemCell | memcells |
|
|
| Episode | episodic_memories |
|
|
| Profile | core_memories |
|
|
| Semantic Memory | semantic_memories |
|
|
与传统RAG的本质区别:
-
传统RAG:文本 → 机械切分 → Chunk → 直接检索 -
EverMemOS:对话 → LLM边界检测 → MemCell → 聚合成Episode → 检索Episode
这种设计使得检索结果不再是碎片化的文本块,而是语义完整、结构化的记忆片段。
二、系统架构:四数据库协同设计
EverMemOS采用多数据库协同架构,每个数据库承担特定职责: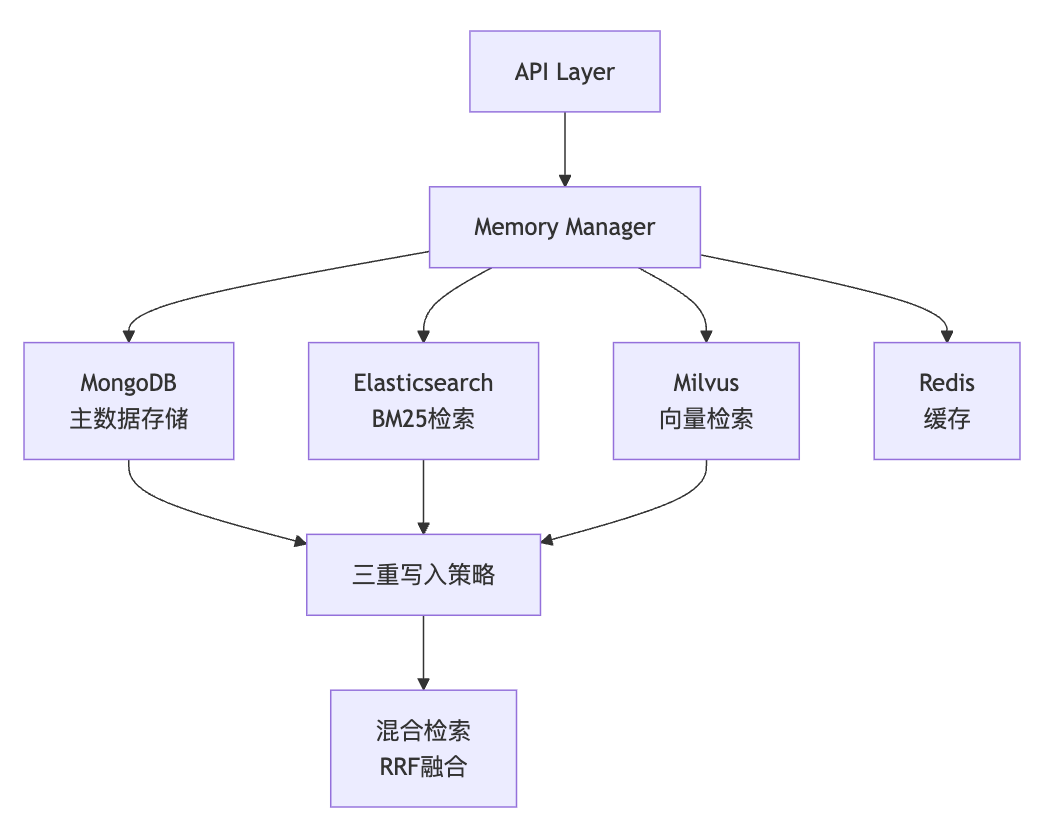
