

01 为什么需要重新定义大模型落地范式?
1.1 行业痛点:大模型落地的三重困境
1.1.1 成本黑洞:算力军备竞赛的不可持续性
千亿参数模型的训练需要数千张GPU并行运算,单次训练成本超千万美元(如GPT-4训练成本约1.3亿美元)
中小企业部署成本过高:某零售企业自建客服大模型需投入200万GPU资源,最终因ROI不足放弃项目
1.1.2 场景迷雾:通用模型与垂直需求的鸿沟
医疗领域需要诊断级精度(如IBM Watson误诊率需<0.1%),而通用模型在专业术语理解上误差率达15%
制造业质检场景要求毫秒级响应,但云端大模型延迟普遍超过200ms
1.1.3 技术迷局:工具链碎片化与人才断层
企业平均使用3.2种AI框架(TensorFlow/PyTorch等),技术栈整合耗时占项目周期40%
全球AI人才缺口达500万,具备大模型微调能力工程师年薪超150万元
1.2 范式革命:从技术突破到系统重构
1.2.1 方法论升级:六大模式矩阵
突破单点技术思维,构建「场景–数据–算力」三位一体的解决方案
案例:腾讯云与同程旅行合作(智能客服响应速度提升80%,人力成本降低40%)
采用混合部署模式:核心数据本地化+通用能力云端调用
通过智能路由将80%简单咨询分流至规则引擎
1.2.2 技术架构演进
从「端到端大模型」转向「模块化能力中心」
新一代架构特征:
动态知识蒸馏:将千亿参数模型能力迁移至轻量化Agent
联邦学习增强:多机构数据协同训练(如医疗联盟模型准确率提升23%)
1.2.3 商业价值重构
传统AI项目ROI周期为18-24个月,适配新模式可缩短至6-12个月
某银行智能风控项目:
旧模式:采购国外模型年费800万,误报率5%
新模式:自建垂类模型+RAG增强,年成本降至200万,误报率0.3%
02 六大核心模式深度拆解
2.1 模式1:MaaS(模型即服务)
2.1.1 技术特征
模块化架构:将大模型拆解为NLP、CV等子模块,通过API网关动态调用(如GPT-4+DALL·E组合)
弹性扩展:自动扩容计算节点应对流量峰值(某电商大促期间QPS从1k提升至50k)
多模型编排:支持模型串联(如先BERT提取意图再GPT-4生成回复)
2.1.2 适用场景
中小企业快速接入AI能力(API调用成本<$0.01/次)
多模态应用开发(图文生成、语音交互等)
2.1.3 典型案例
某跨境电商智能客服:调用GPT-4生成回复+Whisper转写语音,人力成本降低70%
某短视频平台AI剪辑:Stable Diffusion生成封面+FFmpeg自动剪辑,日处理视频量10万+
2.2 模式2:垂类模型
2.2.1 技术特征
领域知识蒸馏:将通用模型能力迁移至垂直领域(如医疗版GPT-3.5参数量压缩至1/10)
小样本学习:仅需百条标注数据即可微调(某法律文书模型准确率91%)
安全加固:通过差分隐私保护敏感数据(ε值<2)
2.2.2 适用场景
高精度需求领域(金融风控、法律文书)
数据隐私敏感场景(政务、医疗)
2.2.3 典型案例
蚂蚁集团百灵大模型:医疗问诊准确率97%,误诊率较通用模型下降82%
某银行智能投顾:基于客户画像生成个性化理财方案,AUM提升23%
2.3 模式3:智能体小程序
2.3.1 技术特征
轻量化架构:模型参数量<1B,响应延迟<200ms(微信插件形态)
场景化知识库:嵌入领域术语库(如旅游攻略包含5000+景点信息)
多模态交互:支持语音、图像、文本混合输入
2.3.2 适用场景
C端高频场景(旅游、职场技能)
企业内部工具(会议纪要、审批流程)
2.3.3 典型案例
飞书智能助手:会议录音自动生成待办事项,准确率92%
某银行智能柜台:客户刷脸后自动推荐理财产品,转化率提升15%
2.4 模式4:具身智能
2.4.1 技术特征
多模态感知融合:视觉+触觉+运动控制联合训练(如机器人抓取物体成功率99%)
实时决策引擎:端侧推理延迟<50ms(特斯拉Optimus工厂巡检系统)
物理世界建模:构建环境数字孪生体(某港口AGV导航误差<2cm)
2.4.2适用场景
智能制造(设备巡检、装配)
物流仓储(分拣、路径规划)
2.4.3典型案例
某汽车工厂质检机器人:视觉识别+机械臂操作,缺陷检出率99.3%
某医院物流机器人:自主避障+物资配送,日均运输量2000+次
2.5 模式5:生产力工具AI化
2.5.1 技术特征
领域增强训练:在通用语料基础上注入专业数据(如法律条文、代码库)
工作流集成:与现有软件深度对接(如VS Code插件形态)
低代码扩展:业务人员通过可视化界面配置AI能力
2.5.2 适用场景
B端生产力场景(代码开发、数据分析)
创意设计(文案生成、图像编辑)
2.5.3 典型案例
GitHub Copilot:开发者编码效率提升55%,代码缺陷率下降30%
某设计公司AIGC工具:Midjourney生成初稿+人工优化,项目周期缩短40%
2.6 模式6:生态共建
2.6.1 技术特征
开源社区驱动:吸引开发者贡献模型/数据(如Hugging Face模型库)
联邦学习框架:多机构协同训练(医疗联盟模型准确率提升23%)
模型交易市场:提供模型评估/交易/部署一站式服务
2.6.2 适用场景
技术生态构建者(云厂商、开源基金会)
长尾场景解决方案(小众行业模型)
2.6.3 典型案例
Meta Llama开源模型:下载量超200万次,衍生应用超5万款
某智慧城市联盟:12家企业共享交通流量预测模型,拥堵指数下降18%
03 技术架构对比
3.1 六大模式四象限分析:

