

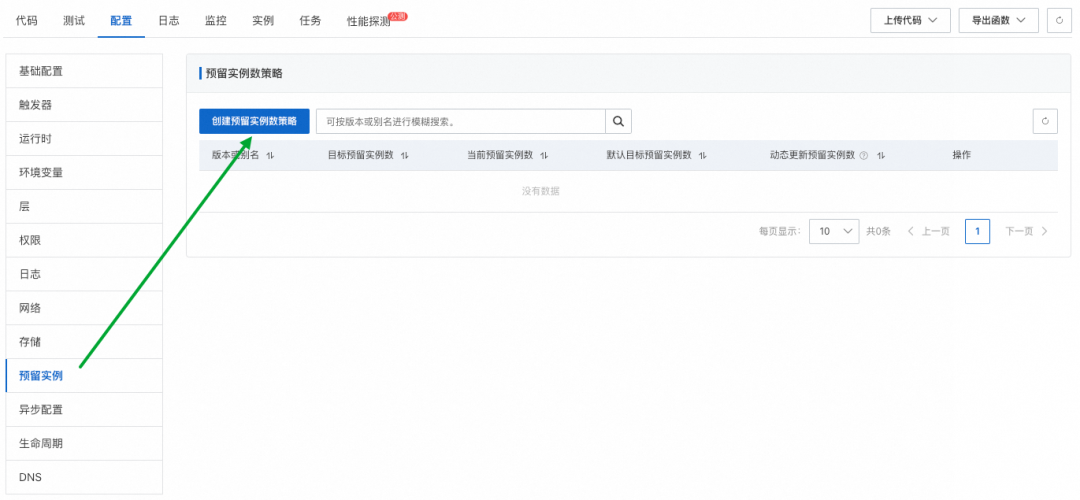
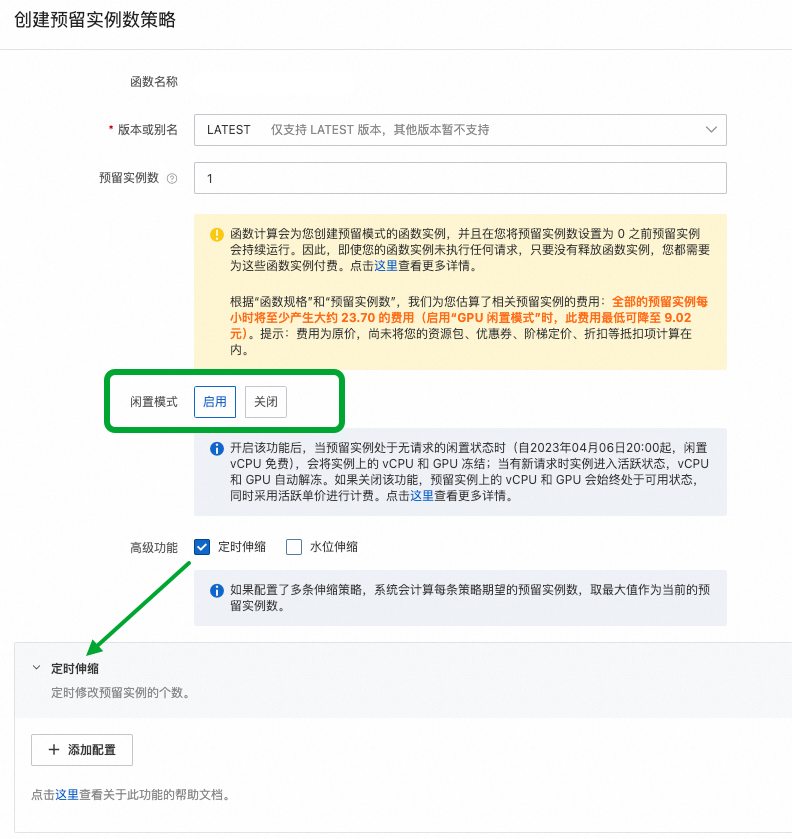
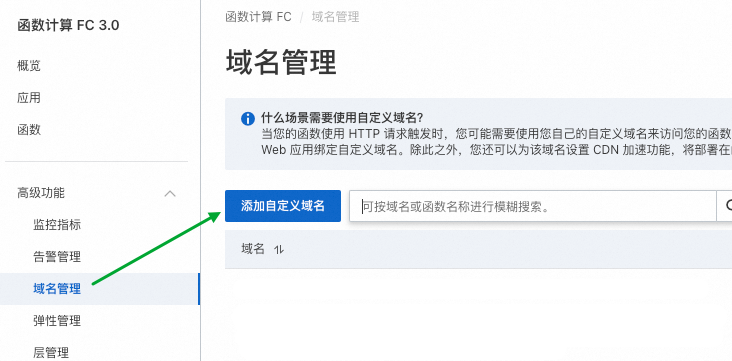
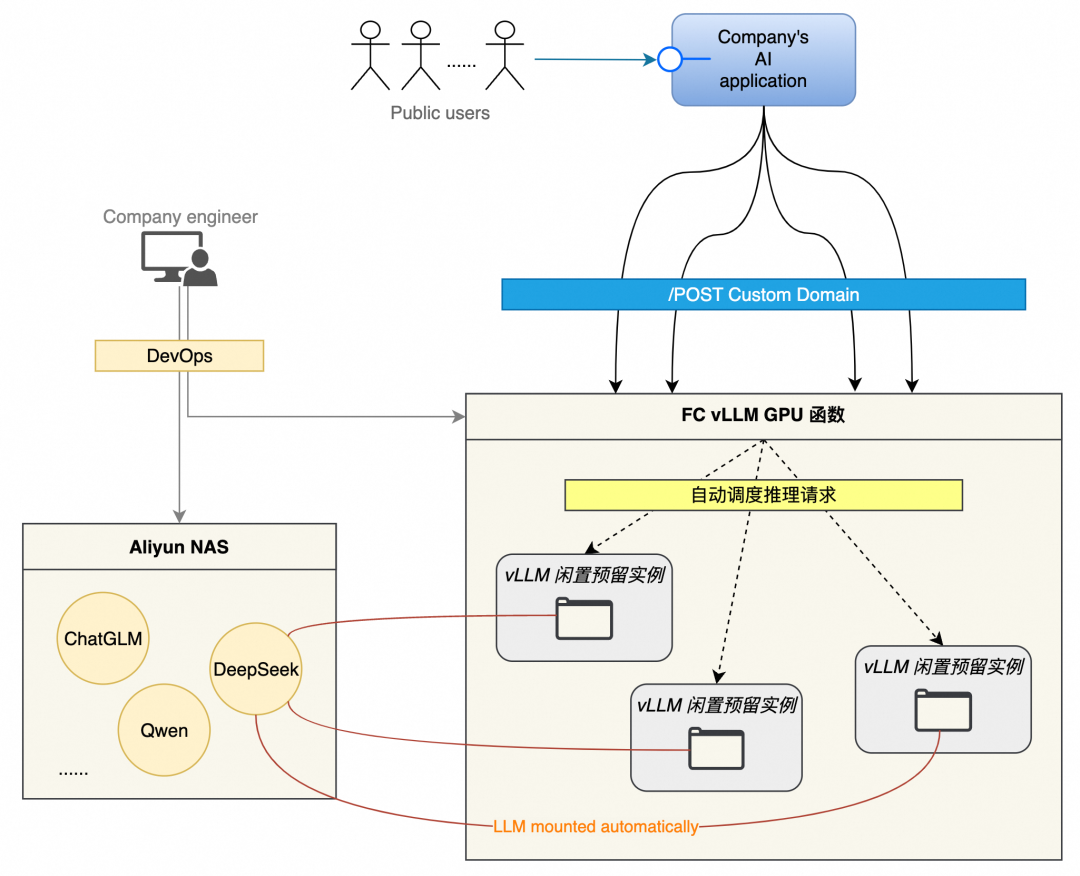
什么是 vLLM Cloud Native 针对这一现象,在大型语言模型(LLM)领域,vLLM(访问官网 https://docs.vllm.ai/en/latest/ 了解更多)应运而生。通过便捷的模型接入方式,vLLM 让用户能够轻松地向模型发起推理请求,从而大大缩短了从模型到应用的距离。vLLM 不仅降低了技术门槛,也拉近了普通用户与前沿 AI 技术之间的距离,使得更多人享受到 LLM 带来的便利和创新体验。 