

最近一直在探索和研究智能运维平台的可落地方案,说实话难度很大,因为很多细节在当前的技术背景下落地难度还是有点大。我们不妨曲线救国,与其做平台要考虑各种复杂场景,不如先实现和落地某一项功能模块。所以,当前我研究的方向为自动化运维智能体!
一、整体架构设计
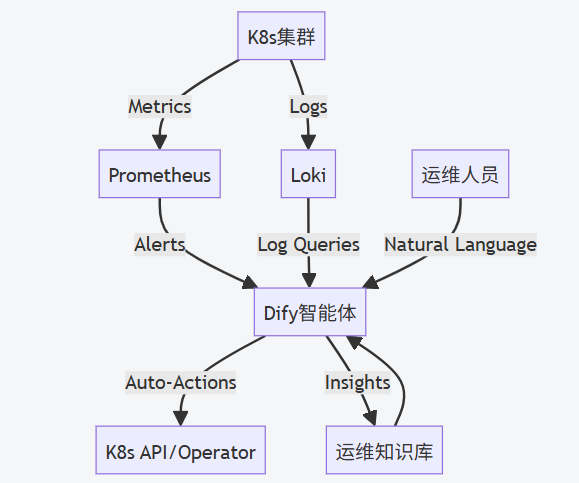
二、核心模块设计
1. 数据采集层
- Prometheus
-
监控指标:节点资源(CPU/MEM/磁盘)、Pod状态、应用性能(QPS/延迟) -
告警规则:配置 kubelet、K8s组件、应用SLO等告警规则 - Loki
-
日志标签: namespace,pod,container,severity -
日志解析:通过 LogQL提取错误日志(如Exception,OOMKilled)
2. dify智能体核心能力
|
|
|
|---|---|
| 智能告警分析 |
|
| 自动修复 |
|
| 预测性维护 |
|
| 自然语言交互 |
|
| 知识库管理 |
|
3. 执行引擎
-
K8s Operator -
开发自定义Operator执行Dify下发的指 -
令安全控制 -
RBAC权限最小化(仅允许特定操作) -
操作前人工确认(高危操作需审批)
三、关键场景实现流程
场景1:Pod异常自动恢复
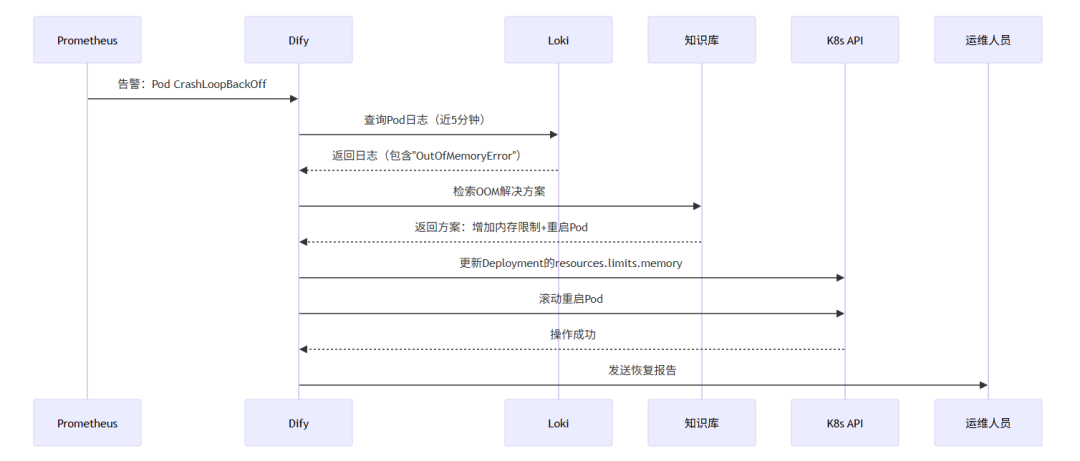
场景2:集群容量预测
-
Prometheus历史数据(7天CPU/MEM使用率) -
K8s事件(如HPA扩容记录)
-
调用预测模型(LSTM)生成未来3天容量趋势 -
输出建议: 建议在明天10:00前增加3个节点
-
自动触发Cluster Autoscaler扩容 -
生成容量报告发送至运维团队
场景3:日志根因分析
-
用户提问:“为什么今天9:00-10:00订单服务延迟飙升?”
-
Dify处理流程: -
查询Prometheus:定位order-service Pod的P99延迟突增 -
查询Loki:提取同时段错误日志(发现数据库连接池耗尽) -
知识库匹配:返回类似案例(解决方案:调整连接池参数) -
生成报告:包含指标趋势图、错误日志片段、修复建议
四、技术实现细节
1. Dify智能体配置
工具集成:
# Dify工具定义示例tools = [ { "name": "query_prometheus", "description": "查询Prometheus指标", "parameters": { "query": {"type": "string", "description": "PromQL表达式"}, "time_range": {"type": "string", "description": "如1h"} } }, { "name": "execute_k8s_action", "description": "执行K8s操作", "parameters": { "action": {"type": "string", "enum": ["restart_pod", "scale_deployment"]}, "target": {"type": "string", "description": "资源名称"} } }]
2. 知识库构建
-
数据来源: -
历史工单系统(Jira/Zendesk) -
运维文档(Confluence) -
K8s事件日志
-
处理流程:

3. 安全与审计
-
操作审计:所有Dify执行的操作记录到Elasticsearch -
熔断机制:连续3次自动修复失败则暂停并人工介入 -
敏感信息过滤:日志脱敏(如密码、Token)
