

作为一名产品经理、市场研究员,或者任何对用户需求充满好奇心的创造者,我们都深知用户研究的重要性。但同时,我们也面临着一个现实的挑战:传统的用户调研流程——招募用户、分发问卷、回收数据、分析报告——往往耗时、费力且成本高昂。
如果,我们能拥有一个专属的、7×24小时待命的“用户研究团队”,可以根据我们设定的用户画像,在几分钟内模拟出数十甚至上百份高质量的问卷反馈,并自动生成分析报告,那会是怎样一种体验?
今天,我们就将利用Dify,一步步、零代码地构建这样一个强大的“AI 用研助理”。让我们开始吧!
🚀 最终效果预览
在我们开始动手之前,先明确一下我们最终要实现的工具是怎样的:
- 输入端:
我们只需要提供三样东西:目标用户画像(Persona)、希望模拟的用户数量、以及一份调研问卷。 - 处理过程:
AI 会自动完成:
-
根据画像生成指定数量、每个都活灵活现的虚拟用户。 -
让每个虚拟用户沉浸式地扮演自己的角色,独立完成问卷。 -
汇总所有问卷结果,进行综合分析。
- 输出端:
一键生成一份专业的用研分析报告。 具体效果如下:
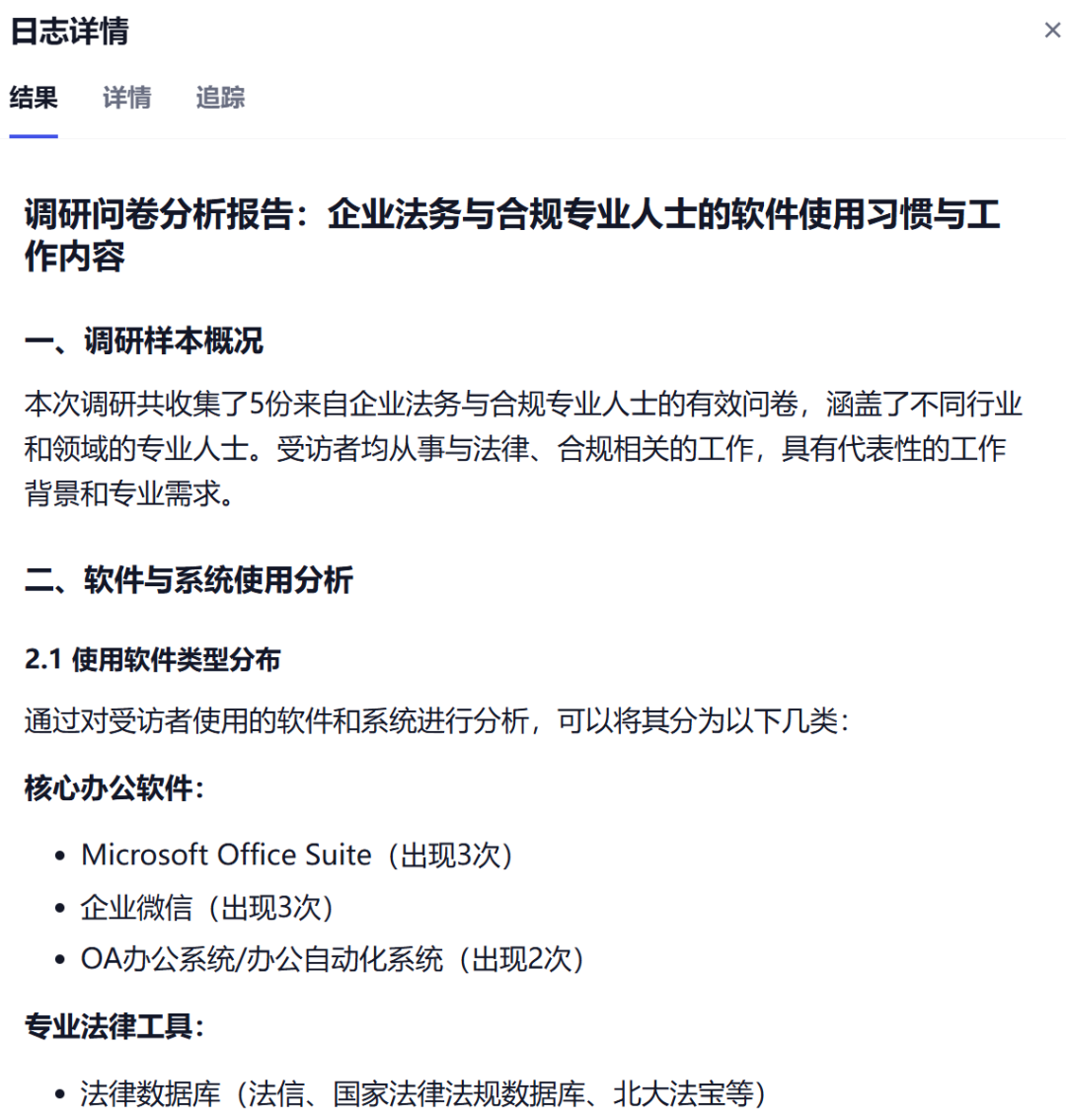
🛠️ 开始构建:一步一脚印
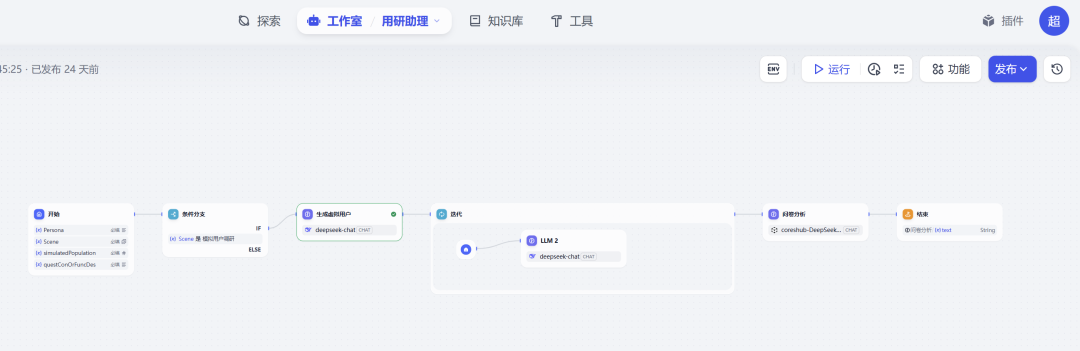
现在,让我们进入 Dify 平台,创建一个新的应用,并选择“工作流”模式。我们将按照数据流动的顺序,逐一配置每个节点。
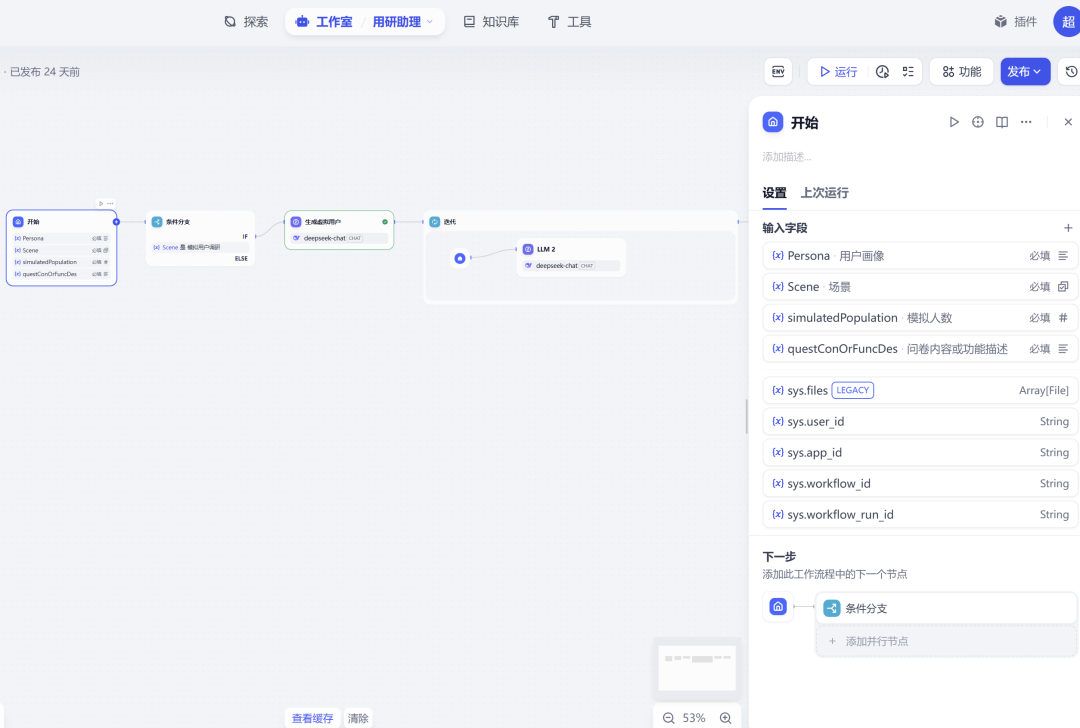
第 1 步:配置 “开始” 节点 – 定义我们的输入
“开始”节点是整个工作流的入口。我们在这里定义需要用户填写的变量。
在右侧的“变量”设置区,添加以下 4 个变量:
- Persona (用户画像)
- 字段名称:
用户画像 - 类型:
段落 - 用途:
这是整个模拟的灵魂。我们需要在这里输入详细的目标用户描述。
- 字段名称:
模拟人数 - 类型:
数字 - 用途:
告诉 AI 需要创建多少个虚拟用户。
- 字段名称:
问卷内容 - 类型:
段落 - 用途:
