
升级步骤
重要提示
升级后,您必须运行以下迁移来转换现有数据源凭据。此步骤是确保与新版本兼容性所必需的:uv run flask transform-datasource-credentials
一、Docker Compose部署
-
1. 备份自定义的docker-compose YAML文件(可选)
cd docker
cp docker-compose.yaml docker-compose.yaml.$(date +%s).bak-
2. 从main分支获取最新代码
git checkout 1.9.1
git pull origin 1.9.1-
3. 停止服务(请在docker目录中执行)
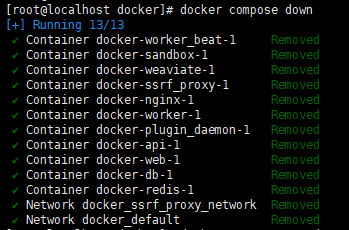
docker compose down
-
如图: 
-
4. 备份数据
tar -cvf volumes-$(date +%s).tgz volumes
-
5. 升级服务
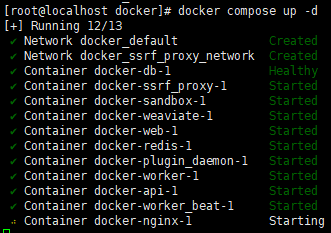
docker compose up -d
-
如图: -
6. 容器启动后迁移数据
docker exec -it docker-api-1 uv run flask transform-datasource-credentials

二、源代码部署
-
1. 停止API服务器、Worker和Web前端服务器。 -
2. 从发布分支获取最新代码:
git checkout 1.9.1
-
3. 更新Python依赖:
cd api
uv sync-
4. 运行迁移脚本:
uv run flask db upgrade
uv run flask transform-datasource-credentials
-
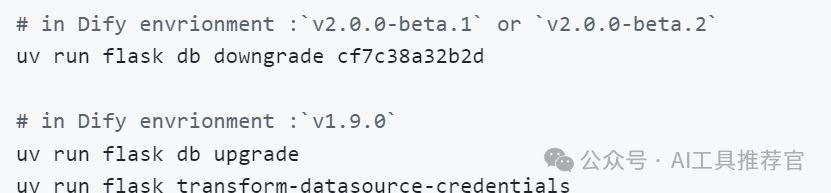
重要提示
如果您当前使用的是 v2.0.0 – beta.1 或 v2.0.0 – beta.2 版本,您必须运行以下迁移脚本来升级。
[警告] 这是一个破坏性操作,将导致数据丢失。
此迁移脚本将永久删除以下数据:
所有现有知识管道所有相关数据集凭据请在继续之前确保您已备份所有必要信息。
-
5. 重新运行API服务器、Worker和Web前端服务器。
升级问题
一、知识库检索使用【迭代器】输出给LLM 报错:Run failed: Invalid context structure: xxx
1.1、现象
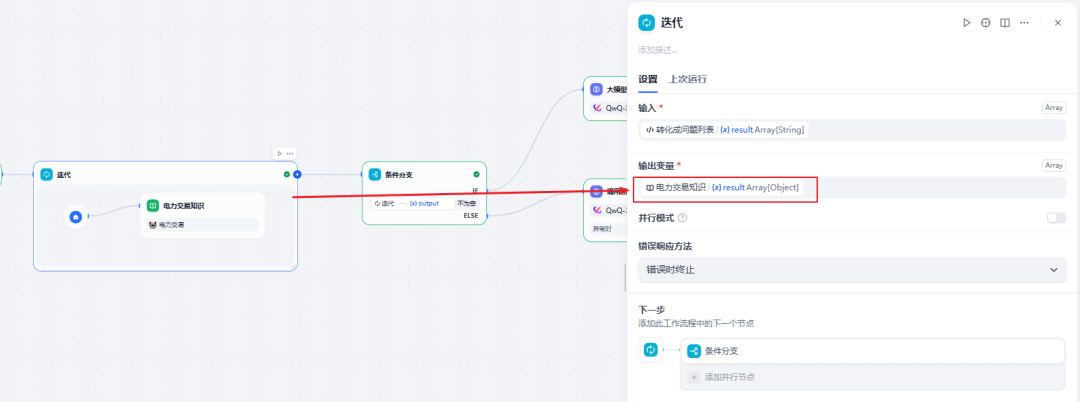

