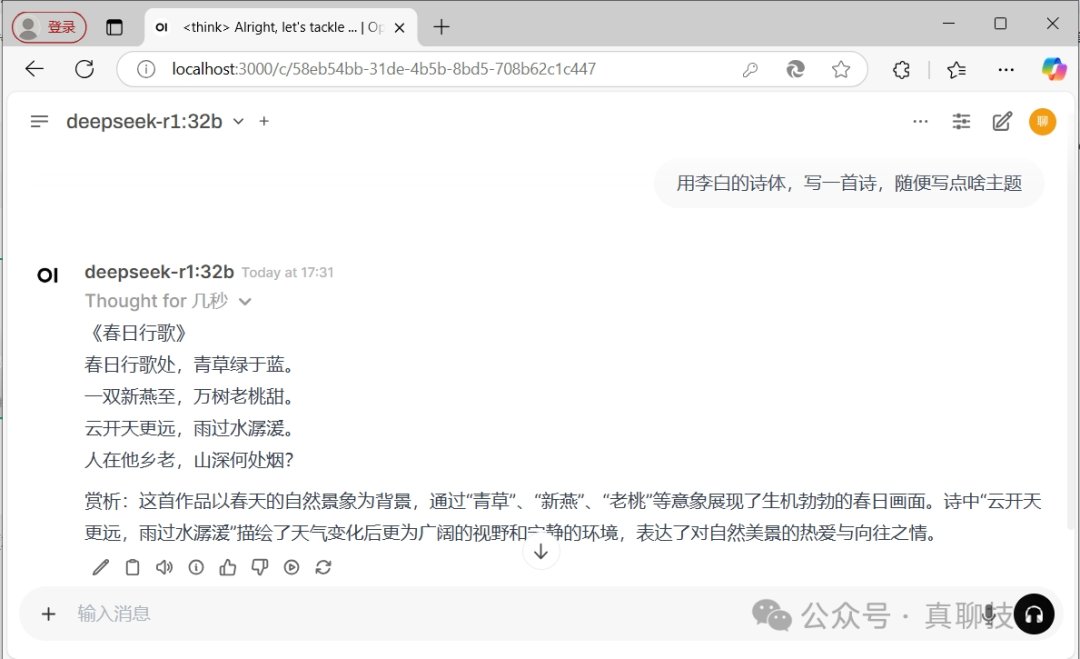
今年是 DeepSeek-R1 系列模型深入千行百业,助力企业全面拥抱 AI 变革 的关键一年!
无论企业是 自研应用,还是基于大模型推出 AIGC 产品,都需要高效部署 DeepSeek-R1。在企业级场景下,采用模型集群方案至关重要,其优势主要体现在以下几个方面:
-
成本效率与自主性
-
长期成本优化:避免云厂商API调用费用,尤其在高并发场景下边际成本更低。
-
数据主权保障:敏感数据无需外传,满足金融、医疗等行业的合规要求(如GDPR、HIPAA)。
-
定制化能力:支持模型微调(Fine-tuning)、领域适配(Domain Adaptation)及业务逻辑嵌入。
-
性能与可靠性
-
低延迟响应:本地化部署消除公网传输延迟,结合模型量化技术可实现毫秒级推理。
-
弹性扩展:通过Docker动态扩缩容应对流量波动,避免单点瓶颈。
-
高可用架构:多副本部署结合负载均衡(如Nginx/HAProxy)实现服务冗余。
-
技术可控性
-
版本迭代灵活:支持灰度发布、A/B测试,快速验证模型优化效果。
-
软硬件协同优化:可针对特定硬件(如NVIDIA GPU+NVLink)优化计算图与算子。
首先,我们在中间件选型时充分考虑了企业的综合成本,最终确定了以下技术组合:
DeepSeek-R1-32B(量化版) + Nginx + Ollama + 4090 GPU