2.1 三重写入策略
核心记忆类型(Episode、Profile等)采用同步写入MongoDB、Elasticsearch和Milvus: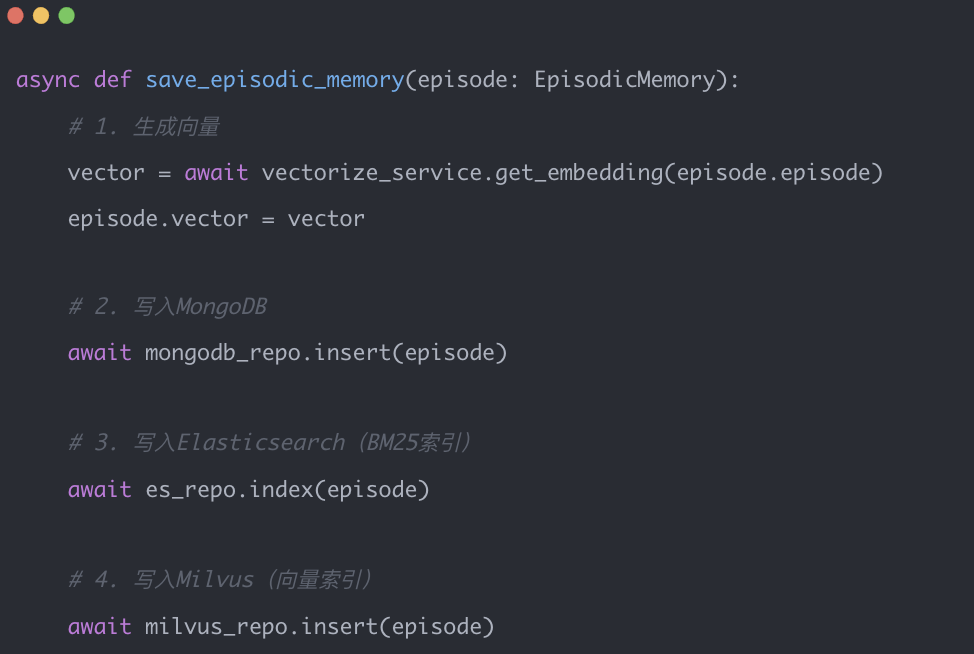
优势:
-
MongoDB:灵活的文档存储,支持复杂查询和事务 -
Elasticsearch:高效的BM25关键词检索,处理精确匹配 -
Milvus:高性能向量检索,支持语义相似度搜索
2.2 混合检索:RRF融合
EverMemOS采用Reciprocal Rank Fusion(RRF)融合Embedding和BM25结果,K值统一设置为60:
检索流程: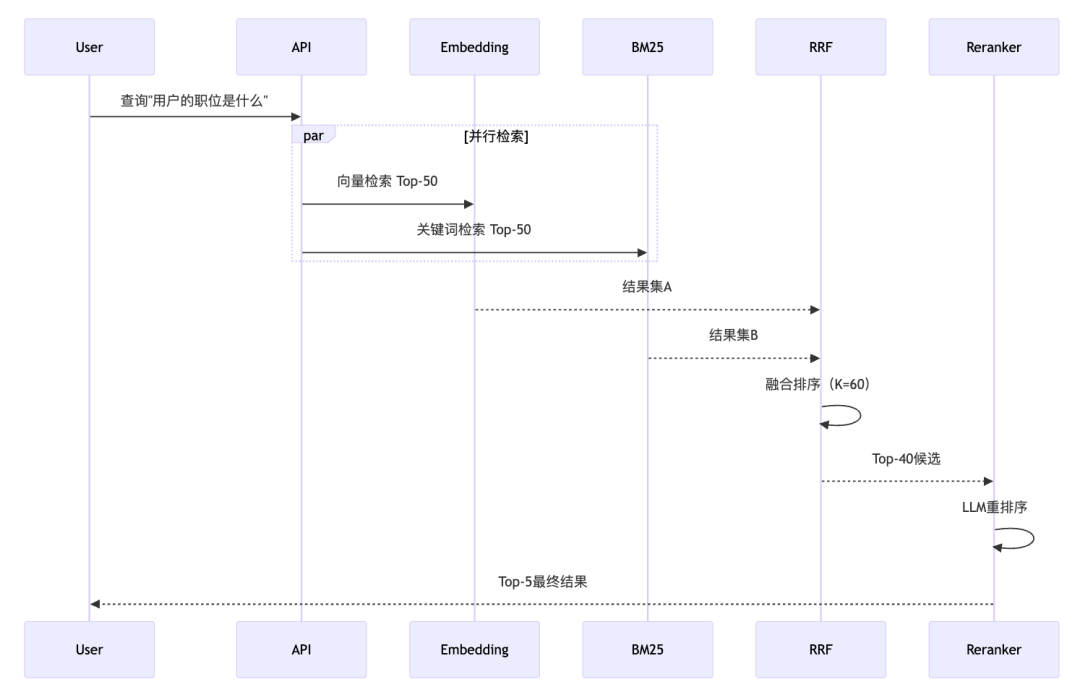