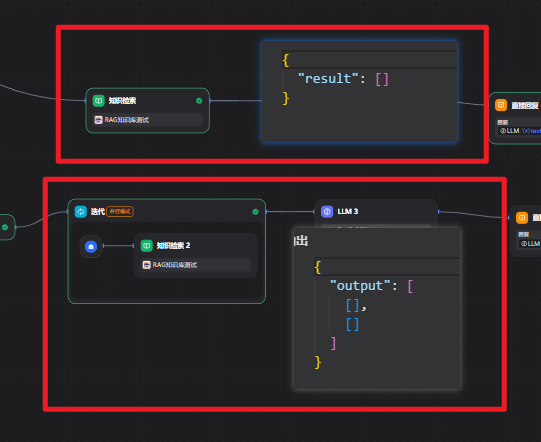
要解决这个问题,请确保你的代码执行节点输出一个像这样的数组:
请确保你的代码执行节点输出一个像这样的数组:
[ {"content":"First message"}, {"content":"Second message"}]
如果你的对象还有其他字段,你需要对它们进行转换或序列化,让每个对象都包含一个content 键,里面放着你希望 LLM 处理的文本。直接传递没有这种结构的原始对象数组肯定会触发错误。你可以在 Dify 的LLM 节点实现中看到这个验证和错误处理逻辑。
从GitHub 的关于Dify Issue 中发现:
迭代节点中断性变更 ·问题 #26630 ·朗天才/DIFY
代节点输出中的这种变化(从对象的平面数组到对象数组的数组)是在 Dify 1.9.1 中引入的,这是由于工作流引擎中的重构和新的并行模式支持。节点现在将每个并行作业的输出收集到有序列表中,因此如果每个作业返回一个数组/对象,则结果是嵌套数组。没有代码在并行执行后合并或展平这些数组;这现在是并行模式源中的默认行为。
没有关于此重大更改的官方文档或迁移说明警告。如果您的工作流需要平面数组,则可以手动平展下游代码节点中的输出作为解决方法。例如,在 Python 中:
# If output is an array of arrays of objects
flat= [item for sublist in output for item in sublist]
相关问题和 PR 以获取更多背景信息:
-
问题 #26225 -
公关 #25833 -
公关 #26036 -
公关 #26368
如果需要以前的行为,则需要更新工作流以展平输出,直到发布官方修补程序或选项。请密切关注未来的版本以获取任何更新。
1.3、处理方法
在【迭代器】与【LLM节点】之间增加 【代码执行处理】,把迭代器输出的数组嵌套数组的结果,扁平化处理,处理好后统一合并给LLM节点
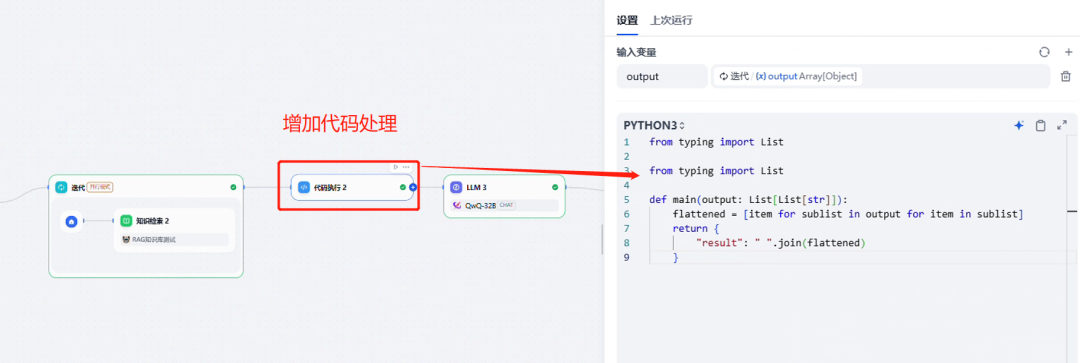
from typing import Listfrom typing import Listdef main(output: List[List[str]]): flattened = [item for sublist in output for item in sublist] return { "result": " ".join(flattened) }
