

1. Making Text Embedders Few-Shot Learners

大型语言模型(LLMs)具有decoder-only架构,展示了显著的上下文学习(ICL)能力。这一特性使它们能够利用输入上下文中的示例有效处理熟悉和新颖的任务。认识到这一能力的潜力,我们提议利用LLMs中的ICL特性来增强文本嵌入生成过程。为此,我们引入了一个新模型bge-en-icl,该模型利用少量示例生成高质量的文本嵌入。我们的方法将任务相关的示例直接集成到查询侧,从而在各种任务中取得了显著的改进。此外,我们还研究了如何有效地利用LLMs作为嵌入模型,包括各种注意力机制、聚合方法等。我们的研究发现,保留原始框架通常能获得最佳结果。在MTEB和AIR-Bench基准上的实验结果表明,我们的方法设定了新的最佳性能。我们的模型、代码和数据集可以在https://github.com/FlagOpen/FlagEmbedding 免费获取。
论文: https://arxiv.org/pdf/2409.15700
2. HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
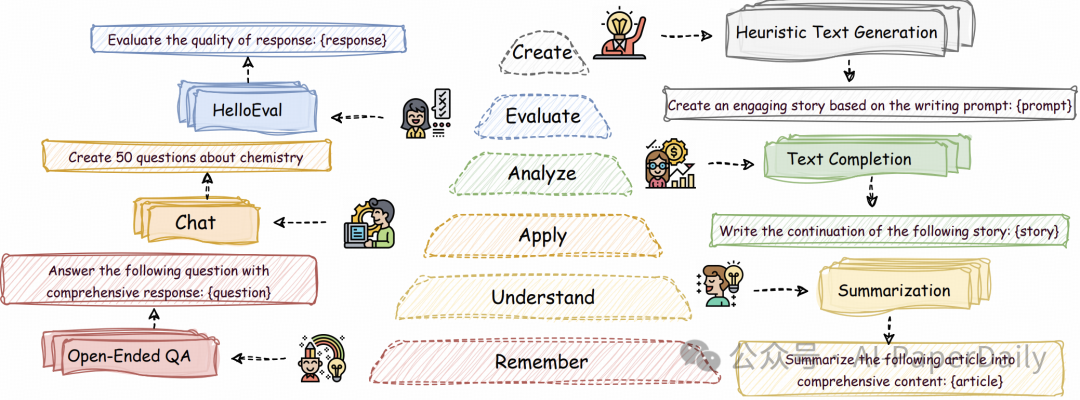
近年来,大规模语言模型(LLMs)在各种任务(例如长上下文理解)中展示了令人瞩目的能力,并且许多基准已经被提出,用于评估LLMs的能力。然而,我们观察到长文本生成能力尚未得到充分研究,这表明当前的LLMs在这方面的能力不足。因此,我们引入了层次长文本生成基准(HelloBench),这是一个全面、真实世界的问题评估基准,用于评估LLMs生成长文本的能力。基于布卢姆分类法,HelloBench将长文本生成任务分为五个子任务:开放式问答、总结、聊天、文本完成和启发式文本生成。此外,我们提出了层次长文本评估(HelloEval),这是一种与人类评估高度相关的、能够显著减少人类评估时间和精力的评估方法。我们对大约30个主流LLM进行了广泛的实验,以评估它们的长文本生成能力,并观察到大多数LLM无法生成超过4000字的文本,即使指令中包含长度限制。此外,我们观察到虽然有些LLM能够生成更长的文本,但许多问题仍然存在(例如严重的重复和质量下降,尤其是在生成长文本时)。为了证明HelloEval的有效性,我们将其与传统的指标(例如ROUGE、BLEU等)进行了比较,结果显示HelloEval与人类评估的相关性最高。我们将在https://github.com/Quehry/HelloBench发布HelloBench的代码。
论文: https://arxiv.org/pdf/2409.16191
3. MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling
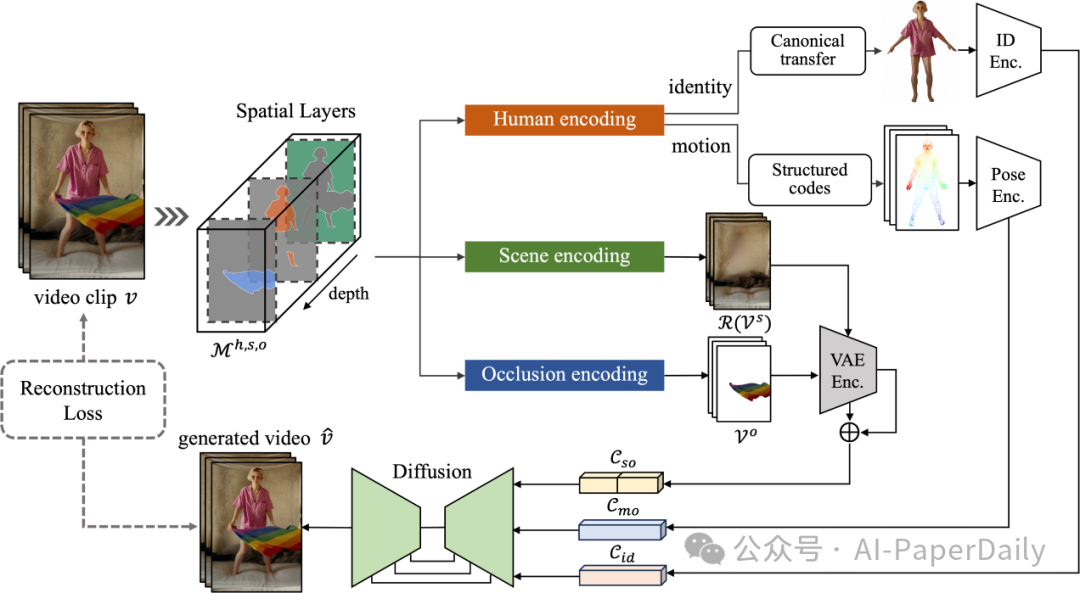
