

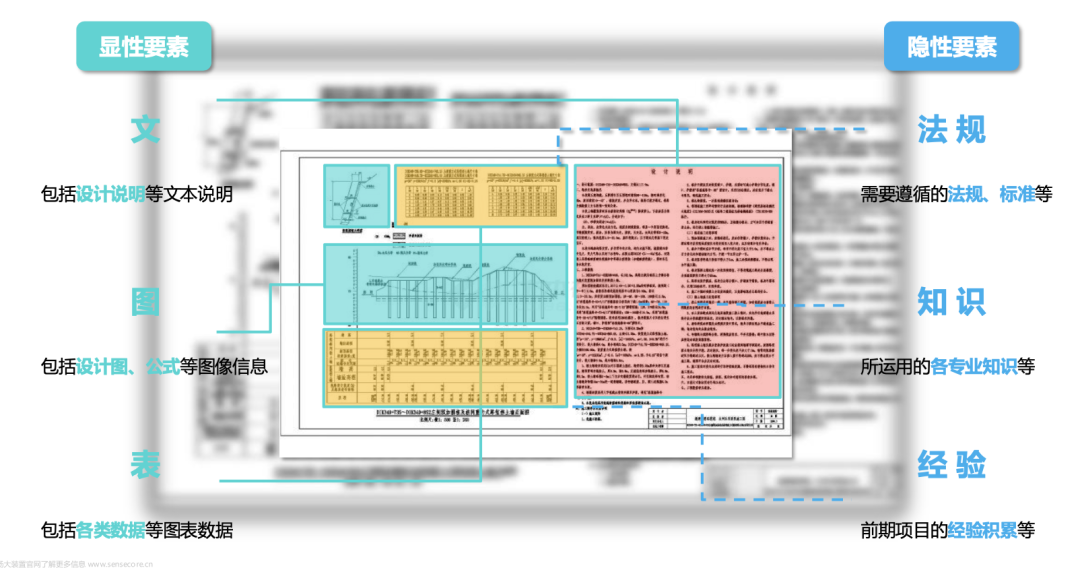
作为我国最早的大型铁路勘察设计单位之一,中铁第一勘察设计院(以下简称“铁一院”)在沙漠铁路、高原冻土铁路、高地温岩土工程处理、长大干线隧道、高寒地区高铁设计等复杂、艰巨的项目中积累了大量宝贵经验。但随着人才迭代,传统 “师徒传承” 模式下的知识流失、效率低下等问题愈发突出,亟待破局。

传统师徒传承模式,给知识的传承、经验的迁移、数据的利用带来三大难题:
-
知识不易传承
-
经验不易迁移
-
数据难以挖掘
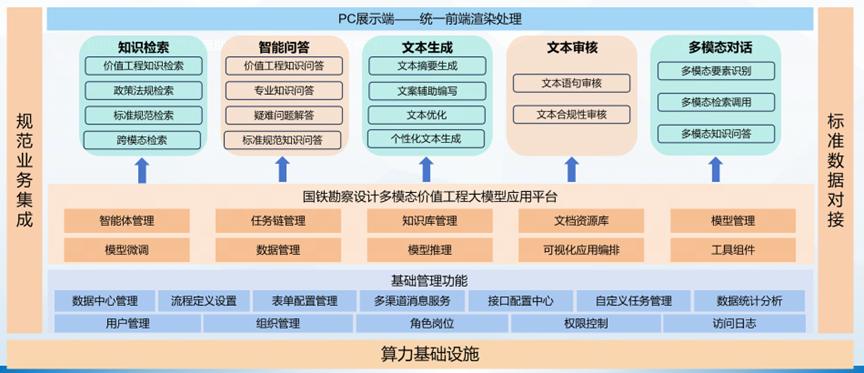
为了找准痛点,对症下药, 商汤大装置与铁一院打造国铁价值工程多模态大模型应用平台,首次将多模态大模型应用于铁路工程设计知识的智能传承与应用。依托商汤大模型应用开发框架LazyLLM,商汤大装置为勘察设计人员打造了国铁勘察设计知识检索、知识问答、文本生成、文档审核以及多模态对话等功能,减轻报告撰写工作量,提高审核效率与质量,助力勘察设计工作“全程提效”。这相当于为每个技术员工引入一个集几十年经验为一身的权威专家!
