JSON 格式作为轻量级数据交换格式,已成为 API 接口、数据存储、系统集成中的 “通用语言”。然而,传统大语言模型(LLM)在生成 JSON 时,常面临格式错乱、字段缺失、语法错误等问题 —— 可能因自然语言表述偏差导致括号不匹配,也可能因复杂逻辑处理遗漏关键参数,最终让自动化数据流转 “卡壳”,不仅增加人工校验成本,更可能引发下游系统故障,成为业务效率提升的隐性瓶颈。
LLM 稳定 JSON 输出功能的出现,正是为解决这一核心痛点而生。
原理:这个包能智能地处理各种常见错误,例如:修正缺失或错误的引号、移除多余的逗号,并能自动忽略JSON内容前后无关的文本
https://github.com/mangiucugna/json_repair/
"好的,这是您要的JSON:n{'user': 'Alex', 'id': 123}n希望对您有帮助!"为例
这种一般是因为前后有多余的字,无法直接使用json.load进行转换,因为需要使用json-repair。
from json_repair import repair_jsonllm_output_string = "好的,这是您要的JSON:n{'user': 'Alex', 'id': 123}n希望对您有帮助!"repaired_string = repair_json(llm_output_string)# 输出: {"user": "Alex", "id": 123}
原理:定义了一个类作为数据“蓝图”,规定了数据有哪些字典。其次,当传入llm返回结果时(一般是字符串),Pydantic会自动验证数据结构,并将相应数据转换为对应的type。
缺点:Pydantic 本身无法像json-repair处理额外的文字。
from pydantic import BaseModelclass User(BaseModel): id: int name: str is_active: bool = True input_data = {"id": "123", "name": "Alice"} user = User(**input_data) print(user.model_dump_json(indent=2)) # 输出: { "id": 123, "name": "Alice","is_active": true}
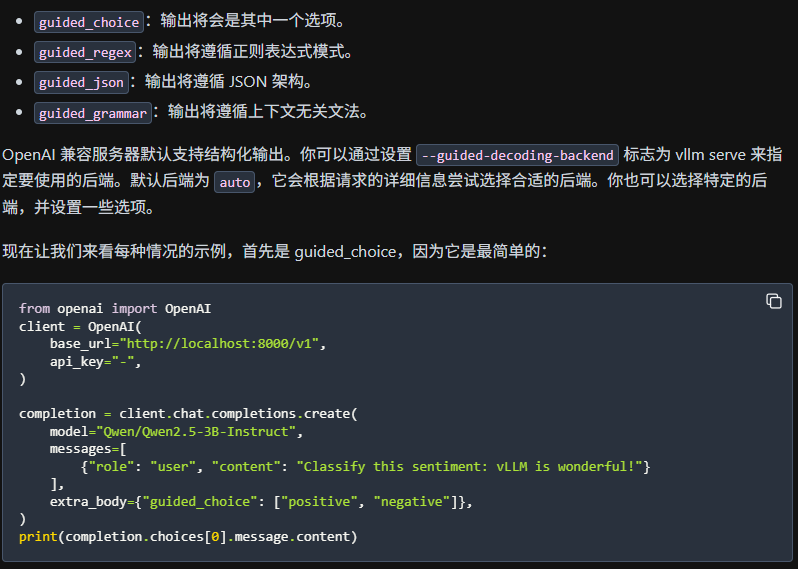
原理:和schema的原理是一样,只是vllm里面集成好,可以直接设置参数extra_body来输出。
from pydantic import BaseModelclass Topic(BaseModel): 问题: str 答案: strcompletion = client.chat.completions.create( model=model, messages=[ {"role": "system", "content": system_prompt }, {"role": "user", "content": user_prompt }, ], extra_body={ "guided_json": Topic.model_json_schema()}, )
这类方法有很多,比如:LM-Format-Enforcer库,Xgrammar等
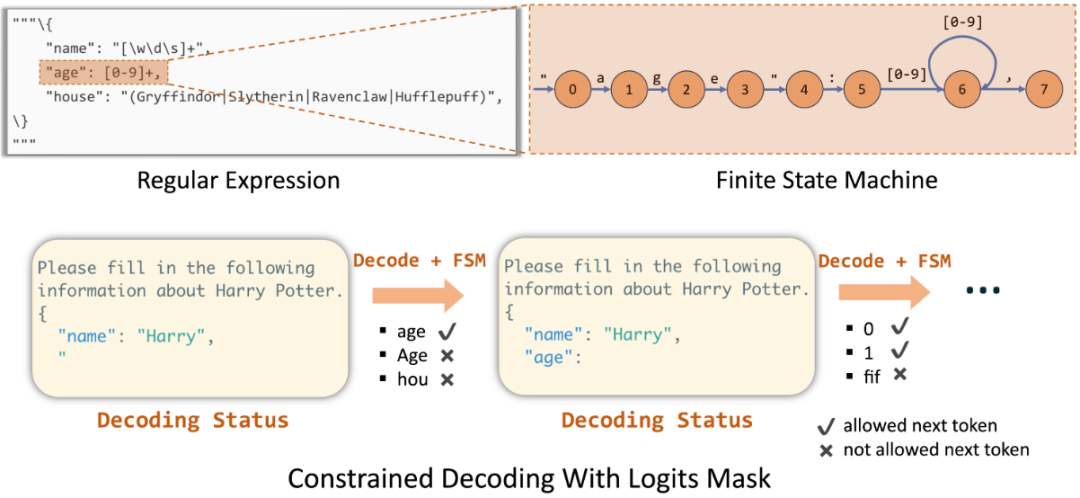
原理:在LLM生成每个token时基于策略选择满足约束的token,从而指导LLM生成给定的json格式。简单地说,通过一个预设的规则(如JSON Schema),在模型选择下一个词(Token)的瞬间,动态地屏蔽掉所有不符合语法或格式的选项。
缺点:实现复杂,增加开销,可能会稍微降低生成速度,一定程度上牺牲模型的灵活性和创造性。