

背景
在当今AI应用蓬勃发展的时代,内容安全与合规性已成为开发者不可忽视的重要环节。比如用户在客服场景中,可以通过敏感词审查过滤用户的辱骂性语言,并返回预设的礼貌回复。
dify作为一款开源的大语言模型应用开发平台,其内置的敏感词审查机制为开发者提供了强大的内容安全保障。本文将深入解析Dify的敏感词审查模块(moderation)的工作原理,并通过源码分析揭示其实现细节,帮助开发者更好地理解和应用这一功能。
dify 如何开启敏感词审查
要开启敏感词审查,需要在右下侧的功能管理界面进行开启:

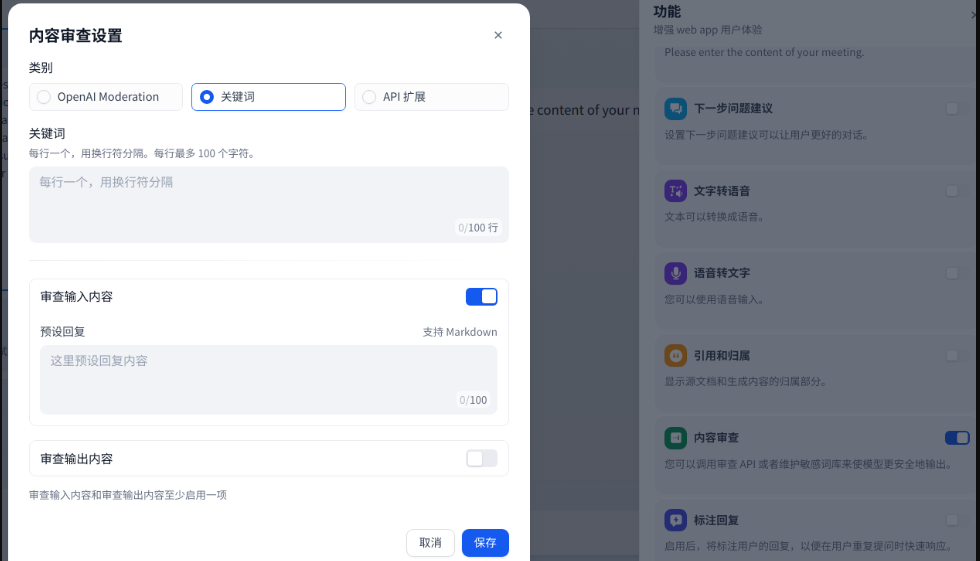
dify 提供了三种敏感词审查的策略:
-
通过openai 的 moderation(审核) 模型 -
通过关键词 -
通过自定义的api扩展
审查可以配置两个维度:
-
审查用户输入 -
审查模型输出
调用 OpenAI Moderation API
OpenAI 和大多数 LLM 公司提供的模型,都带有内容审查功能,确保不会输出包含有争议的内容,比如暴力,性和非法行为。
from openai import OpenAI
client = OpenAI()
response = client.moderations.create(
model="omni-moderation-latest",
input="...text to classify goes here...",
)
print(response)
下面是一个完整的输出示例,其中输入是来自战争电影的单个帧的图像。该模型正确预测了图像中的暴力指标,暴力类别得分大于0.8:
{
"id": "modr-970d409ef3bef3b70c73d8232df86e7d",
"model": "omni-moderation-latest",
"results": [
{
"flagged": true,
"categories": {
"sexual": false,
"sexual/minors": false,
"harassment": false,
"harassment/threatening": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"violence": true,
"violence/graphic": false
},
"category_scores": {
"sexual": 2.34135824776394e-7,
"sexual/minors": 1.6346470245419304e-7,
"harassment": 0.0011643905680426018,
"harassment/threatening": 0.0022121340080906377,
"hate": 3.1999824407395835e-7,
"hate/threatening": 2.4923252458203563e-7,
"illicit": 0.0005227032493135171,
"illicit/violent": 3.682979260160596e-7,
"self-harm": 0.0011175734280627694,
"self-harm/intent": 0.0006264858507989037,
"self-harm/instructions": 7.368592981140821e-8,
"violence": 0.8599265510337075,
"violence/graphic": 0.37701736389561064
},
"category_applied_input_types": {
"sexual": [
"image"
],
"sexual/minors": [],
"harassment": [],
"harassment/threatening": [],
"hate": [],
"hate/threatening": [],
"illicit": [],