定制化数据治理管道
铁路工程勘察设计领域覆盖 28 个专业,数据包含法律法规、标准规范、项目成果等,总规模超 420 GB,其中文本类超 130 GB。LazyLLM 团队基于各专业的语料特性,设计专属文档处理 Pipeline,将自定义切片策略(Transform)与节点分组策略(Node Group)以可插拔方式嵌入,兼顾跨专业的一致性与专业内的个性化。
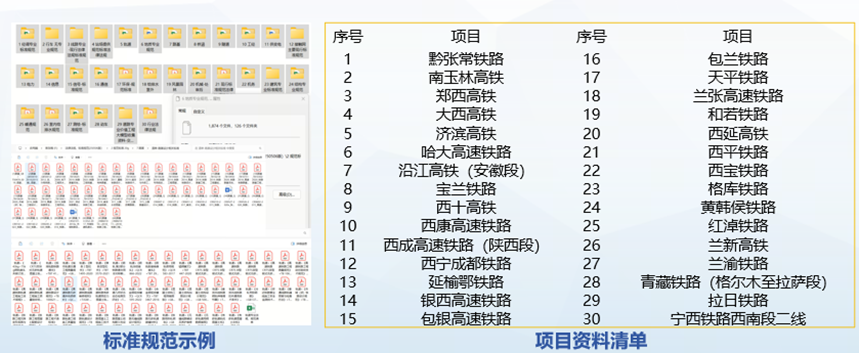
平台构建了覆盖线路、桥梁
隧道、地质、站场、信号、电气化
等28个核心铁路工程专业
的专属高质量数据集
数据总量达420GB
经过严格筛选、清洗和标注
打造知识检索、智能问答等功能
平台还可对新设计文档进行校审
针对语句标点、查漏补缺
前后不一致、标准规范冲突
自定义知识库等方面开展审核
并对识别CAD图纸进行探索实践