三、突破性能表现
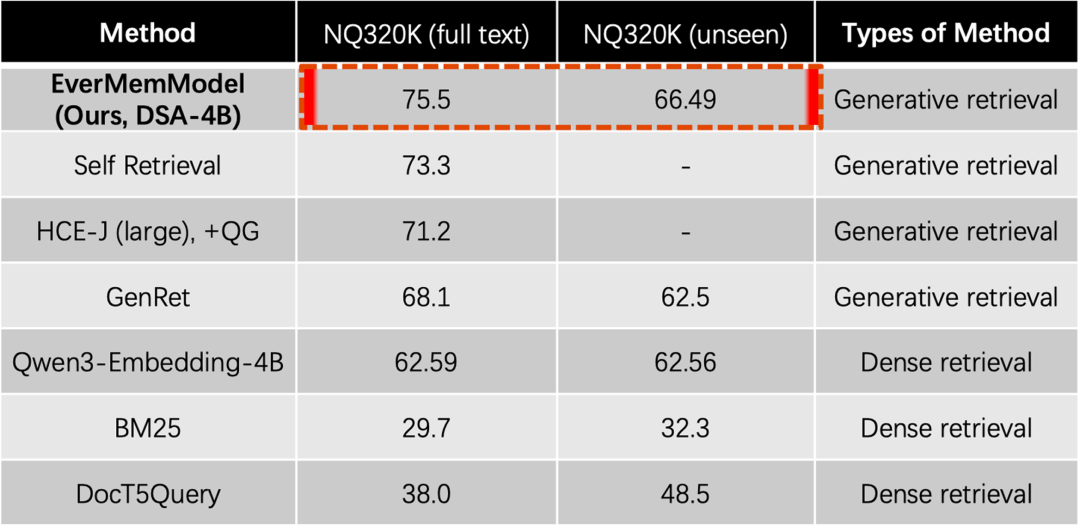
3.1 NQ320K:整库直接输入的检索
EverMemModel实现了将整个检索数据库连同查询一起输入模型的技术突破,在NQ320K(全文本)上达到:
-
Recall@1: 75.5%(训练集) -
Recall@1: 66.49%(未见测试集)
QA任务表现:DSA方法直接在7.1M长度上下文中进行QA,无需Embedding检索,超越了Qwen3-Embedding-4B + Qwen3-4B-Instruct的RAG方法: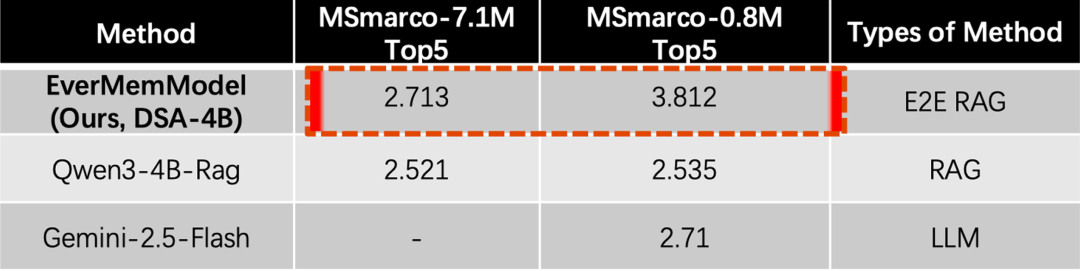
3.2 LoCoMo:92.3%的推理准确率