"illicit/violent": [],
"self-harm": [
"image"
],
"self-harm/intent": [
"image"
],
"self-harm/instructions": [
"image"
],
"violence": [
"image"
],
"violence/graphic": [
"image"
]
}
}
]
}
在dify 中,可以选择审查输入或者输出内容,当审查被判断为不通过时就会你设置的输出预设的回复内容。
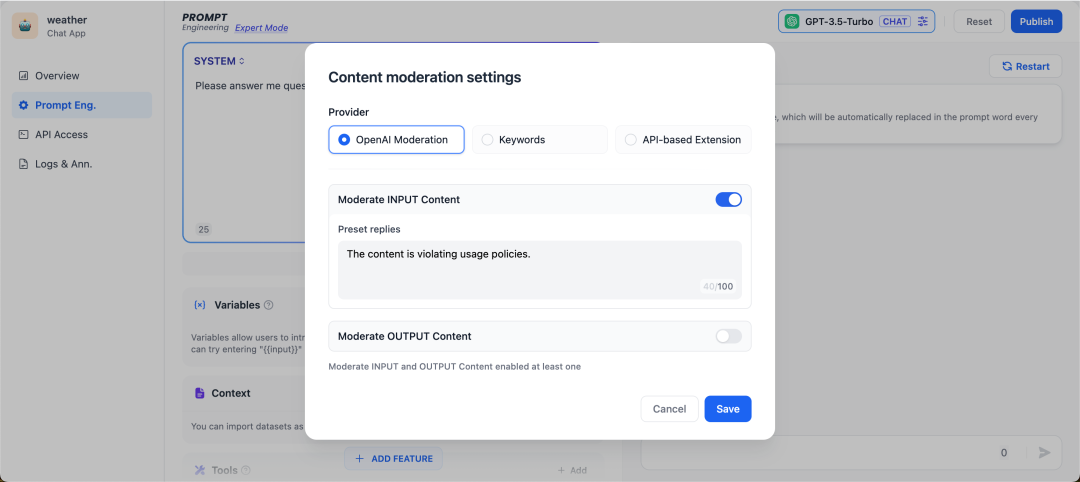
自定义关键词
开发者可以自定义需要审查的敏感词,比如把“kill”作为关键词,在用户输入的时候作审核动作,要求预设回复内容为“The content is violating usage policies.”可以预见的结果是当用户在终端输入包含“kill”的语料片段,就会触发敏感词审查工具,返回预设回复内容。
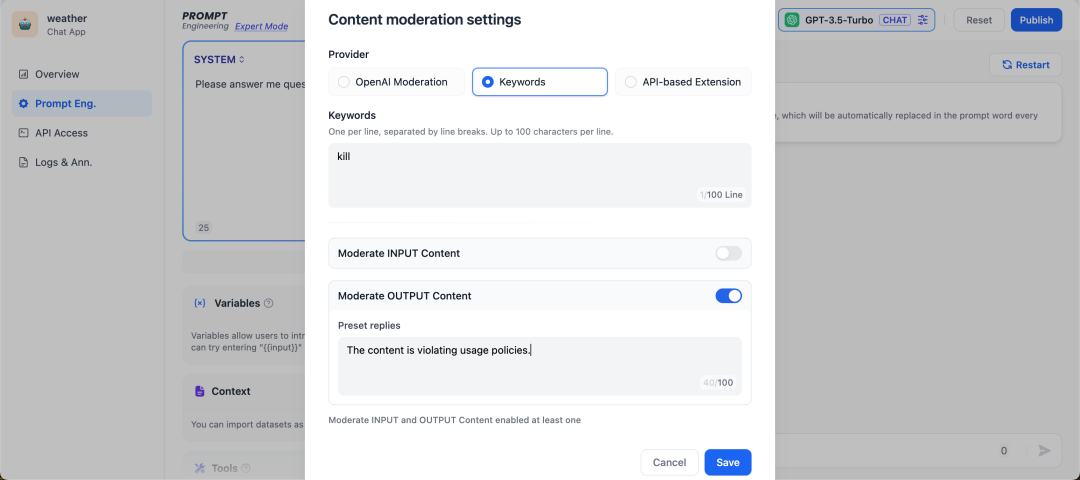
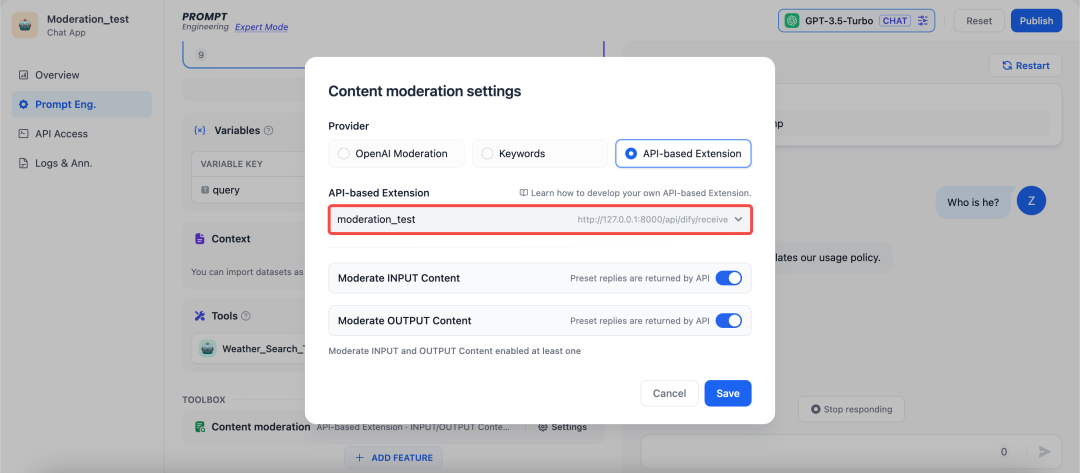
自定义拓展
不同的企业内部往往有着不同的敏感词审查机制,企业在开发自己的 AI 应用如企业内部知识库 ChatBot,需要对员工输入的查询内容作敏感词审查。为此,开发者可以根据自己企业内部的敏感词审查机制写一个 API 扩展,具体可参考 敏感内容审查,从而在 Dify 上调用,实现敏感词审查的高度自定义和隐私保护。
dify敏感词审查模块解析
Dify的moderation模块采用工厂模式设计,提供了灵活多样的审核策略,开发者可以根据实际需求定制审核流程。整个模块的核心架构如下:
ModerationFactory – 审核工厂类
作为模块的核心入口,ModerationFactory负责根据配置创建具体的审核实例。通过工厂模式,Dify实现了审核策略的灵活切换和扩展。
class ModerationFactory:
__extension_instance: Moderation
def __init__(self, name: str, app_id: str, tenant_id: str, config: dict) -> None:
extension_class = code_based_extension.extension_class(ExtensionModule.MODERATION, name)
self.__extension_instance = extension_class(app_id, tenant_id, config)
s
def moderation_for_inputs(self, inputs: dict, query: str = "") -> ModerationInputsResult:
"""
Moderation for inputs.
After the user inputs, this method will be called to perform sensitive content review
on the user inputs and return the processed results.
:param inputs: user inputs
:param query: query string (required in chat app)
:return:
"""
return self.__extension_instance.moderation_for_inputs(inputs, query)
def moderation_for_outputs(self, text: str) -> ModerationOutputsResult:
"""
Moderation for outputs.
When LLM outputs content, the front end will pass the output content (may be segmented)