为确保系统的高可用性,至少需要配置两块 4090 GPU。同时,在应用端设置限流机制,当模型负载达到上限时,系统会向用户提供友好的提示。
服务器繁忙,请稍后再试。
总体部署方案
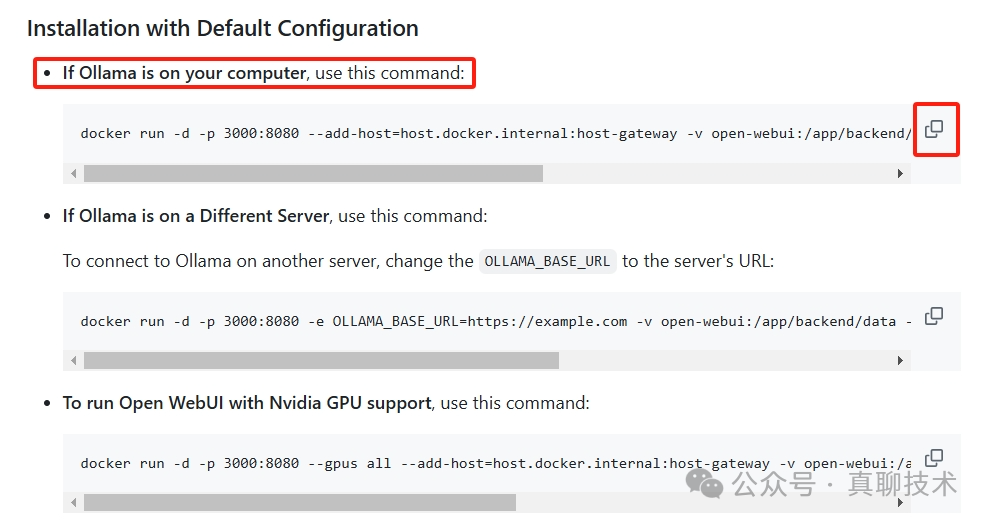
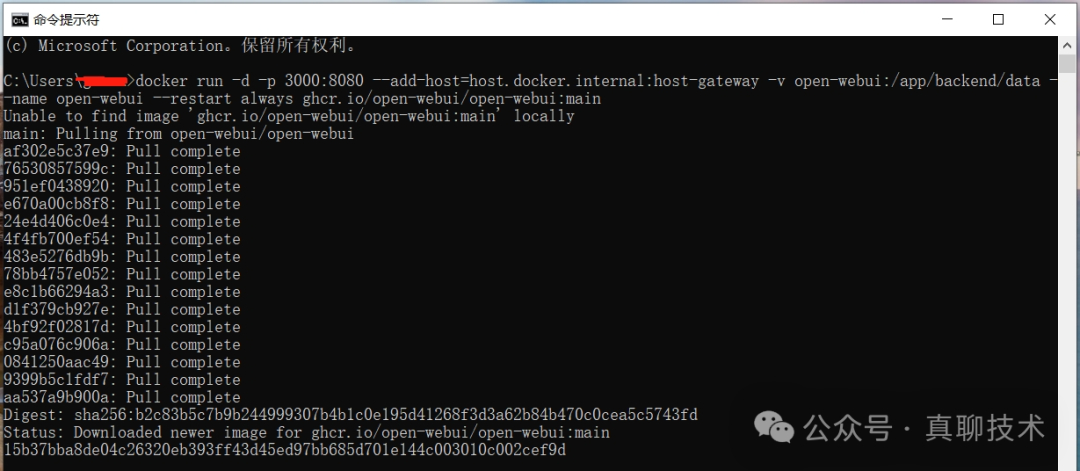
1、选择 Ollama 的 Docker 版本,便于随时跟进 Ollama 的最新版本升级。
2、采用 Nginx 反向代理,实现模型接口的负载均衡。
3、对于 DeepSeek-R1-32B,我们推荐使用基于 Ollama 量化的版本(约 20G),主要考虑其能在单块 4090 GPU 上顺利部署,同时在能力和性能上均能满足需求。当然,如果企业经济实力充足,也可以选择原始版(约 70G),此版本启动一个模型服务需要 4 块 4090 GPU,而实现高可用则需配置 8 块 4090 GPU。
Linux下Ollama的安装
执行以下命令创建与启动Docker:
sudo docker run -dp 8880:11434 --runtime=nvidia --gpus device=0 --name DeepSeek-R1-1 -v /model/deepseek-r1-32b:/root/.ollama/models ollama/ollama:0.5.7