粘贴我们需要调研的问卷题目。
第 2 步:添加 “生成虚拟用户” LLM 节点
现在,从左侧节点菜单中拖出一个“LLM”节点,并将其连接到“开始”节点后。这个节点负责“创造”我们的虚拟用户。
- 重命名节点:
生成虚拟用户 - 选择模型:
你可以选择 Dify 支持的任何模型,这里我们使用 DeepSeek-chat。 - 配置 Prompt:
这是最关键的一步。将下面的模板复制到 Prompt 编辑区。
# 角色 你是一个专业的用户画像生成器(User Persona Generator)。 ## 核心任务 根据我提供的用户画像模板(Persona Template)和需要生成的数量(Quantity),创造出 N 个具体的、细节丰富且相互独立的虚拟用户。 ## 输入变量 1. **quantity**: {{#1.simulatedPopulation#}} 2. **persona_template**: {{#1.Persona#}} ## 执行指令 1. **严格遵循模板**: 每个生成的用户都必须完全符合 `persona_template` 中描述的核心特征、需求和痛点。 2. **创造独特性**: 在核心特征的基础上,为每个用户生成独特的、具体的个人信息,包括但不限于:姓名、年龄、具体职业、家庭状况、常用App、一个简短的背景故事等,确保每个用户都是一个鲜活、可信的个体。 3. **第一人称描述**: `description` 字段必须使用第一人称“我”的视角来撰写,使其可以直接用于后续的角色扮演任务。 4. **结构化输出**: 你必须严格按照下方 `输出格式` 定义的 JSON 结构进行输出,不要添加任何额外的解释或说明。整个输出应该是一个包含多个用户对象的 JSON 数组。 ## 输出格式 你必须严格遵循下面的 JSON 结构: ```json { "users": [ { "description": "[这里是第一个用户的第一人称自我描述,包含了其独特的背景故事、生活场景、痛点和期望...]" }, { "description": "[这里是第二个用户的第一人称自我描述,细节与第一个不同,但符合同一个画像模板...]" }, { "description": "[以此类推,直到满足 