to this method for sensitive content review, and the output content will be shielded if the review fails.
:param text: LLM output content
:return:
"""
return self.__extension_instance.moderation_for_outputs(text)
工厂类主要提供两个核心方法:
-
moderation_for_inputs():执行输入内容审核 -
moderation_for_outputs():执行输出内容审核
Moderation – 审核基类
作为所有具体审核类的基类,Moderation定义了审核的基本规范和通用逻辑
class Moderation(Extensible, ABC):
module: ExtensionModule = ExtensionModule.MODERATION
@abstractmethod
def moderation_for_inputs(self, inputs: dict, query: str = "") -> ModerationInputsResult:
raise NotImplementedError
@abstractmethod
def moderation_for_outputs(self, text: str) -> ModerationOutputsResult:
raise NotImplementedError
基类强制所有子类必须实现输入输出审核方法,确保了审核接口的一致性。
Moderation 实现类
KeywordsModeration – 关键词审核类
这是Dify内置的本地敏感词审查方案,通过匹配预设的敏感关键词来检测内容是否违规:
class KeywordsModeration(Moderation):
# 定义此审核类型的名称
name: str = "keywords"
@classmethod
def validate_config(cls, tenant_id: str, config: dict) -> None:
"""
验证关键词审核的配置数据
确保配置具有正确的结构并满足要求
参数:
tenant_id (str): 工作区/租户ID
config (dict): 要验证的配置数据
异常:
ValueError: 如果任何验证检查失败
"""
# 首先验证基本的输入/输出配置结构
cls._validate_inputs_and_outputs_config(config, True)
# 检查配置中是否提供了关键词
if not config.get("keywords"):
raise ValueError("keywords is required")
# 验证关键词字符串的总长度
if len(config.get("keywords", [])) > 10000:
raise ValueError("keywords length must be less than 10000")
# 按换行符分割关键词并验证行数
keywords_row_len = config["keywords"].split("n")
if len(keywords_row_len) > 100:
raise ValueError("the number of rows for the keywords must be less than 100")
def moderation_for_inputs(self, inputs: dict, query: str = "") -> ModerationInputsResult:
flagged = False
preset_response = ""
if self.config is None:
raise ValueError("The config is not set.")