目前实现了工程图例的识别
高密度知识场景的稳定与扩展
面对学科多样、知识极度密集的场景,对存储与检索的稳定性、可扩展性要求极高。LazyLLM 内置文档管理服务的 DocProcessor 具备高扩展解析能力,能覆盖海量文件并行处理;同时深度适配商汤自有高性能存储系统,为知识库问答提供稳定、低延迟、可横向扩展的检索底座。
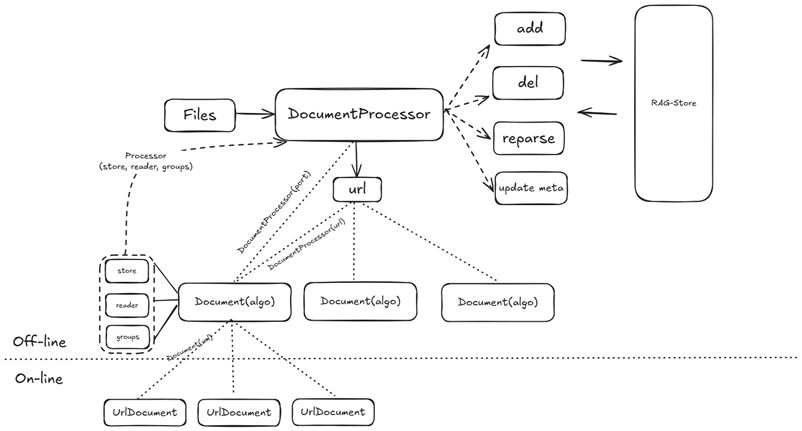
跨模态文档解析与向量表征
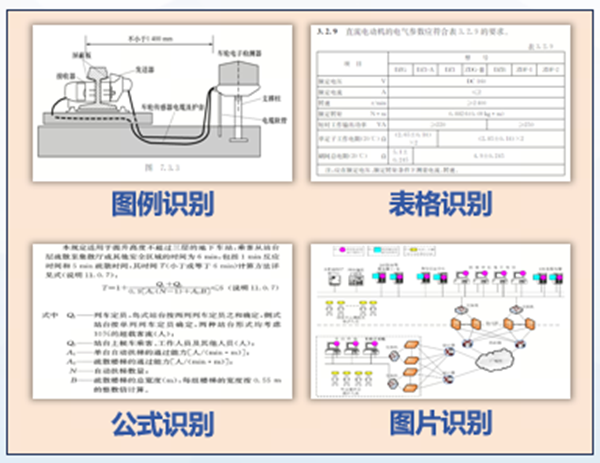
铁路知识同时存在图片、表格、公式与文本等多模态形态。LazyLLM 原生适配高性能解析组件 MinerU,对版面、图片、公式、表格进行结构化抽取;文档管理组件支持多向量模型混用,算法可按模态自适应选择合适的嵌入模型,提升特征表征多样性,显著拓展多模态知识的可检索覆盖面。