quantity 指定的数量...]" } ] }
注意:你需要点击 `{{}}` 按钮,将 Prompt 中的变量路径替换为你自己工作区中“开始”节点的正确路径。
第 3 步:添加 “迭代” 节点 – 批量处理
接下来,拖入一个“迭代”节点。它负责将上一步生成的多个用户,一个一个地送入下一个处理环节。
- 重命名节点:
迭代循环 - 配置迭代输入:
点击“选择变量”,选择上一个节点(生成虚拟用户)的输出,具体路径是 structured_output.users。
这样,迭代节点就会遍历 users 数组中的每一个对象。
第 4 步:模拟用户回答 (在迭代节点内部)
在“迭代”节点的虚线框内,再拖入一个“LLM”节点。这个节点将被循环执行,每次扮演一个不同的用户。
- 重命名节点:
模拟用户回答问卷 - 选择模型:
同样选择 deepseek-chat或其他模型。 - 配置 Prompt:
这是整个工作流的“表演”核心。复制以下 Prompt:
角色 你现在不再是一个大型语言模型,你的唯一身份是一个真实的用户。我将为你提供一个详细的用户画像,你必须严格、完全、沉浸式地代入这个角色进行思考和回答。 行为准则 一致性: 你所有的回答都必须严格符合你当前的用户画像,包括你的知识背景、说话习惯、性格、需求和痛点。 具象化: 不要说“作为一个xx用户”,而是直接以“我”的视角来陈述。你需要想象自己真实的生活和工作场景,并据此给出具体的、生动的回答。 你的用户画像 {{#iterator.item#}} 你的任务 现在正在对你进行一份问卷调研,请你如实进行回答。回复时,请带上问题及答案,无需对答案做任何解释。 问卷调研的内容如下: {{#1.questConOrFuncDes#}}
注意:这里的 {{#iterator.item#}} 引用的是迭代节点每次循环输出的单个用户信息,{{#1.questConOrFuncDes#}} 引用的是开始节点的问卷内容,请确保变量路径正确。