# 仅在配置中启用输入审核时继续
if self.config["inputs_config"]["enabled"]:
# 获取触发审核时要使用的预设响应
preset_response = self.config["inputs_config"]["preset_response"]
# 如果提供了查询,将其添加到具有特殊键的输入中
if query:
inputs["query__"] = query
# 处理关键词 - 按换行符分割并过滤空条目
keywords_list = [keyword for keyword in self.config["keywords"].split("n") if keyword]
# 检查是否有任何输入值违反关键词
flagged = self._is_violated(inputs, keywords_list)
# 返回审核结果
return ModerationInputsResult(
flagged=flagged,
action=ModerationAction.DIRECT_OUTPUT,
preset_response=preset_response
)
def moderation_for_outputs(self, text: str) -> ModerationOutputsResult:
flagged = False
preset_response = ""
if self.config is None:
raise ValueError("The config is not set.")
# 仅在配置中启用输出审核时继续
if self.config["outputs_config"]["enabled"]:
# 处理关键词 - 按换行符分割并过滤空条目
keywords_list = [keyword for keyword in self.config["keywords"].split("n") if keyword]
# 检查文本是否违反任何关键词(包装在字典中以保持一致性)
flagged = self._is_violated({"text": text}, keywords_list)
# 获取触发审核时要使用的预设响应
preset_response = self.config["outputs_config"]["preset_response"]
# 返回审核结果
return ModerationOutputsResult(
flagged=flagged,
action=ModerationAction.DIRECT_OUTPUT,
preset_response=preset_response
)
def _is_violated(self, inputs: dict, keywords_list: list) -> bool:
"""
检查任何输入值是否包含禁止的关键词
参数:
inputs (dict): 要检查的输入数据
keywords_list (list): 禁止的关键词列表
返回:
bool: 如果在任何输入值中找到任何关键词则为True,否则为False
"""
# 检查每个输入值是否包含关键词
return any(self._check_keywords_in_value(keywords_list, value) for value in inputs.values())
def _check_keywords_in_value(self, keywords_list: Sequence[str], value: Any) -> bool:
"""
检查单个值中是否存在任何关键词
通过将值和关键词转换为小写来执行不区分大小写的比较
参数:
keywords_list (Sequence[str]): 禁止的关键词列表
value (Any): 要检查的值(转换为字符串)
返回:
bool: 如果在值中找到任何关键词则为True,否则为False
"""
# 将值转换为字符串并检查每个关键词(不区分大小写)
return any(keyword.lower() in str(value).lower() for keyword in keywords_list)
关键词审核的特点:
-
完全本地化运行:不依赖外部服务,隐私性好 -
响应速度快:简单的字符串匹配,性能高效
OpenAIModeration – OpenAI审核类
对于需要更智能识别的场景,Dify集成了OpenAI的内容审核API :
class OpenAIModeration(Moderation):
name: str = "openai_moderation"
def _is_violated(self, inputs: dict):
text = "n".join(str(inputs.values()))
model_manager = ModelManager()
model_instance = model_manager.get_model_instance(
tenant_id=self.tenant_id,
provider="openai",
model_type=ModelType.MODERATION,
model="text-moderation-stable"
)
return model_instance.invoke_moderation(text=text)
OpenAI审核的优势:
-
语义理解:能识别变体、谐音等复杂形式的违规内容 -
多维度检测:可识别仇恨、暴力、色情、自残等多类违规 -
多语言支持:支持多种语言的敏感内容识别
总结
在实际应用场景中,我倾向于采用一套精细化的审查优化策略。这套策略是经过多次实践和反馈调整而得来的,它既考虑到了效率问题,又兼顾到了准确性和灵活性。
-
多级审核策略:结合关键词匹配和AI审核,先本地快速过滤,再AI深度分析 -
上下文感知:对于某些专业场景,配置上下文相关的敏感词白名单。通过 {{variable}}语法注入会话变量(如用户角色、领域标签),这些变量可被审查模块调用,实现动态规则切换。 -
设置分数阈值(如 score_threshold=0.8),避免误判近似词