基于EverMemOS框架和GPT-4.1-mini模型,在LoCoMo数据集上实现92.3%的推理准确率(LLM-Judge评估),体现了三大核心优势: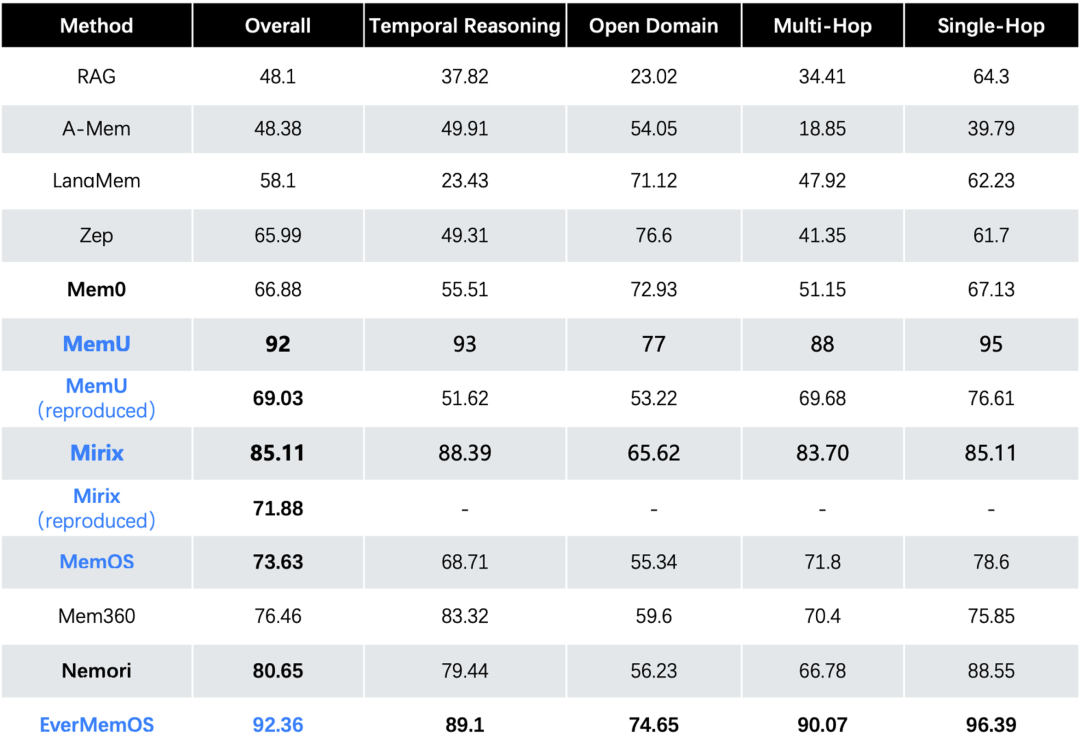
Coherent Narrative(连贯叙事)
-
自动链接对话片段形成完整主题上下文 -
区分"项目A进度讨论"和"团队B战略规划" -
从碎片化短语到完整故事线
Evidence-Based Perception(基于证据的感知)
-
主动捕获记忆与任务的深层关联 -
示例:用户提问"推荐餐厅" → 系统回忆"两天前拔牙手术" → 推荐软食餐厅 -
这是真正的情境感知
Living Profiles(动态演化画像)
-