角色视频合成旨在生成具有可控特征(即角色、动作和场景)的逼真动画视频。作为计算机视觉和图形学社区的基本问题,3D 工作通常需要多视角捕捉来进行案例训练,这严重限制了它们在短时间内建模任意角色的能力。近期的2D方法通过预训练的扩散模型突破了这一限制,但它们在姿态通用性和场景交互性方面存在困难。为此,我们提出了一种名为MIMO的新框架,不仅可以根据简单的用户输入生成具有可控特征的角色视频,而且还可以同时实现对任意角色的高度可扩展性、对新型3D动作的通用性以及对互动现实场景的应用性。核心思想是将2D视频编码为紧凑的空间代码,考虑到视频发生的固有三维性质。具体来说,我们使用单目深度估计器将2D帧像素提升到三维,并基于3D深度将视频片段分解为三个空间组件(即主要人体、底层场景和漂浮遮挡物)的层次结构。这些组件进一步编码为标准身份代码、结构化动作代码和完整场景代码,这些代码被用作合成过程的控制信号。空间分解建模的设计使用户控制更加灵活,动作表达更加复杂,并且具有3D意识的合成以适应场景交互。
论文: https://arxiv.org/pdf/2409.16160
4. OmniBench: Towards The Future of Universal Omni-Language Models
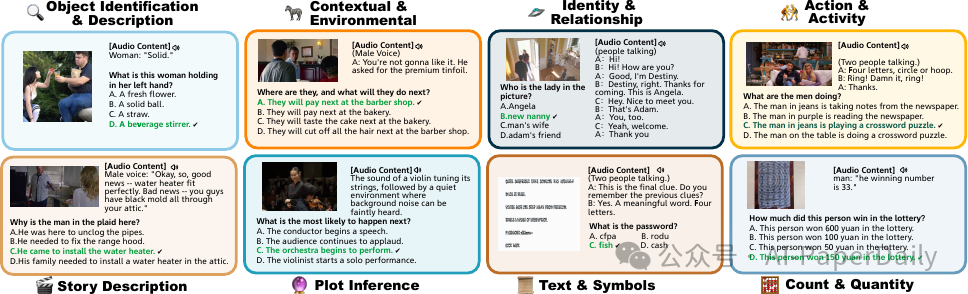
近期,多模态大规模语言模型(MLLMs)的发展旨在整合和解释来自多种模态的数据。然而,这些模型同时处理和推理多个模态的能力仍缺乏充分探索,部分原因是缺乏全面的模态特定基准。我们引入了OmniBench,这是一个新型的基准,旨在严格评估模型在同时识别、解释和推理视觉、声学和文本输入方面的能力。我们定义能够进行这种三模态处理的模型为全语言模型(OLMs),也称为全能语言模型。OmniBench 的特点是高质量的人工注释,确保准确的响应需要在所有三个模态之间进行综合理解和推理。我们的主要发现表明:i) 开源 OLMs 在三模态上下文中的指令遵循和推理能力存在显著局限;ii) 基线模型表现不佳(准确率低于50%),即使提供了图像和音频的替代文本表示也是如此,准确率仍然低于50%。这些结果表明,在现有的 MLLM 训练范式中,构建从文本、图像和音频中的一致上下文往往被忽略。我们建议未来的研究应专注于开发更 robust 的三模态整合技术和训练策略,以增强 OLM 在多种模态上的表现。代码和实时排行榜可在 https://m-a-p.ai/OmniBench 查看。
论文: https://arxiv.org/pdf/2409.15272
5. MonoFormer: One Transformer for Both Diffusion and Autoregression
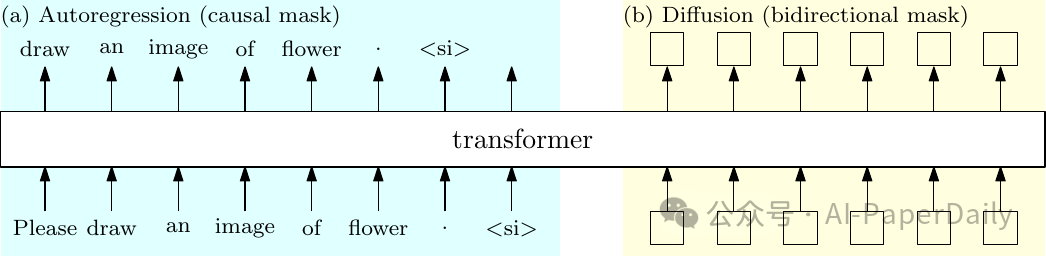
大多数现有的多模态方法要么使用单独的骨干网络进行自回归离散文本生成和扩散基连续视觉生成,要么使用相同的骨干网络通过离散化视觉数据来同时进行自回归和视觉生成。在本文中,我们提出研究一个简单的想法:为自回归和扩散共享一个transformer。可行性来自于两个主要方面:(i) transformer成功应用于视觉生成的扩散过程,(ii) 用于自回归和扩散的transformer训练非常相似,仅有的区别在于扩散使用双向注意力掩码,而自回归使用因果注意力掩码。实验结果表明,我们的方法在图像生成性能上达到了当前最先进的方法的可比水平,并且保持了文本生成的能力。
