

利用大模型生成模拟用户,然后再基于对这些模拟用户的访谈,来写一个真正的用户研究报告,可行吗?
对于专业的用户洞察人员来说,这个很难接受。再怎么说,他也不是真人,对吧。所以在情感上先不接受。
「他能模拟几个用户啊,够用吗?」这是对数量的质疑。
「他模拟的用户真吗?是真人的反应吗?跟真人的差别有多大?」这是对模拟质量的质疑。
对于情感上的质疑。咱们看一下隔壁技术行业。「合成数据」已经应用在各个行业里了。
在医学领域,生成合成医学图像(如X光、MRI)用于训练和验证诊断模型。
在自动驾驶领域,会在虚拟环境中生成合成驾驶数据,用于训练和测试自动驾驶系统。
合成数据是通过算法或模型生成的虚拟数据,用于模拟真实世界数据的特性,而不直接使用实际数据。
随着生成对抗网络(GANs)和其他生成模型的发展,合成数据的质量和真实性在不断提高。
甚至所谓的数据蒸馏,何尝不是一种合成数据呢。
合成用户和合成数据,是不是很像?
合成用户是指通过模拟真实用户行为和特征创建的虚拟用户,用于测试和优化产品,或提取用户需求。
其实还有个最重要的点,「合成用户」是否可用,其实不取决于从业人员,而是取决于客户。 如果客户买单,那从业人员只能跟着变。
对于数量和质量的质疑,今天正好读到了一篇论文,完美回应了这两个点。
最近,之前发布过斯坦福模拟小镇研究的团队(Park 等人)发表了一项颇具颠覆性的研究(链接见文末「阅读原文」)——他们基于大模型,模拟了 1,052 位真实用户的态度与行为(数量问题已经解决了,想模拟多少就模拟多少),并将这些“虚拟人”同真实人群做了系统对比。
1. 一项“模拟千人”的惊人实验
在这项研究中,研究团队做了两件事:

-
真实访谈 1000+ 位美国受访者:先用一个 AI 访谈机器人,与每位受访者进行深度访谈(平均两小时),收集到包括人生经历、价值观、政治立场、消费习惯等相当丰富的文本访谈资料。
-
生成“千个合成用户”:然后将每位受访者的访谈内容输入大语言模型(LLM)中,让模型“扮演”对应的受访者,以回答各类后续问题或做行为决策模拟。研究团队把这些拥有“真人访谈记忆”的模型代理,称作“生成式代理人(generative Agents)”。(这篇文章里我都叫「生成用户」)