实时更新用户画像,而非静态标签 -
偏好、语气、关注领域随交互自然演化 -
不只是"记住你说过什么",而是"学习你是谁"
3.3 ReRank模型:刷新多跳推理SOTA
EverMemReRank在两个多跳推理基准上达到SOTA:
|
|
|
|
|
|---|---|---|---|
| 2wiki |
|
|
|
| Hotpotqa |
|
|
|
核心技术:Event Log的多行格式化策略,将atomic_fact逐行展开: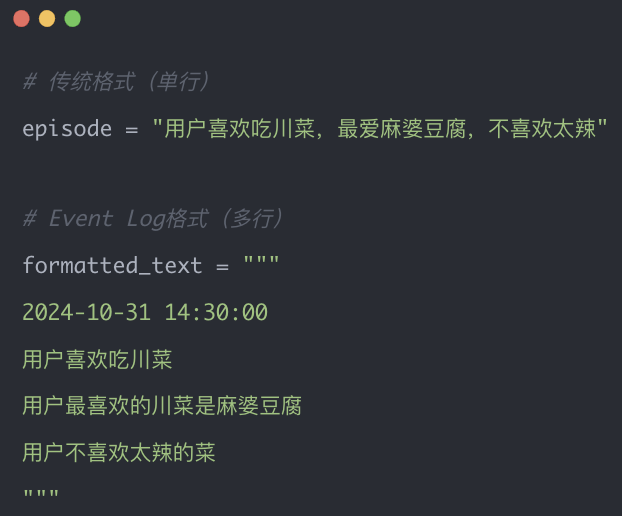
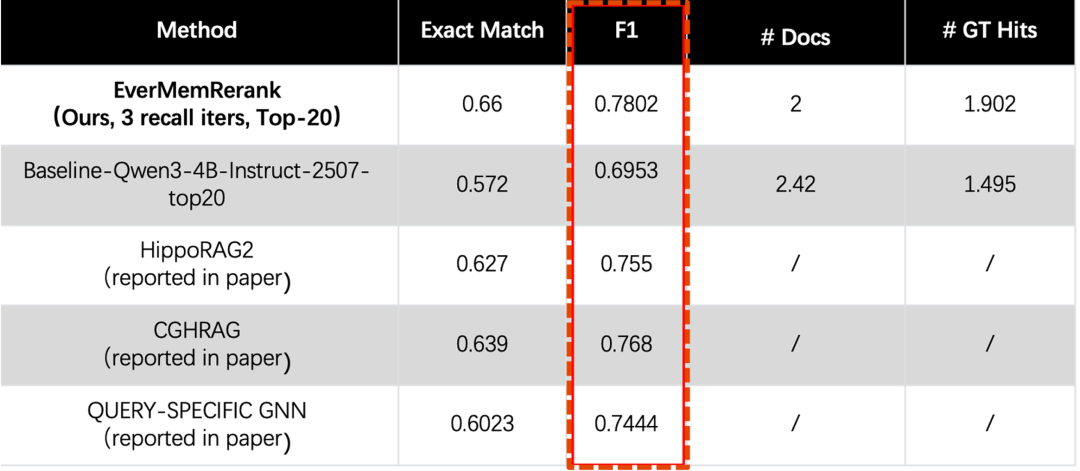
这种格式使Reranker能够精确匹配到具体的原子事实,避免语义稀释。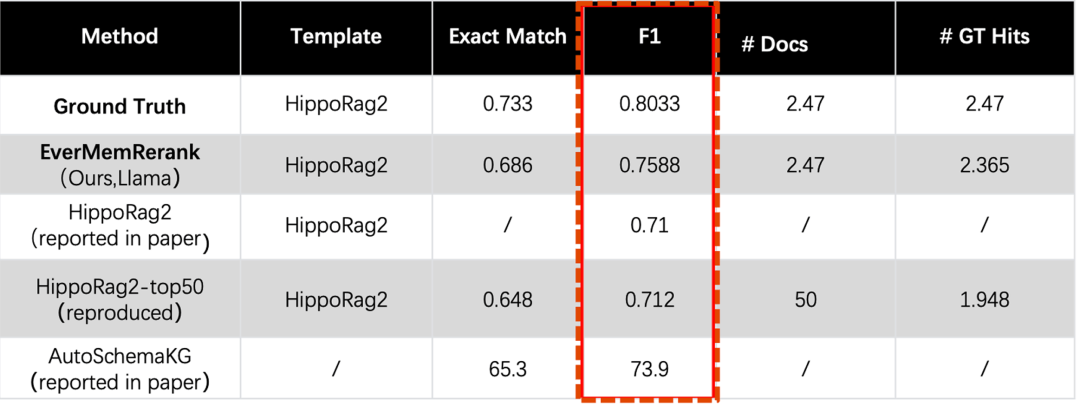
