

1. 小红书数据框架的演进
2. 通用增量计算概述
01
小红书数据框架的演进
在小红书 APP 中,用户可以浏览社区笔记、与朋友进行互动、可以观看直播,也可以在商城购买商品,而这些都是强数据驱动的业务。小红书用户的体量以及其业务复杂度超高,因此对其数据平台对应的数据能力有着比较大的挑战。
1. 小红书业务及数据概览
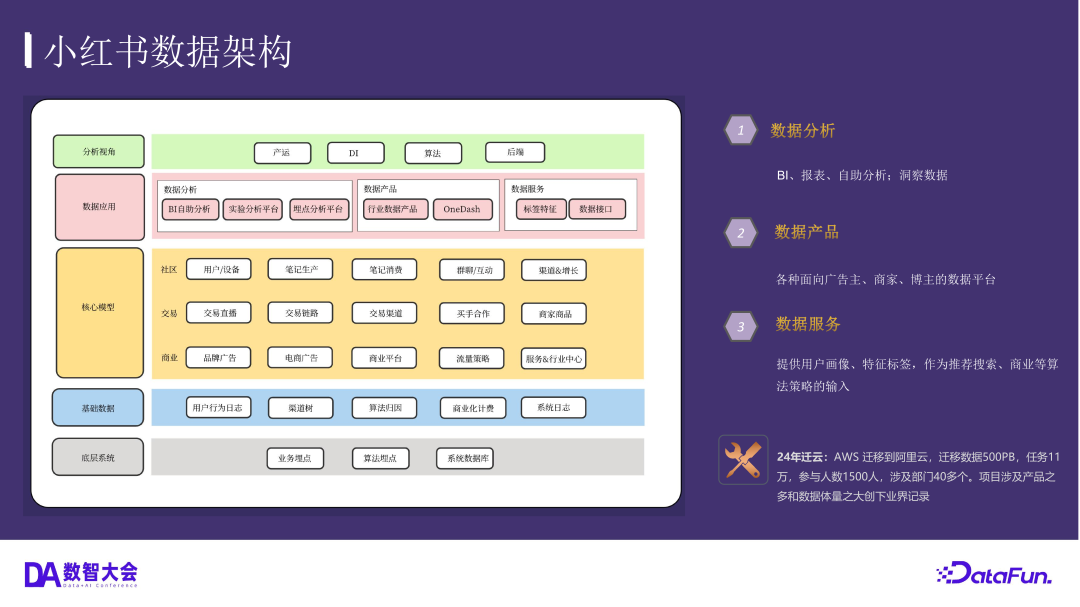
目前,小红书的整体数据平台是采用业界通用的数仓标准和建模方式来进行维护管理的,包括但不限于自建的调度平台、运维平台、资产管理平台、治理平台、报表平台等一系列产品型工具能力,共同辅助数据资产在企业中发挥更大的价值。
其中,价值输出主要分为四类:
第一类是数据分析。例如支持面向高管的报表、支持一线运营及销售的自助分析产品;
第二类是数据产品。例如小红书面向广告主、商家、博主、内部需求方的数据平台;
第三类是数据服务。例如提供给推荐、搜索、算法团队的用户画像以及特征标签等;
第四类是 AI 相关。例如使用 AI 来帮助用户更轻量地获取数据洞察、生成数据报告和给出经营建议等;
2024 年,小红书的基础设施层从 AWS 迁移至阿里云,迁移数据 500PB,任务 11 万,参与人数 1500 人,涉及部门 40 多个,整体的迁移和改造的复杂度创下了业界记录。截至目前,小红书已有部分业务在自建云上试跑,未来将向混合云架构发展。