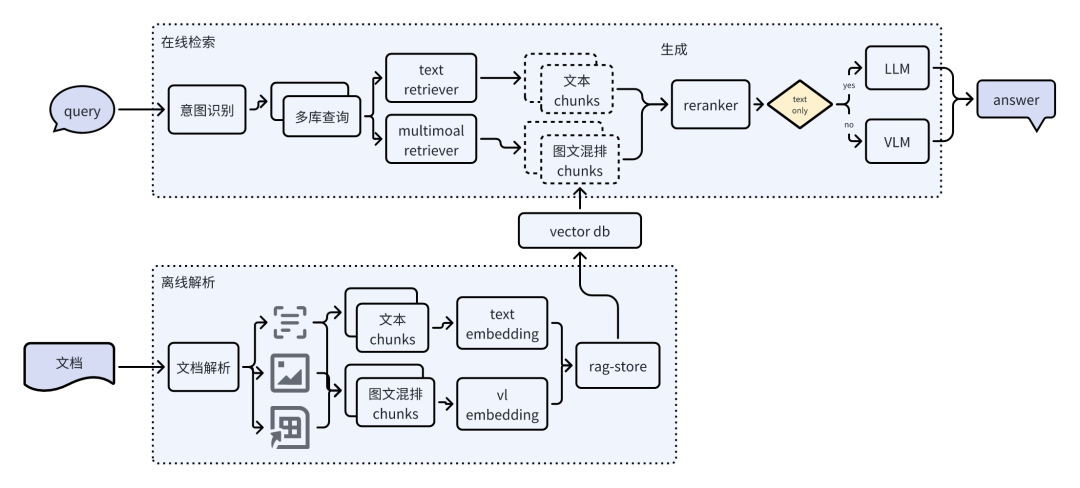
2 多模态知识问答(RAG)能力
面向行业的 RAG 全链路适配
围绕知识治理—检索—生成全链路,LazyLLM 设计并实现行业化的 RAG 算法,兼顾专业严谨性与可解释性,满足铁路工程勘察设计领域的高标准问答需求。
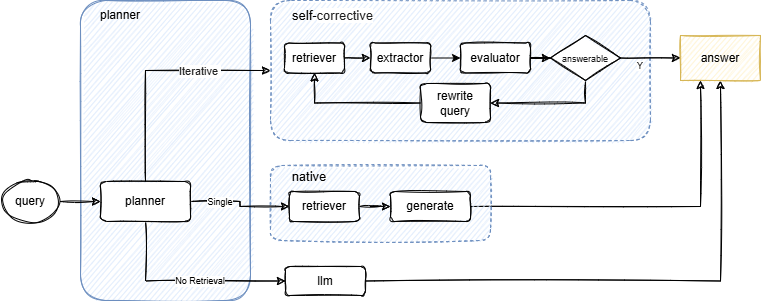
🗝️面向复杂任务的 Multi-Agent RAG
针对多跳推理与跨模态复杂问题,引入多角色协作的 Multi-Agent RAG:通过阶段化检索、证据评估与噪声过滤,结合推理模型优势,显著提升复杂问题的正确率与可追溯性。
🗝️面向演进的模块化迭代机制
