

嘿,大家好!这里是一个专注于前沿AI和智能体的频道~
前几天,看到genspark的Super Agent达到了千万美元ARR,刷新了AI产品的最快记录的新闻。AI Agents 正在被大家们所认可。 今天给家人们聊聊,AI Agent时代的AI原生浏览器。大家可能已经注意到,无论是 OpenAI 还是谷歌,又或者Manus这些,都在让 AI Agent 具备浏览和操作网页的能力。Agent 们要完成任务,很多时候都离不开互联网这个巨大的信息源和交互界面。

但问题来了,我们现在用的浏览器,比如 Chrome、Safari,都是为咱们人类设计的。它们有漂亮的图形界面,适合我们用鼠标点点点。可 AI Agent 呢?它们大多运行在云端服务器上,没有显示器,也不需要“看”网页。让 Agent 去用一个为人类视觉优化的工具,是不是有点“水土不服”?这就像让一个只会代码交互的程序去操作一个复杂的图形软件,效率低下不说,还可能处处碰壁。
那么,为什么 AI Agent 需要拥有属于它们自己的、专门设计的浏览器呢?
传统浏览器不适用于AI 大模型
传统浏览器是为人类在本地电脑上使用而优化的,而 AI Agent 通常部署在云端服务器上,需要以编程方式、大规模地运行。直接在服务器上跑成百上千个为图形界面优化的浏览器实例,性能开销巨大,管理起来也极其复杂。
其次,这些浏览器的设计核心是用户体验(UX),充斥着各种为人类交互设计的范式,比如按钮、菜单、视觉布局。AI Agent 通过代码控制这些元素,远不如直接调用 API 来得高效和稳定。
传统自动化的难题
有人可能会说,不是有像 Puppeteer 和 Playwright 这样的 headless browser 库吗?它们允许我们用代码控制浏览器,进行自动化操作和数据抓取(Scraping)。这确实是目前的主流方式,但实际确有各种问题。
常见的问题一般有3个:
动态加载。现在的网页大量使用 JavaScript 动态加载内容,你用简单的 HTTP 请求抓到的 HTML 往往是不完整的。必须得模拟一个完整的浏览器环境,运行页面脚本,才能拿到真正的数据。很多数据是在初始加载后才逐步出现的。
交互问题。很多时候,我们需要的数据并非直接可见,而是需要点击按钮、填写表单、滚动页面才能获取。比如,想抓取一篇文章,结果被一个要求输入邮箱的弹窗挡住了。这就需要编写复杂的自动化脚本来模拟人类操作。
反爬。网站为了防止被机器人薅秃,部署了各种反爬虫机制。最常见的就是验证码(CAPTCHA),还有更高级的浏览器指纹识别、用户行为分析等。开发者需要用各种技巧伪装请求,比如使用代理 IP、模拟真实浏览器头信息,过程繁琐且成功率无法保证。
就算绕过了反爬,选择器也让人脑壳疼。目前控制浏览器的主要方式是 CSS 选择器,用来定位页面上的元素。但这些选择器非常的脆弱,网页前端代码稍微一改动(比如开发者调整了 div 结构或 class 名称),之前写好的脚本立刻就崩溃了。维护这些脚本需要耗费大量精力。
最后,一些自动化库为了提供全面的浏览器功能,打包了大量 AI Agent 可能根本用不到的东西。从而导致他们可能安装包巨大,影响云端部署。
AI Agent 的特殊诉求:光自动化还不够
上面说的还只是传统自动化的问题。当主角换成 AI Agent 时,需求又上了一个层次。
AI Agent 不仅仅是执行预设脚本的机器人,它们需要具备一定的自主决策能力。比如,在一个购物网站上,Agent 需要根据用户的模糊指令(“帮我找个性价比高的蓝牙耳机”)自行判断去哪些页面搜索、如何筛选商品、解析哪些信息。这需要 Agent 能够理解网页的上下文和结构,而不是仅仅依赖写死的 CSS 选择器。
它们还需要适应动态变化的网络环境。网站界面和内容是经常变化的。传统的 RPA(机器人流程自动化)脚本在这种情况下需要人工更新,而理想的 AI Agent 应该能更智能地适应这些变化,就像人类一样,看到按钮换了个位置也能找到。最近 Reddit 上也有谈 AI 浏览器自动化相比 RPA 的适应性优势。
