

经过多次的测验,最终总结出Markdown格式是知识库最合适的,Excel格式的文件算是支持的比较差的,所以,如果是Excel的表格数据,可以考虑转换成Markdown格式的表格,会比单纯的Excel文件上传给知识库的效果会更好。
1、表格内容转Markdown
我用DeepSeek生成了一个网页版的excel表格内容转Markdown格式的工具,需要的文末会有下载方式。
下面是我获取这个工具的一个过程,其实现在AI可以帮我们做很多工作,只要能够合理利用,会提高我们的工作效率:

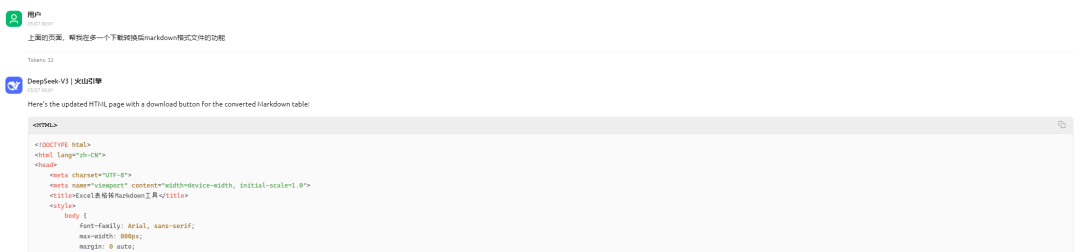
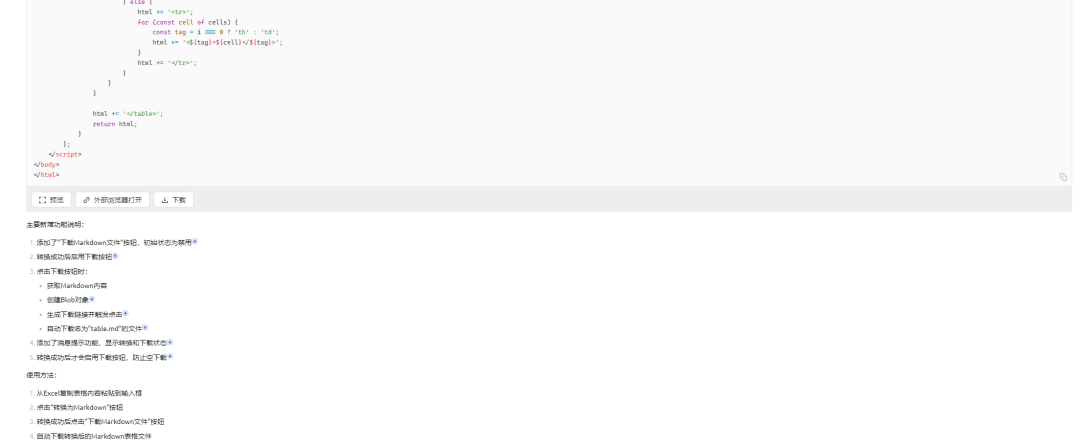
2、文本内容转Markdown
文本内容转Markdown格式我推荐一个开源项目,可以自己部署在本地或者服务器上,上传文件可以转换成markdown格式文件。
自己部署的话可以在github上下载源码去部署:
https://github.com/opendatalab/MinerU
https://mineru.net/
现在市面上Embedding模型有很多,那么我们需要选择哪一款呢?
经过我个人测试以及群友和其他大佬们的推荐,最后总结为bge-m3这款Embedding模型是最值得推荐的,
ollama pull bge-m3

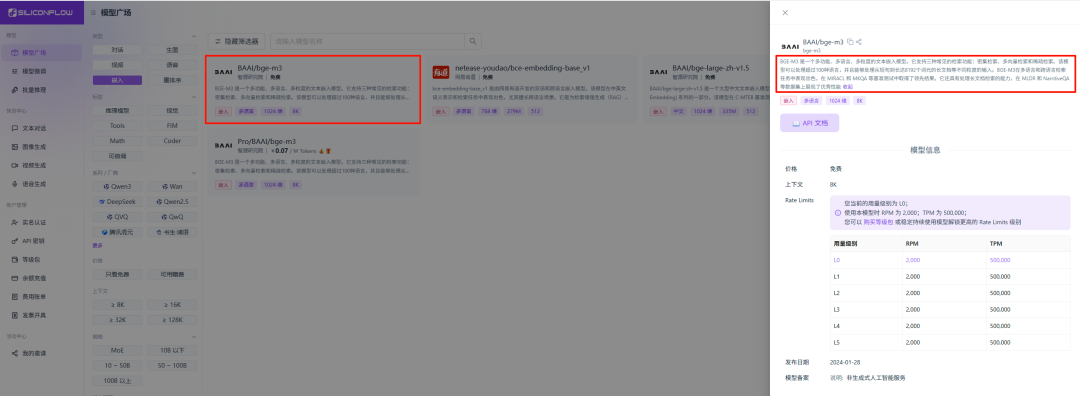
Dify的知识库提供了三种检索方式,分别是:向量检索、全文检索和混合检索这三种方式。

其中,更推荐使用混合检索的方式
将语义值拉至1,表示仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
将关键词的值拉至1,表示仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
1、可以通过调整检索算法来优化;
2、也可以通过工作流控制知识库访问来优化;
可以通过对内容的分割,把长文本的数据处理成短文本的数据,这样有助于知识库的优化检索。
同时也可以考虑根据长文本的内容或目录等结构性内容,构建知识图谱。