四、生产部署实践
4.1 本地模型替换
EverMemOS支持将DeepInfra API替换为本地部署模型:
Embedding替换(BGE-M3):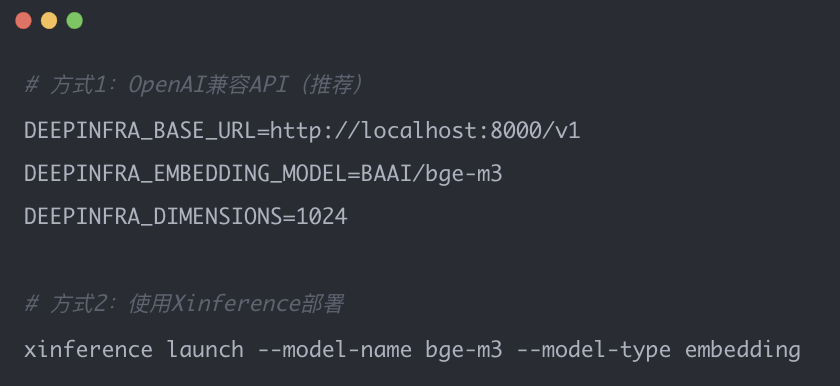
Reranker替换(bge-reranker-v2):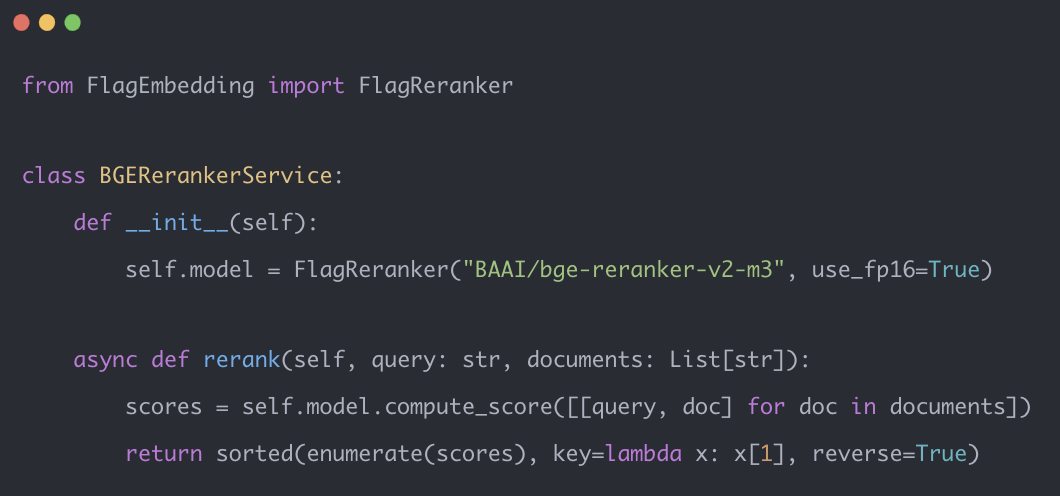
LLM替换(vLLM部署的Qwen):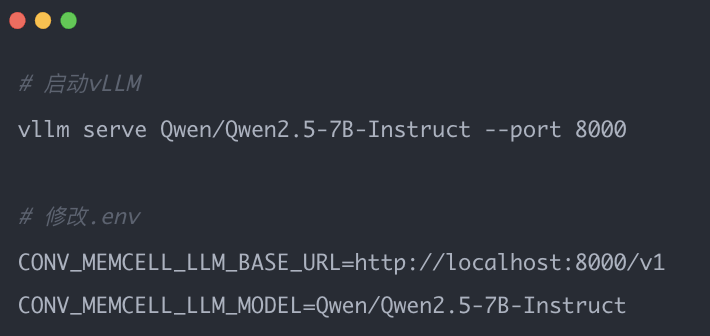
4.2 向量数据迁移
更换Embedding模型后,必须重新生成向量数据: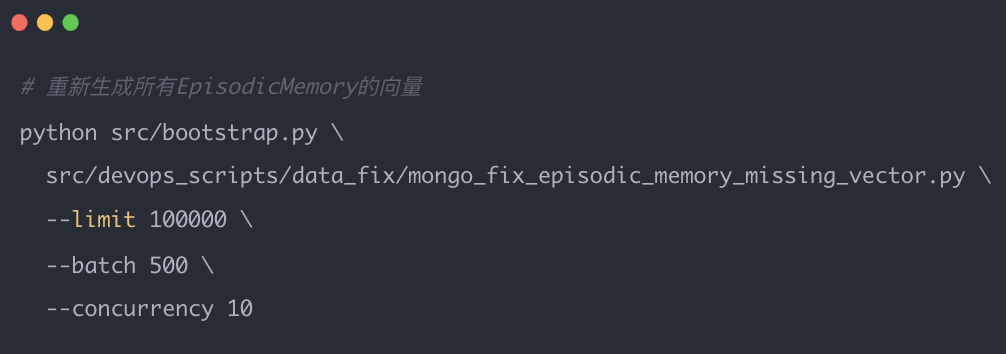