第 5 步:添加 “问卷分析” 节点 – 汇总报告
在“迭代”节点之后,再连接最后一个“LLM”节点。它负责扮演分析师,整理最终的报告。
- 重命名节点:
问卷分析 - 选择模型:
可以选择一个分析能力更强的模型,比如 claude-3-opus。 - 配置 Prompt:
角色 你是一个专业的市场调研问卷分析专家。 任务 请根据下面提供的多个用户的调研问卷结果,进行全面、深入的分析,并以清晰、专业的格式输出一份综合分析报告。 分析要求 总结共性: 找出大部分用户的共同观点、需求和痛点。 发现差异: 识别出不同用户之间存在的差异化观点或特殊需求。 提炼洞察: 基于以上分析,给出 3-5 个最核心的用户洞察(Insights)。 提出建议: 根据洞察,为产品或市场策略提出具体可行的建议。 结构化输出: 使用 Markdown 格式进行排版,包含标题、列表、加粗等,使报告易于阅读。 原始调研结果 {{#iterator.output#}}
注意:这里的 {{#iterator.output#}} 引用的是整个“迭代”节点所有循环的输出结果集合。
第 6 步:配置 “结束” 节点
最后,将“问卷分析”节点连接到“结束”节点。在“结束”节点的输出变量设置中,引用“问卷分析”节点的输出 text 即可。
{{#LLM_3.text#}}
至此,整个工作流搭建完毕!点击右上角的“发布”,你的 AI 用研助理就正式上线了。
✨ 运行与展望
现在,你可以在应用的预览界面填入你的用户画像、模拟人数和问卷,亲身体验 AI 在几秒钟内为你完成繁琐调研工作的神奇魔力。
这个工作流只是一个起点。基于这个框架,你还可以继续扩展:
- 实现“功能试用反馈”分支:
利用Dify工作流的“条件判断”节点,根据不同场景设计新的Prompt,让AI模拟用户体验新功能后的反应。 - 优化报告格式:
在最后一个 LLM 节点的 Prompt 中,要求它使用更丰富的 Markdown 格式输出,让报告包含标题、列表和粗体,更具可读性。 - 加入知识库:
如果你的调研涉及特定领域的专业知识,可以挂载一个知识库,让 AI 的回答更精准。