规模化部署 vLLM 的难点 Cloud Native 在构建和运营大规模显卡集群以支持 vLLM 时除了需要解决上述的 LLM 推理的性能及稳定性以外,还要关注成本。其中的主要难点在于底层显卡资源利用率的精确管控,资源使用的均衡性,以及显卡本身的高昂费用: 自购显卡的额外开销:自行采购显卡不仅初期投入大,而且由于市场上不同类型的显卡供应不稳定,导致资源供给不可预期。此外,显卡资源相对紧缺的情况下,企业可能需要额外支出用于囤积显卡,进一步增加了成本负担。 总结上述的各项问题,都可以将其归类为“不可能三角”:性能、成本与稳定性三者难以同时满足。具体来说: 性能与成本的优先:在追求高性能推理和低成本的情况下,系统的稳定性可能会受到挑战,如提前购置的 GPU 数量不足导致资源过分挤兑以及突发流量带来的资源压力。 为了高效管理和优化 vLLM 服务,企业在日常开发与运维中需应对以下几个关键领域: 版本控制与兼容性:确保不同版本之间的兼容性和可追溯性,便于回滚和修复问题,这对企业的技术栈提出了更高的要求。 FC GPU 预留实例闲置计费 Cloud Native FC 也天然支持高效的开发与运维能力,提供日常迭代、模型管理、多维度可观测指标、仪表盘以及运维流程,确保企业级产品的完整性和可靠性。除此之外,在请求调用方面,FC 也提供多样的请求导入机制: 这些特性使得企业可以专注于业务逻辑的创新,而不必担心底层技术实现的复杂性。 部署方式 Cloud Native 1. 上传 vLLM 镜像:使用官方提供的 vLLM Docker 镜像,无需对镜像进行任何修改,将该镜像上传至阿里云容器镜像服务(ACR)。 2. 创建函数:登录阿里云控制台,进入函数计算 3.0 管理页面,开始创建一个新的 GPU 函数,并选择适合的运行环境和配置。 3. 配置启动命令:(为了保证服务的稳定性,需添加 –enforce-eager 参数以关闭急切模式)。 更多参数配置可参考 vLLM 官方文档,根据具体需求调整配置。 5. 