在后续实验中,无论是针对美国常见的社会调查(如 General Social Survey 问卷),还是心理学中的大五人格量表,亦或是经济学实验游戏(例如“独裁者博弈”“信任博弈”等),这些大模型所模拟出来的“人”,在回答和决策表现上,都能与原始受访者相当接近:
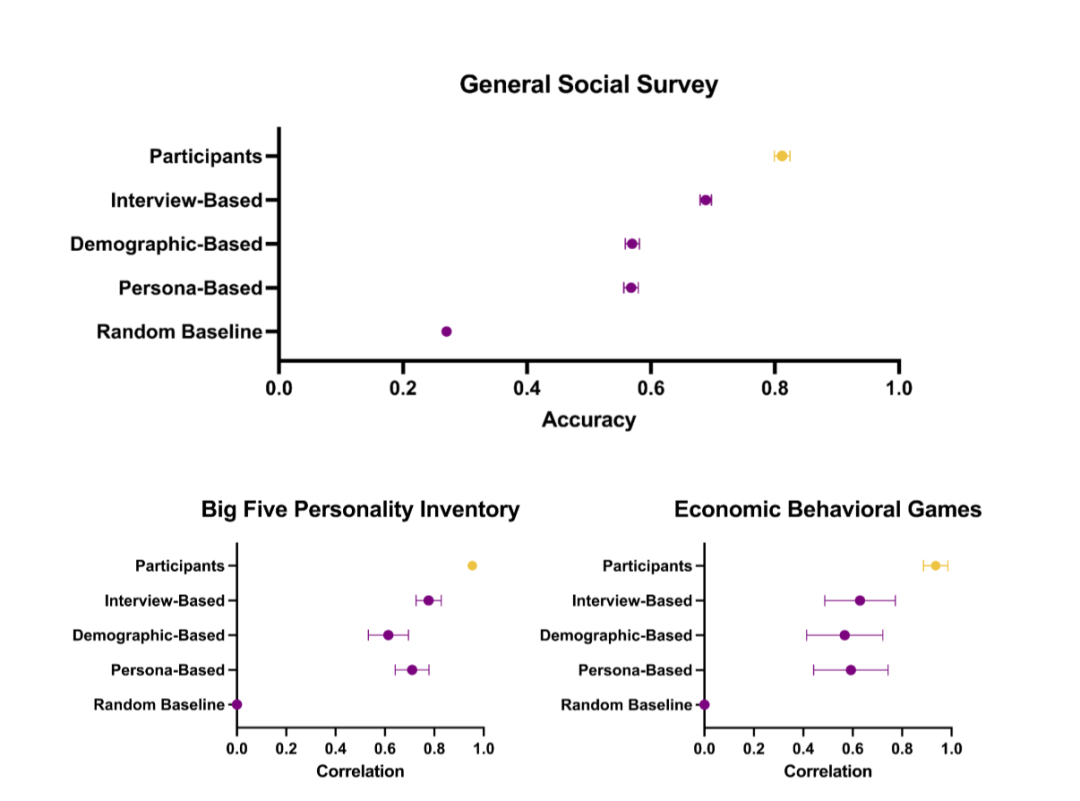
在广泛应用的社会调查 GSS 上,模型的回答与原始受访者本人的吻合度可达到 85% 左右。
在一些经典经济学博弈中,也表现出高度相关的决策模式。
此外,面对个别社会心理实验时,这些合成用户甚至能集体展现与真实人群近似的整体效应。
事实上,研究团队不仅仅创造了基于访谈材料的「合成用户」,他们还创造了基于人口学和基于简要人物描述的「合成用户」
基于人口统计学属性的合成用户
- 生成方式:
这类合成用户的构建不依赖详细访谈内容。相反,参与者在通用社会调查(GSS)中的回答被用于重建他们的人口统计学描述。这些描述包括年龄、普查区域、政治意识形态、政党偏好、教育程度、种族、民族、性别、收入、居住地和性取向。在提示语言模型时,访谈内容会被这些人口统计学描述所取代。
这种方式生成的「合成用户」仅基于有限的人口统计学信息,将个体扁平化为人口统计学刻板印象。相比于基于访谈的合成用户,这种合成用户在预测个体行为和态度方面的准确性较低。
基于简要人物描述的合成用户
- 生成方式:
在完成第一阶段的调查和实验后,参与者被要求撰写一段简短的段落来描述自己,就像向陌生人介绍自己一样,包括个人背景、性格和人口统计信息。例如,描述可能包括年龄、居住地、家庭背景、兴趣爱好和价值观。在构建这种合成用户时,语言模型会以这些简要的人物描述作为输入,而不是详细的访谈记录。
这种方式生成的「合成用户」提供的信息比纯粹的人口统计学信息更丰富,能够捕捉到一些个体的独特特征,但不如详细访谈全面。对人类行为的预测准确性通常低于基于访谈的合成用户,但高于基于纯粹人口统计学信息的。
这三种合成用户在生成方式上最主要的区别在于它们用于构建合成用户“记忆”和指导语言模型的信息来源不同。
-
详细访谈提供了最深入、最个性化的信息,从而产生了预测性能最好且偏见最小的合成用户。 -
基于人口统计学属性的合成用户最为简化,导致预测准确性较低且群体差异较大。 -
基于简要人物描述的合成用户则试图在信息丰富度和构建成本之间取得平衡。
整体上,基于详细访谈生成的「合成用户」,几乎就是真人观点和行为的某种“克隆体”。
这意味着什么?