此外,很多应用场景需要大规模并发。想象一下,一个 AI 客服系统可能需要同时处理成百上千个用户的网页查询请求。这就要求底层的浏览器基础设施具备极高的可扩展性,能够瞬时启动并管理大量的浏览器会话。Browserbase 就特别强调了它们能在毫秒内启动数千个浏览器的能力。
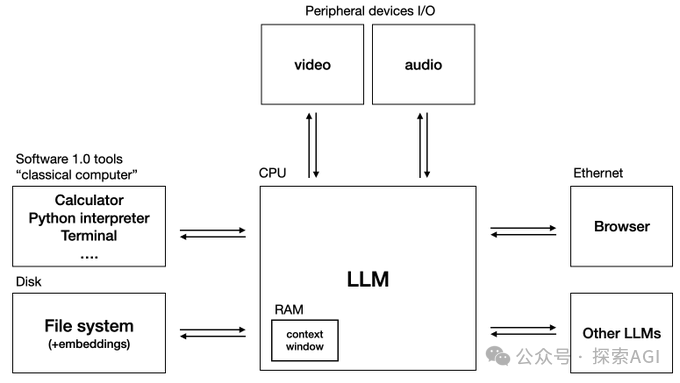
更直接的需求来自大模型。无论是通过 RAG(检索增强生成)让 LLM 获取最新知识,还是通过 Plugins/Web Agents 让 LLM 自主执行网络任务,都需要一个稳定、高效、易于集成的浏览器接口。Andrej Karpathy 在他构想的 “LLM 操作系统” 中,就把浏览器和文件系统、向量数据库并列为核心基础组件。这足以说明浏览器对于发挥 LLM 能力的重要性。
“AI 原生”浏览器
面对传统浏览器的局限和 AI Agent 的新需求,行业开始呼唤一种全新的、“为 AI 而生”的浏览器解决方案。那有没有这相关做得好的创业公司呢? 有的,Browserbase 的创始人 Paul Klein 很早就洞察到了这一点,在一个早期的访谈中他谈到。
这种新一代方案应该是什么样子?
首先,它需要是一个高度优化、轻量级、云原生的基础设施。告别臃肿的依赖和复杂的部署,能够轻松扩展,支持大规模并发。这正是像 Browserbase 这样的公司在努力的方向,它们提供基于云的 headless browser 服务,让开发者专注于 AI 逻辑,而不是浏览器运维。
其次,也是最关键的,是用 AI 赋予浏览器“超能力”。不再依赖脆弱的 CSS 选择器,而是利用 LLM 来理解网页结构和内容,甚至用 VLM(视觉语言模型)直接“看懂”页面截图。
开发者可以用更自然的方式与浏览器交互,比如直接下指令:“找到价格信息”或“点击那个红色的登录按钮”。Browserbase 推出的 Stagehand 框架就是一个尝试,它允许用自然语言指令来驱动浏览器操作。
同时,还需要更智能的信息检索能力。AI Agent 不仅要能在网页上“行动”,还需要高效地“查找”信息。像 Exa 这样专门为 AI 设计的搜索引擎,通过语义理解提供比传统关键词搜索更精准的结果,能更好地满足 Agent 进行研究、分析等任务的需求。
最后,这一切都需要通过全新的、开发者友好的接口(SDK/API)来提供。接口设计需要更适应 AI Agent 的工作模式,比如更好地处理异步操作、重试和复杂逻辑分支。
最后
AI Agent 专用浏览器的重要性,不仅仅是几家初创公司的判断,也得到了行业巨头的印证。
OpenAI 推出了具备浏览能力的 Operator,运行在远程 Chromium 实例上。谷歌也被曝出正在开发 Project Mariner,一个能控制浏览器完成在线任务的 AI 系统。甚至连浏览器厂商 Opera 也在其浏览器中内置了能执行网页任务的 AI Agent。
这些动作清晰地表明,让 AI Agent 无缝、高效地与网络交互,已经成为 AI 发展的重要方向。
当然,打造完美的 AI Agent 浏览器并非易事。如何持续有效地对抗反爬虫机制?如何确保安全性,防止 Agent 被恶意利用?如何处理数据隐私和伦理问题?如何提高 Agent 操作的可靠性和准确性?这些都是需要不断探索和解决的挑战。
但方向是明确的:AI Agent 的未来,与其有效浏览和与网络交互的能力密不可分。传统浏览器显然无法完全满足这一需求。
所以,回到最初的问题:为什么 AI Agent 需要自己的浏览器?
因为它们需要在云端大规模运行,需要以代码高效控制,需要理解网页内容并自主决策,需要适应动态变化,需要与 LLM 无缝集成。而这一切,都是为人类设计的传统浏览器及其自动化工具难以完美提供的。
一个专为 AI 设计、由 AI 赋能的浏览器基础设施,正在成为释放 AI Agent 全部潜力的关键钥匙。像 Browserbase 和 Exa 这样的先行者,正在为我们构建这个未来。