依托 LazyLLM 的 Flow 组件,研发流程遵循「Pipeline 搭建 → 模块迭代 → 数据回流」闭环。各环节支持“无痛”替换与灰度升级,便于在不影响主流程的前提下快速验证与上线更优策略。
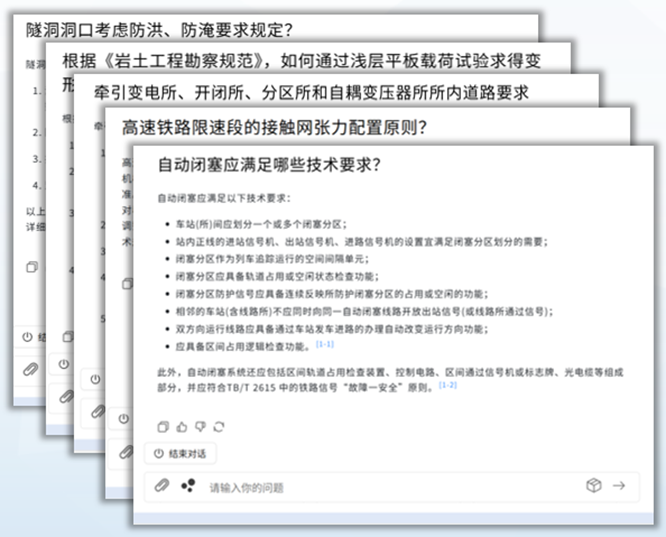
智能写作 + AI 审核:
把专家时间还给高价值工作
日常工作并不只需要问答。围绕铁路专家的真实痛点,团队基于 LazyLLM 编排了两类多智能体应用,面向「长文写作」与「专业审核」两个高耗时场景:
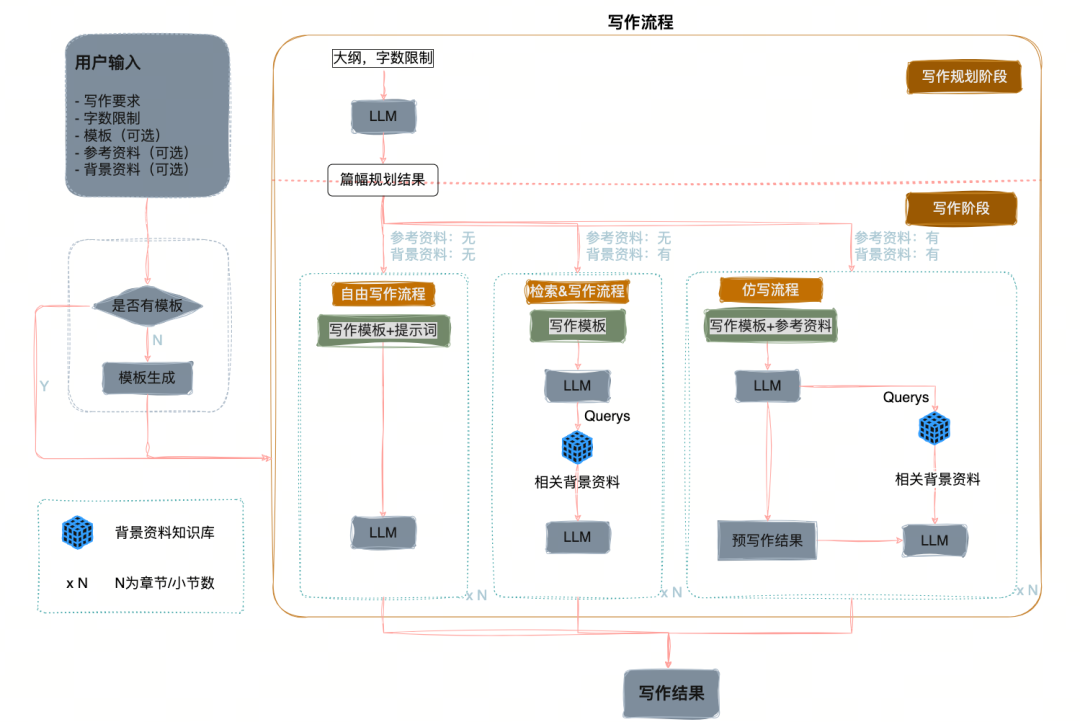
智能写作 Agent(深度检索 + 结构化生成)
通过深度搜索 Agent 与写作 Agent 的协作,采用「多阶段检索 + 两阶段生成」流程:
-
基于工程信息与专业模板生成多维大纲;
-
融合价值工程知识库迭代扩写;
-
生成符合专业要求的长篇高质量报告。