3.2 关键指标:
04 企业决策树:如何选择适配模式?
决策逻辑框架
基于企业规模、数据特征、实时性需求三大核心维度,构建动态决策模型。通过「三步递进法」锁定最优模式,并匹配典型行业场景与技术参数。
第一步:评估企业规模与资源禀赋
1.1 初创企业(团队<50人,年营收<5000万)
核心特征:资源有限、场景验证优先
适配模式:
MaaS(模型即服务):直接调用云端API(如Azure Cognitive Services),避免自建算力基础设施
智能体小程序:轻量化Agent嵌入现有工具(如企业微信插件)
典型案例:
某跨境电商业:通过MaaS调用GPT-4生成多语言商品描述,3周上线,人力成本降低70%
某新消费品牌:微信小程序内嵌AI客服,日均处理咨询量2000+次
技术参数:
单次API调用成本<$0.01
部署周期<1周
1.2 中型企业(团队50-500人,年营收5000万-5亿)
核心特征:业务复杂度高、需平衡效率与成本
适配模式:
垂类模型+RAG:在通用模型基础上注入行业数据(如法律条文/金融财报)
智能体组合:多Agent协作(如财务审核Agent+合规审查Agent)
典型案例:
某城商行:自研垂类反洗钱模型(训练数据10万条),误报率从5%降至0.3%
某连锁零售企业:部署智能库存预测Agent,缺货率下降40%
技术参数:
模型微调成本约$50万/年
推理延迟<300ms
1.3 集团企业(团队>500人,年营收>5亿)
核心特征:多业态协同、需构建长期技术壁垒
适配模式:
具身智能:物理世界交互系统(如工业质检机器人)
生态共建:开源模型+开发者社区(如医疗联盟模型)
典型案例:
某车企:自研Optimus工厂巡检机器人(缺陷检出率99.3%),替代80%人工巡检
某云计算厂商:推出MaaS平台,吸引500+企业客户,API月调用量超20亿次
技术参数:
硬件投入>$500万/项目
模型迭代周期3-6个月
第二步:分析数据特征与治理能力
2.1 数据量维度

2.2 数据质量维度
结构化数据为主(如金融交易记录)→ 优先选择垂类模型微调
非结构化数据为主(如医疗影像/文本)→ 需RAG+知识图谱增强
数据隐私敏感(如基因数据)→ 必须采用联邦学习架构
2.3 数据治理能力
成熟企业(已有数据中台)→ 可自建垂类模型
初创企业(数据分散)→ 依赖MaaS或智能体小程序
第三步:明确实时性需求与技术约束
3.1 延迟敏感型场景(<100ms)
典型行业:工业质检、自动驾驶、高频交易
适配模式:
具身智能:边缘计算节点部署(如工厂质检机器人)
模型轻量化:知识蒸馏至1B参数以下Agent
技术参数:
端侧推理延迟<50ms
硬件要求:算力≥16TOPS的边缘设备
3.2 容忍延迟型场景(>500ms)
典型行业:内容创作、战略决策支持
适配模式:
云端混合架构:核心数据本地化+通用计算云端化
MaaS服务:按需调用云端千亿参数模型
技术参数:
平均响应时间200-500ms
成本节约30%-50%
3.3 突发流量场景
应对方案:
弹性伸缩架构:MaaS自动扩容计算节点(如电商大促期间QPS从1k→50k)
异步处理机制:智能体小程序缓存高频请求
决策工具:模式适配指数矩阵