完成函数创建:按照上述步骤完成所有配置后,点击“创建”按钮,等待系统完成初始化。 6. 指定模型挂载路径:为了实现模型的集中管理和更新,我们强烈建议用户将模型存储在 NAS 中。NAS 可以自动挂载到 FC 函数的 vLLM 服务实例中,从而实现模型的无缝集成。 7. 配置预留实例并开启闲置计费:创建所需数量的预留实例并按需配置定时预留。 8.(可选)绑定自定义域名:通过绑定自定义域名,实现直接通过该域名进行 HTTP 调用,对外提供推理服务。 vLLM 应用集成 Cloud Native 如果您希望进一步包装 vLLM,可以将自定义域名轻松嵌入到上层服务中并封装调用。企业无需关心底层 vLLM 实例的启动、调度、负载均衡以及亲和性等细节,FC 能够确保服务的高效与稳定运行。 对于不需要观察 vLLM 实例的用户,可以直接使用基于 FC 的模型应用平台(CAP)进一步抽象部署过程,使您能够快速、轻松地将vLLM应用部署上线,大大节省了时间和精力。 《通过魔搭一键部署 DeepSeek》 总结 Cloud Native 通过 FC GPU 预留实例的闲置计费功能,企业用户能在充分利用 vLLM 的强大功能的同时找到成本、性能、稳定的最佳平衡点,并保持开发和运维的高效性。无论是将 FC vLLM 函数直接对外提供服务,还是深度集成到现有系统中,或是通过 CAP 还是魔搭来简化部署,都能找到满足您业务需求的最佳实践。人工智能产业的蓬勃发展催生了丰富多样的推理模型,为解决特定领域的问题提供了高效的解决方案。DeepSeek 的爆火就是极佳的范例。然而,对于个人用户而言,如何有效地利用这些模型成为一个显著的挑战——尽管模型触手可及,但其复杂的部署和使用流程却让人望而却步。
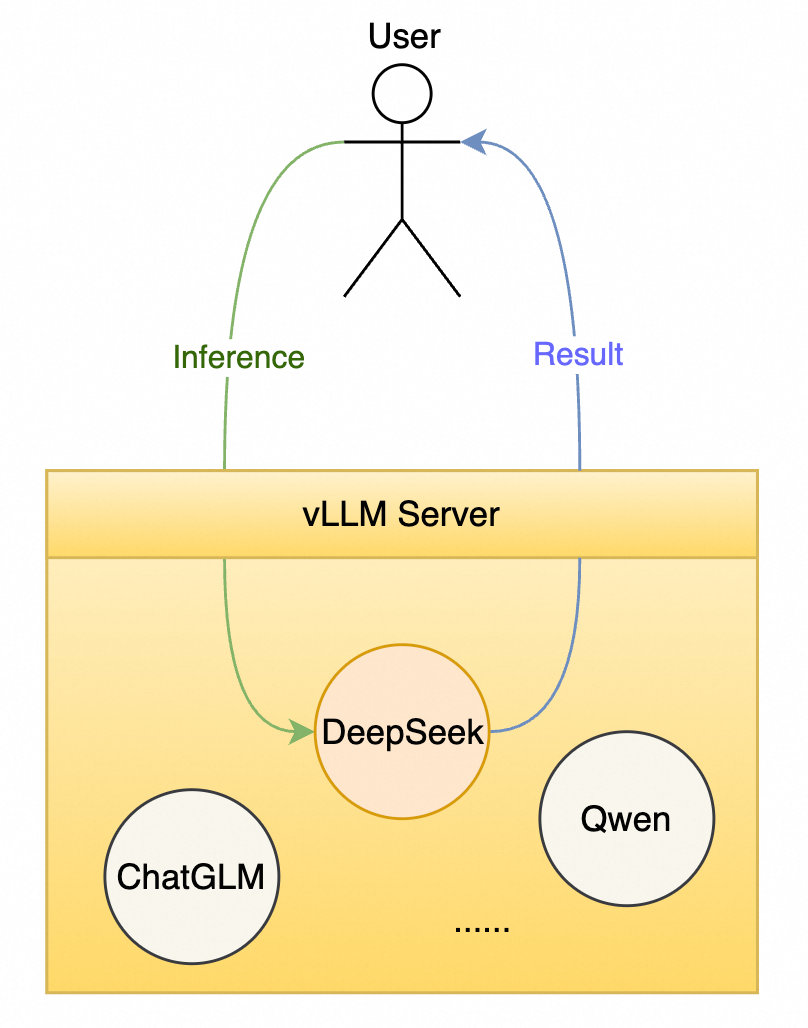
包括 DeepSeek 在内的 LLM 具备以下三大特点,各自带来不同挑战:
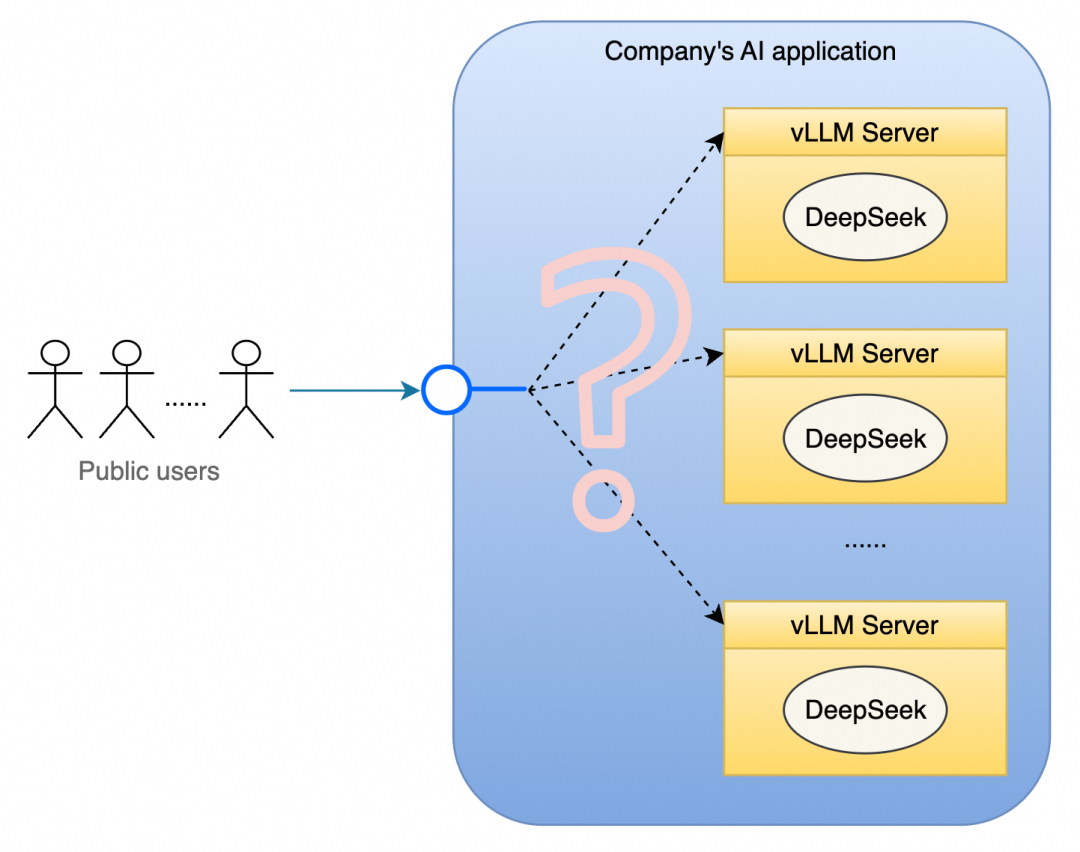
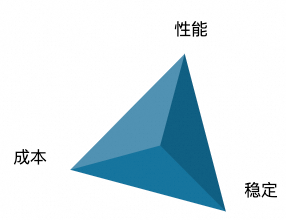
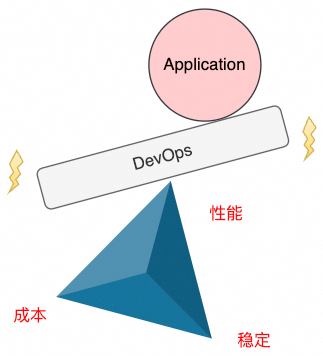
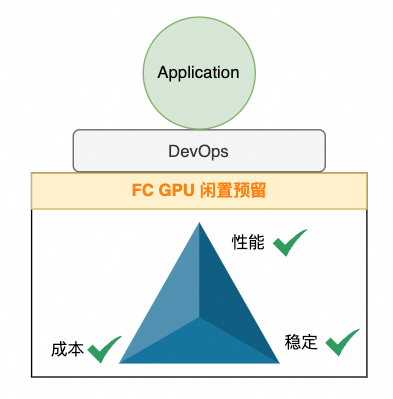
正所谓“打蛇打七寸”,针对 DeepSeek 以及众多 LLM 的特性,函数计算 (FC) 提供了通用性的解决方案——GPU 预留实例闲置计费,精准解决了性能、成本与稳定性之间的平衡难题:
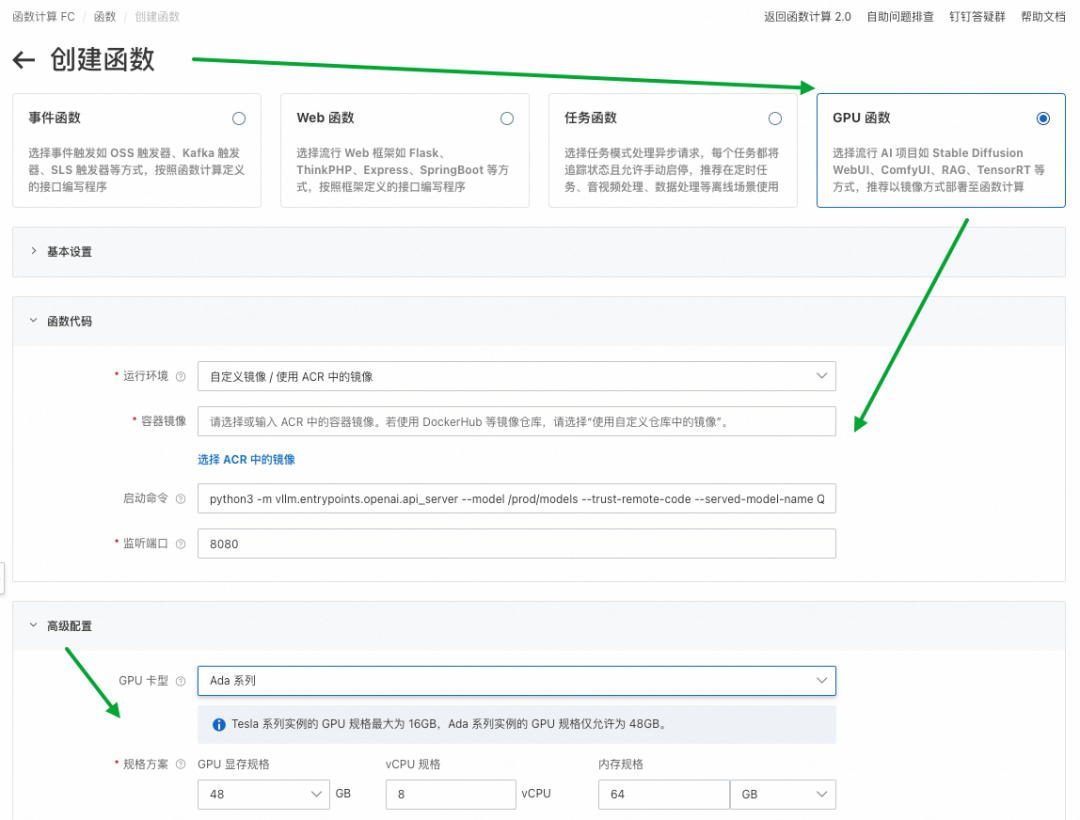
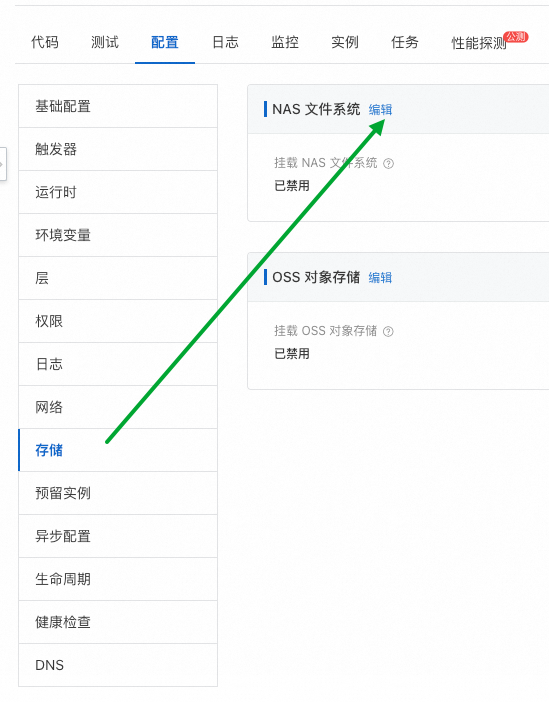
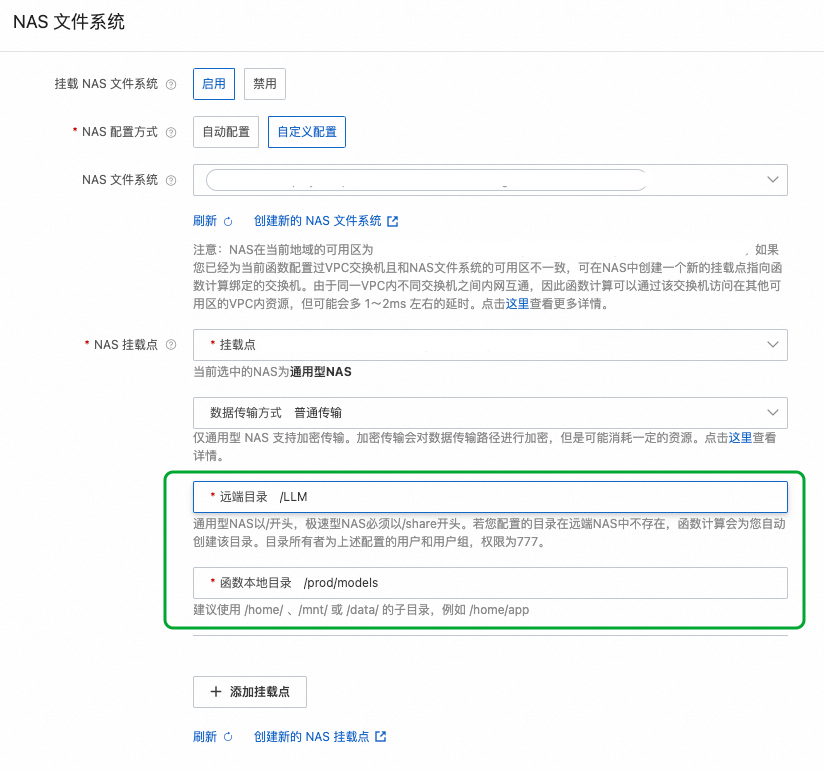
FC 提供了一套简便的 vLLM 服务框架与模型解耦的部署流程。由于 vLLM 自身支持 server 端口及路径要求,因此可以直接接入 FC 使用 GPU 预留实例,开箱即用,无需特殊配置。以下是详细的部署流程:
python3 -m vllm.entrypoints.openai.api_server --enforce-eager --model ${NAS中的模型路径} --trust-remote-code --served-model-name ${LLM模型} ...其他参数配置... --port ${函数暴露端口}
python3 -m vllm.entrypoints.openai.api_server --model /prod/models --trust-remote-code --served-model-name Qwen/Qwen-14B-Chat --gpu-memory-utilization 0.9 --max-model-len 4096 --port 8080
暂无讨论,说说你的看法吧