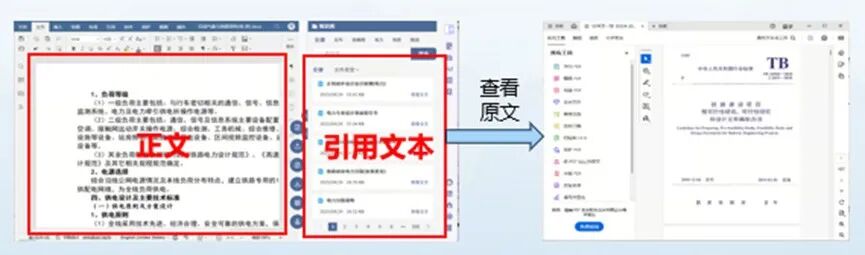
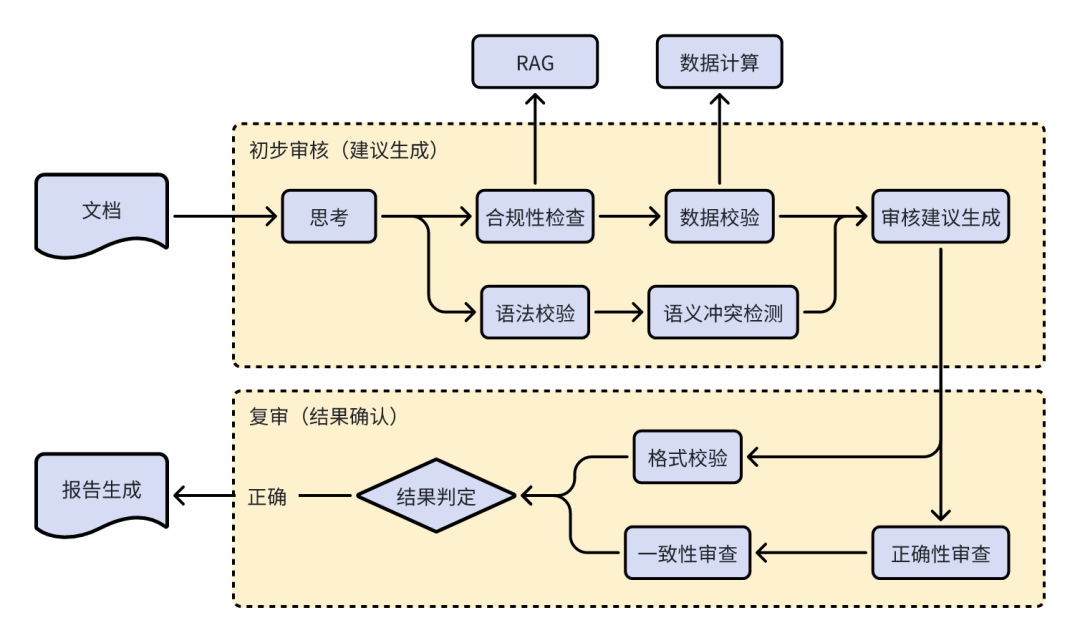
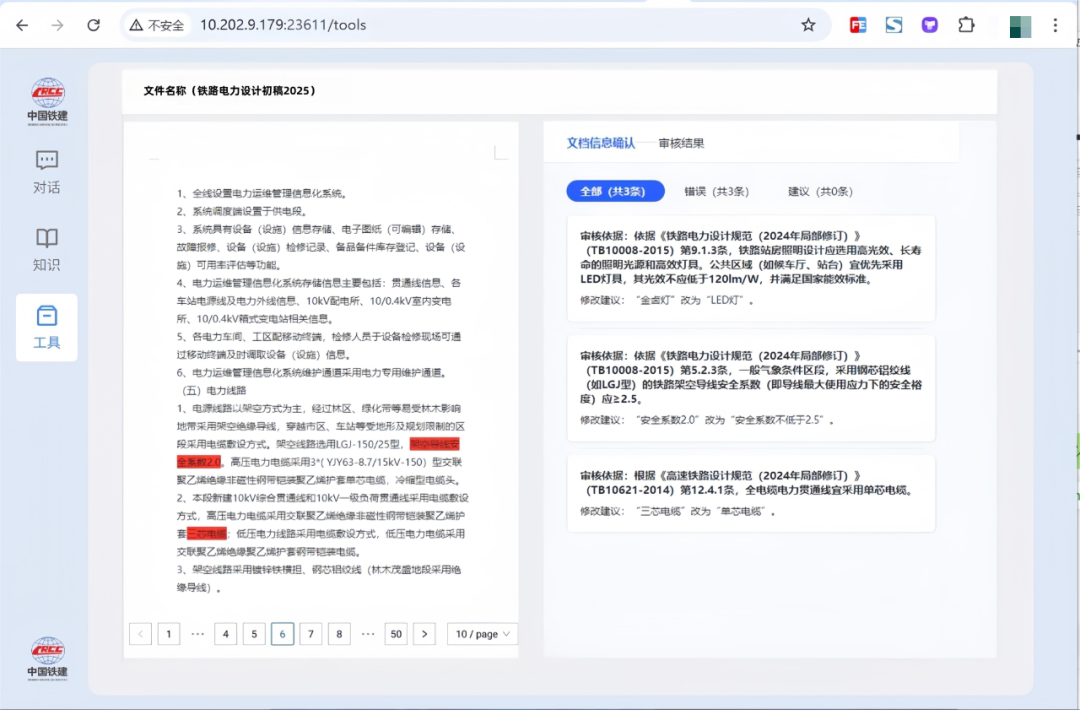
AI 审核 Agent(规则/计算/检索三引擎协同)
面向多专业报告审核,内置规则引擎、计算引擎、检索引擎:除术语与标点等基础校验外,重点支持跨专业一致性校验,并实现审核结论—证据链同步展示,保障结果可解释、可追溯、可落地。
以铁一院项目为起点,LazyLLM 已经在「多学科、多模态、强治理」的高要求环境中验证了可扩展的知识底座与可进化的智能体工作流。它既能把碎片化、异构化的行业知识沉淀为结构化资产,又能以模块化方式持续升级 RAG 与写作/审核能力,将专家从重复性工作中解放出来,把时间投入到更具价值的工程决策与创新实践中。