如果我们想了解某个群体对新产品、新概念的需求,或者对某种商业产品的反馈——也许不一定要反复去找真人做访问或调研,先让这群合成用户尝试回应,可能就能得到一个初步且与真实受众较接近的方向性结果。
2. 为何这份研究值得从业者者关注?
(1)大样本的“用户画像”更鲜活
以往我们做用户研究,往往依赖问卷、定量大数据或少量深度访谈。深度访谈固然能捕捉用户更细腻的感受,但成本高、数量有限。
这个研究恰恰结合了规模与深度:先进行两小时的深度访谈,再让大模型吸收这些信息,去模拟一千多人的个性与选择决策。这种大规模、高细腻度的“用户画像”在传统研究中并不常见。
市面上的一些合成用户平台,也最多给你生成十几个用户了事,这一个研究就生成了 1000+ 用户。这得益于他们开发了一个 AI 访谈应用,才能高效执行。感兴趣的创业者们可以去附录看一下完整步骤,直接照着这个开干了。

(2)怎么利用这些合成用户?
如果客户想知道某个新概念或新产品在用户面前的接受度如何,过去做焦点小组、做深访,需要大量协调和长周期。若这种大模型合成用户能够相对真实地“还原”用户态度,研究者就能在短时间内针对不同人群开展多轮快节奏的调研迭代:
-
先在虚拟人群里试验初稿
-
筛选出关注点
-
再交给小范围真实用户做验证或补充
这在一定程度上可以加快探索和原型迭代的效率,帮助企业或组织在投入真正的大范围线下调研前,抢占先机。
3. 对用户研究行业的启示与挑战
1.启示: 大规模合成用户访谈的“预演”
数字人都能做直播了,合成数据在各种场景中应用,利用合成用户做用户洞察,是不是也不是那么不可接受了?
如果在立项早期就能批量“问”一千个“虚拟用户”,还可以通过修改访谈数据库来“生成”不同文化和背景的用户,再观察不同方向的结果。某些营销策略或体验方案也许就能在数小时内跑完初步“验证”。
对用户研究从业者而言,未来可能不再只是建用户画像、做访问,更要懂得如何设计多轮对话场景、让 AI 合成用户有效地“演练”不同需求场景。
2.准确度与“人味儿”怎么取舍
有一些市场研究还需要入户,还需要做货架实验,甚至做人类学观察,这些研究方法都有他们独特的价值。合成用户,也有问题。
纯粹的数字模拟始终无法完美复制人的情感变化、突发想法以及复杂社会互动。特别在用户研究中,有时一个现场的表情、迟疑、语气,都很能启发研究者。
这些大模型虽能做大量基础预判,但真实访谈、可观测的现场环境、长期跟进可能依旧不可替代。研究里也强调,最终要与真人的再访谈进行对比和补充。
4. 写在最后:从“采访千人”到“模拟千人”,未来的想象与边界
这项“模拟一千人”的研究,除了让用户洞察从业者,能预知到当前的技术发展,更重要的,是给我们一个发人深省的思考:在大模型的协助下,我们能否更低成本、更高效率地“预见”人们的态度与决策?
虽然目前还只是初步探索,但已让我们感受到技术带来的巨大潜能:
-
在产品概念验证、市场洞察、用户需求挖掘等方面,模拟用户群可能成为一种常规手段。
-
对于用户研究员来说,专业能力不但不会被替代,反而变得更重要:前期深度访谈的设计、关键问题的提炼、对结果的洞察能力都至关重要,能保证“合成用户”更加逼近真实人群的多样与复杂。
对于任何想在大模型时代快速验证新想法、洞察用户行为的从业者,这篇研究都值得仔细琢磨。借助这份前沿探索,我们或许可以一同见证:当用户研究与大模型结合,可能催生出新的研究范式,亦或引领出商业与社会决策的全新思路。
参考文献
Park, J. S., Zou, C. Q., Shaw, A., Hill, B. M., Cai, C., Morris, M. R., … & Bernstein, M. S. (2024). Generative agent simulations of 1,000 people. arXiv preprint arXiv:2411.10109.