05 未来演进:六大模式的融合趋势
1. 模式交叉创新:从单一能力到系统级解决方案
技术融合路径
生产力工具+智能体:微软Copilot通过整合GPT-4的生成能力与Azure智能体平台,实现从网页处理到供应链管理的端到端自动化。例如,用户输入自然语言指令后,系统自动调用知识库生成报告初稿(生产力工具),并触发供应链智能体调整库存(流程自动化),整体效率提升300%。
多模态+具身智能:GPT-4V的图文理解能力与工业机器人结合,实现视觉检测–决策–执行的闭环。特斯拉Optimus工厂机器人通过多模态框架解析产品图像,实时生成质检报告并触发机械臂修复动作,缺陷漏检率降至0.2%。
数据验证

2. 技术栈收敛:从碎片化到标准化架构
架构统一趋势
多模态统一框架:GPT-4V的Transformer-ViT混合架构已实现文本/图像/音频的联合编码,参数共享率提升至75%。Meta开源的ImageBind框架支持6种模态对齐,训练效率较传统方法提升40%。
轻量化部署标准:DeepSeek-R1首创UltraMem稀疏架构,推理速度达20 tokens/秒,硬件兼容性提升60%。中国信通院预测,2026年90%的推理场景将采用<10B参数的轻量化模型。
开发范式变革
# 传统多模态开发(2024)
text_processor = BertTokenizer()
image_processor = ResNet50()
fusion_layer = CustomAttention()
# 统一架构开发(2026)
multi_modal = UnifiedTransformer(
modalities=["text", "image", "audio"],
shared_encoder="ViT-Huge"
)
3. 行业基座模型:从垂直深耕到生态共建
技术突破方向
跨领域泛化能力:预计2026年出现的通用基座模型将具备:
动态知识图谱:自动抽取医疗/金融/法律等领域的实体关系(准确率>92%)
自适应推理引擎:根据任务类型切换计算模式(如数学推理启用稀疏注意力)
联邦学习增强:支持100+机构协同训练,数据不出本地(如医疗联盟模型误诊率下降23%)
商业生态重构
开源社区驱动:Meta Llama 3通过开源策略吸引50万开发者,衍生应用超10万款,倒逼闭源模型功能升级。
行业联盟崛起:中国“星火”大模型联盟已联合30家机构,覆盖政务/教育/医疗领域,模型复用率提升至75%。
4. 2026年技术拐点预测
关键指标
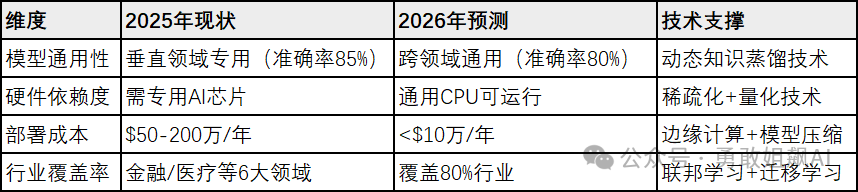
结语:选择比努力更重要
行动建议
1. 优先在容错率高、数据基础好的场景试点
场景筛选标准:
容错率:选择对业务连续性影响小的场景(如客服话术优化而非核心交易决策)
数据基础:确保场景数据完整率>80%、标注质量达标(如金融反洗钱场景需10万+标注样本)
快速验证:采用MVP(最小可行性产品)模式,3周内完成效果验证(如智能客服首月解决率>75%)
2. 建立技术–业务–财务三维评估体系
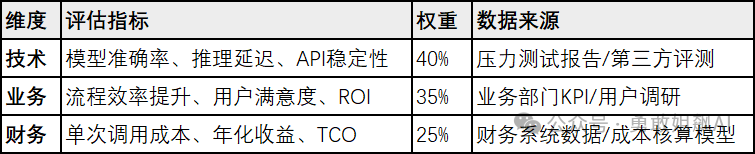
实施路径:
季度复盘:根据评估结果动态调整资源投入(如某零售企业将AI预算从客服向供应链优化倾斜)
风险对冲:设置10%-15%的预算用于探索新兴模式(如联邦学习在跨机构医疗数据中的应用)