第二个Docker可以启动8881端口,选择GPU的1号卡,名字DeepSeek-R1-2,具体命令大家自己写就可以。
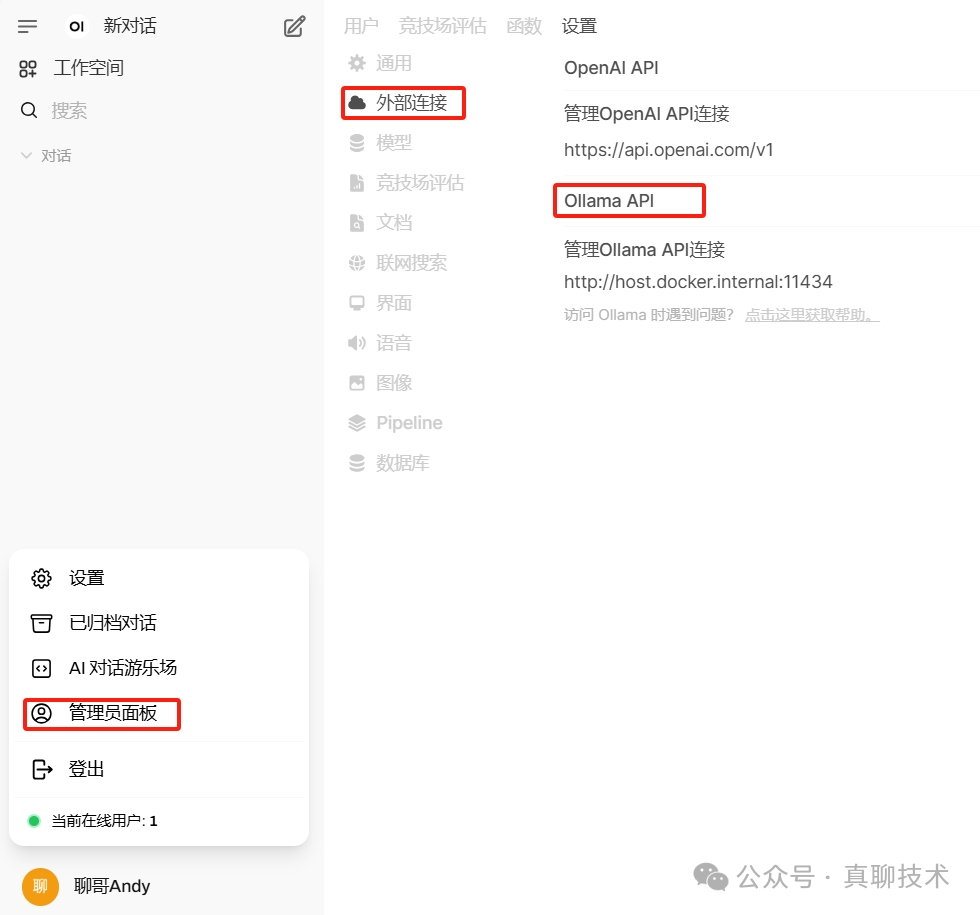
Nginx配置
实现目标:负载所有Ollama提供的模型接口,实现模型高可用配置。
Nginx配置如下:
upstream deepseek_r1_api {random;server 192.168.1.10:8880 ;server 192.168.1.11:8881 ;}server {listen 80 ;server_name _;charset utf-8;access_log /nginx/deepseek_llm.log main;location / {proxy_pass http://deepseek_r1_api;}}
请求URL示例:
http://ip:80/api/generate
请求cURL示例:
curl --location --request POST 'http://ip:80/api/generate' --header 'Content-Type: application/json' --data-raw '{ "model": "deepseek-r1:32b", "prompt":"你能做些什么?", "stream": true }'


我的提示词: