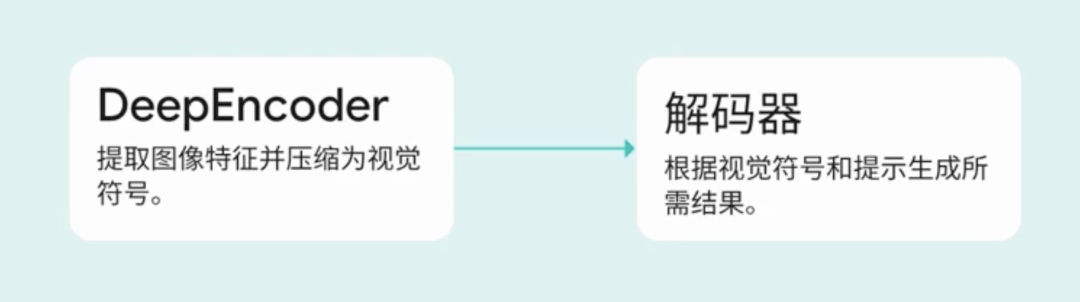
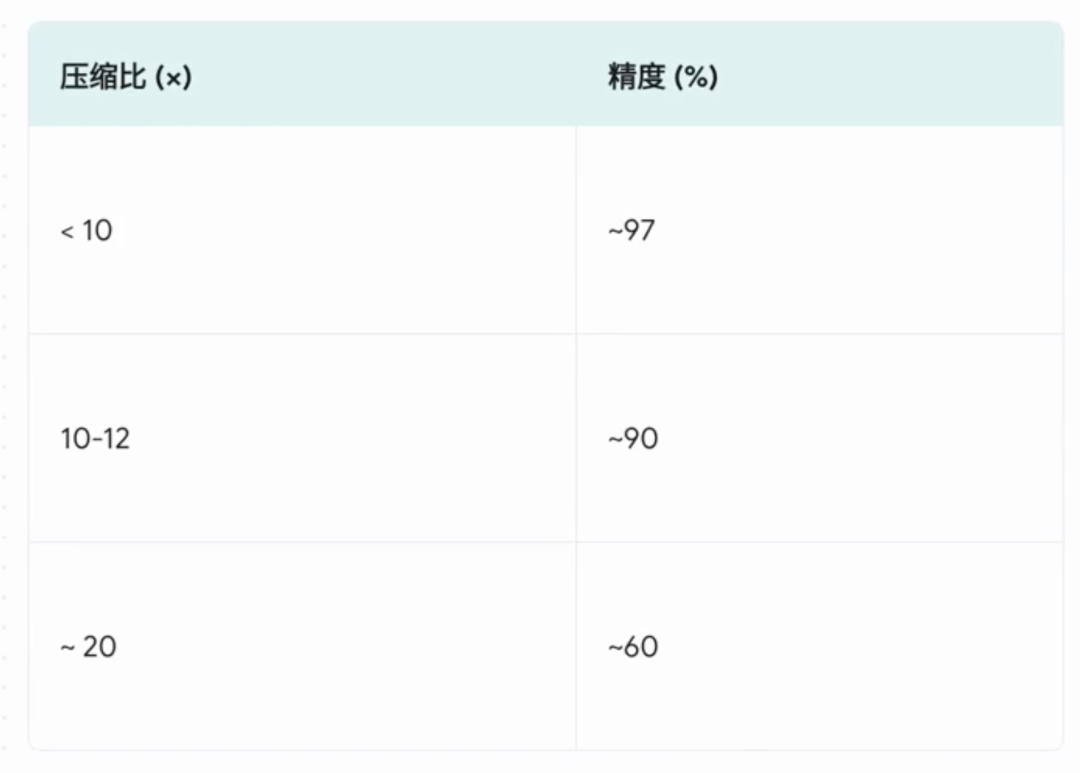
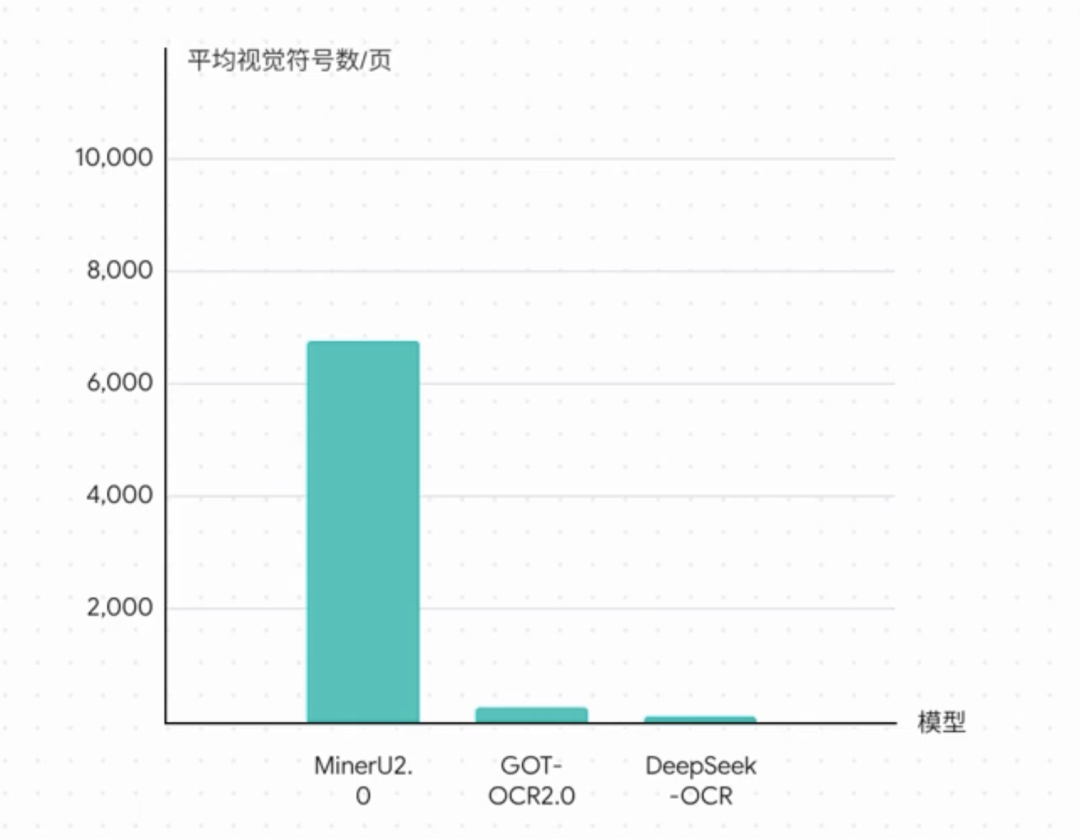
一眼读完一本书?别笑,真有人在干这事 前沿技术 大模型技术 新闻资讯 2月24日 编辑 charles 取消关注 关注 私信 这两天 AI 圈子又炸锅了! 一个叫 DeepSeek-OCR 的新玩意儿,被好多人喊做“ AI 的 JPEG 时刻”。听着就挺酷炫,但到底啥意思?跟咱有啥关系? 今天就来用大白话聊聊。 你有没有想过——AI 有可能学不会的一项技能,居然是:扫一眼就能读完一本书。 听着是不是有点像科幻小说那味? 但今天咱聊的,不是玄幻,而是真实存在的新技术——光学压缩(Optical Compression)。 它的目标就是让 AI “一眼看完”,真的像人一样看图识世界。 AI 最大的老毛病:太能“卷”了 AI 界一直有个头疼的大难题:超长文本太难处理。 比如 GPT-4,强是强,但你要是给它扔一本几百页的小说,它就要开始“烧脑”了。 而且这可不是“多一倍字,多一倍计算”这么简单——是平方级增长。 简单说,字越多,AI 就越累,钱包也越疼。 这点我特别懂,毕竟我读完一本大部头的书,前面都忘光了。 AI 也差不多,它读着读着就把前面的关键细节给丢了。 突破点:别读字了,看图! 解决办法居然特别“人性化”——别再一个字一个字读了,直接拍照! 是的,这就是光学压缩的灵感:把整页、甚至整本书拍成一张图,让 AI 直接去“看图识文”。 ▲ 传统的文本处理和光学压缩的文本处理 这张图片就不只是图片,而是一个信息密度爆炸的压缩包。 咱们平时不都说“一图胜千言”嘛?一张图片能顶好多文字。AI也是这个理儿。 一张扫描的文档图片,它包含的信息量,比你把这些文字一个字一个字打进去,要“轻”得多,也更“紧凑”。 AI 只需处理少得多的视觉符号,就能理解整本书的内容。 效率提升那叫一个离谱,真·降维打击。 真·技术派登场:DeepSeek OCR 光有想法不够,得有人真做出来。 于是 DeepSeek 团队推出了个新模型——DeepSeek OCR。 它的任务就一个:验证光学压缩到底靠不靠谱。 它的原理也简单: 第一步:用 Deep Encoder 压缩,把一整页文字变成一张浓缩图; 第二步:再用解码器“解压”,把文字原封不动还原回来。 ▲ DeepSeek-OCR 包好压缩和解压两部分 整个模型的三个死目标: 1️⃣ 要能看超高清文字图; 2️⃣ 要超级省资源; 3️⃣ 用尽可能少的视觉符号表达尽可能多的信息。 每一条都精准命中“算力贵、效率低”的痛点。 效果有多炸?看数据 有个数据我看到都惊了:压缩 10 倍,还能保持 97% 准确率。 这基本就是无损压缩。 更狠的是,压到 20 倍,准确率还有 60%。 这效率,简直是“拿命在压”。 ▲ DeepSeek-OCR 压缩比和精度 同场对比时,其他模型处理同样文档要几千个 token,而 DeepSeek OCR 只要一百来个。 ▲ DeepSeek-OCR 用最少的 token 实现了顶尖的性能 这就叫——花最少的钱,办最大的事。 我突然想到:AI 也该学会“遗忘” 讲真,这技术让我想到一个挺哲学的问题。 我们的大脑,其实也是种“光学压缩”系统。 新记忆清晰得像高清照片,旧记忆慢慢糊成低清图。 你十年前的午饭吃了啥?肯定不记得,也没必要记。 也许 AI 也该这样—— 记住重要的,模糊掉次要的。 不是过目不忘才聪明,学会遗忘,可能才更像人。 所以我想把这个问题留给你: 👉 对 AI 来说,“遗忘”到底是 bug,还是一种高级功能?