迁移脚本核心逻辑: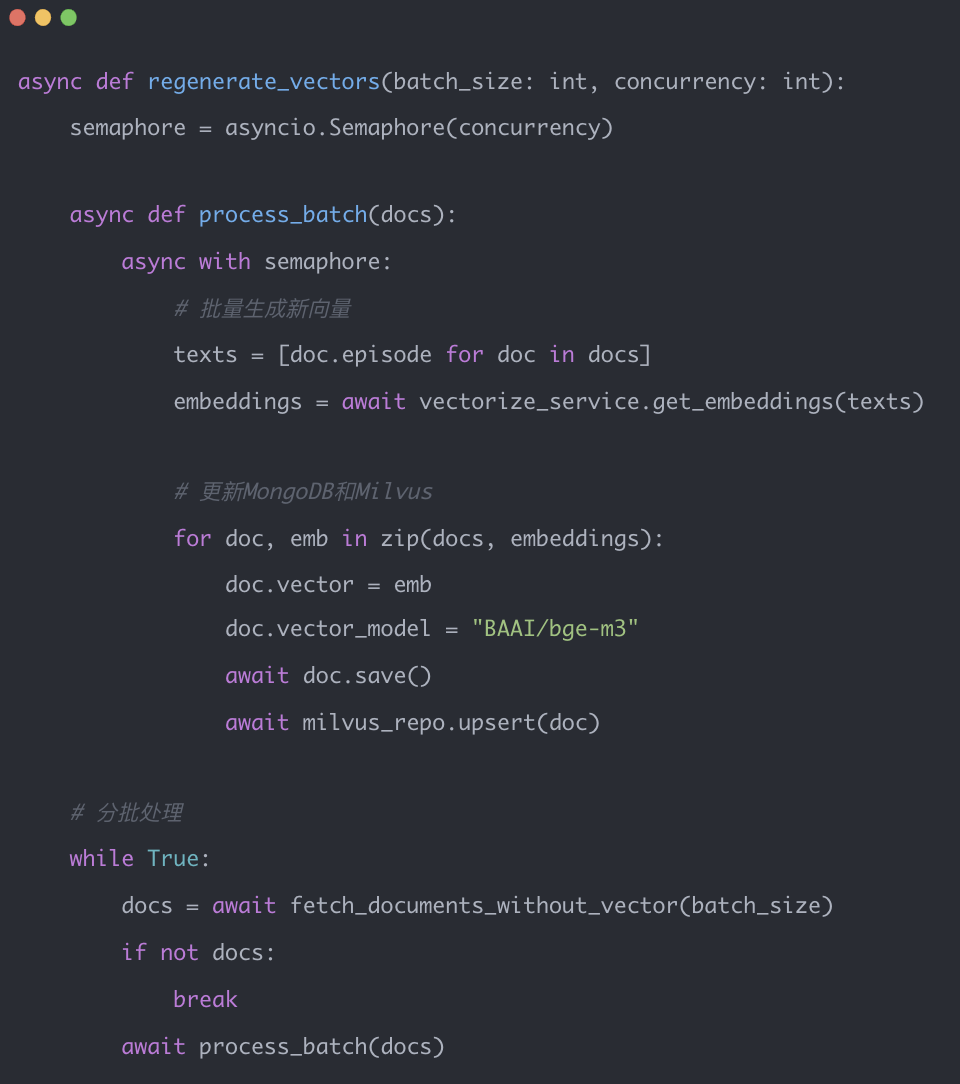
4.3 多租户改造建议
当前系统缺少tenant_id字段,企业部署需要以下改造:
1. 数据模型添加租户字段: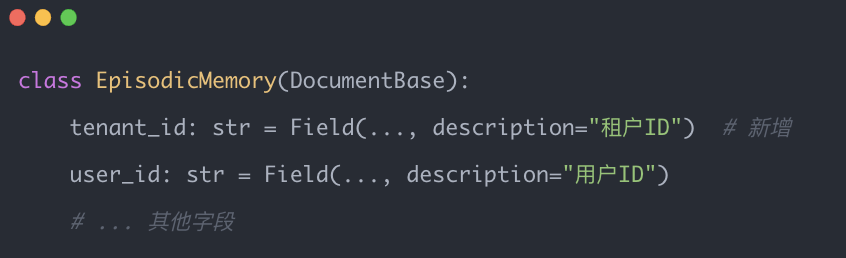
2. MongoDB索引调整: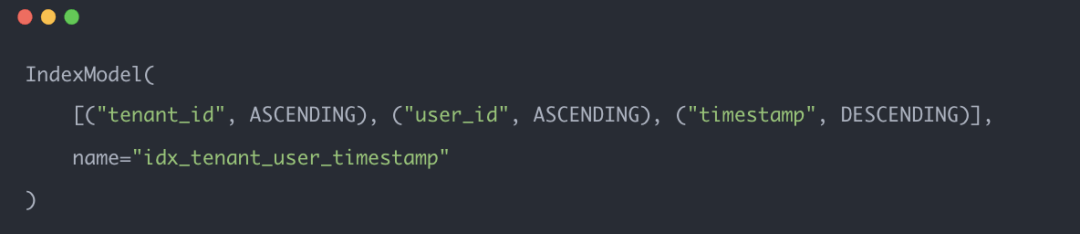
3. API认证中间件: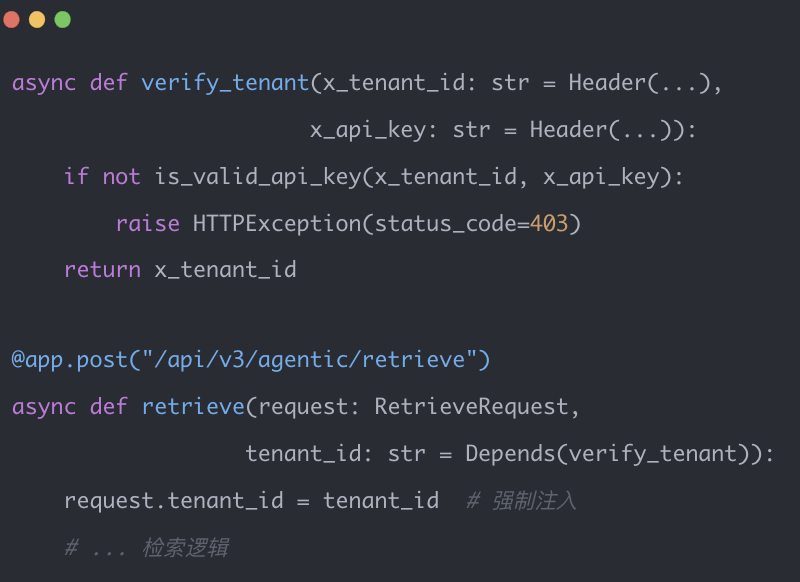
五、总结与展望
EverMemOS通过层次化记忆架构、LLM驱动的边界检测和混合检索策略,重新定义了AI长期记忆系统的设计范式。它不仅在多个SOTA基准测试中证明了技术实力,更提供了开箱即用的企业级解决方案。
核心优势:
-
✅ 语义完整性:告别机械切分,拥抱智能记忆单元 -
✅ 层次化构建:从原子MemCell到高阶记忆的自然演化 -
✅ 混合检索:RRF融合结合精确匹配与语义理解 -
✅ 灵活部署:支持本地模型替换,降低成本 -
✅ SOTA性能:在NQ320K、LoCoMo、2wiki等多个基准领先
未来方向:
-
🔮 原生多租户支持与权限管理 -
🔮 动态查询策略(根据查询类型自适应选择检索方式) -
🔮 更丰富的记忆类型(任务记忆、关系网络等) -
🔮 自动化评估框架与业务数据集成
EverMemOS正在改变AI Agent与记忆交互的方式——从"检索数据库"到"对话记忆系统",让AI真正拥有记忆力而非存储器。
