

一、前言
网关在网络通信中扮演着诸多角色,包括数据转发、协议转化、负载均衡、访问控制和身份验证、安全防护、内容审核,以及服务和 API 颗粒度的管控等,因此常见的网关种类有流量网关、安全网关、微服务网关、API 网关等。在不同语义下,网关的命名也会有所不同,例如 K8s 体系下,有 ingress 网关,在 Sping 体系下,有 Spring Cloud Gateway。但不论如何命名,网关的管控内容几乎都离不开流量、服务、安全和 API 这 4 个维度,只是功能侧重不同、所遵循的协议有差异。
-
相比传统 Web 应用,LLM 应用的内容生成时间更长,对话连续性对用户体验至关重要,如果避免后端插件更新导致的服务中断? -
相比传统 Web 应用,LLM 应用在服务端处理单个请求的资源消耗会大幅超过客户端,来自客户端的攻击成本更低,后端的资源开销更大,如何加固后端架构稳定性? -
很多 AGI 企业都会通过免费调用策略吸引用户,如何防止黑灰产爬取免费调用量封装成收费 API 所造成的资损? -
不同于传统 Web 应用基于信息的匹配关系,LLM 应用生成的内容则是基于人工智能推理,如果保障生产内容的合规和安全? -
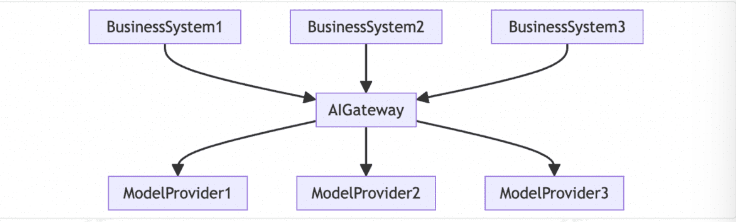
当接入多个大模型 API 时,如何屏蔽不同模型厂商 API 的调用差异,降低适配成本?
在支持大量 LLM 客户的过程中,我们也看到了一些行业发展趋势,借本文分享给大家:
-
互联网内容的生产机制将从 UGC(User Generate Content) 转变为 AIGC(Artificial Intelligence Generate Content),互联网流量增长,除了要考虑传统的 SEO,还需要考虑 AI 抓取下的 SEO。 -
目前处于 AI 时代的 Web 1.0 阶段,基于静态内容生成,可以预见,AI 时代的 Web 2.0 不久会到来,基于理解互联网内容来识别页面中提供的“可操作能力”,来完成复杂任务,真正的 Web 3.0 也将由 AI 来实现。 -
API 是 LLM 应用的一等公民,并引入了更多流量,催生企业新的生命力和想象空间。 -
LLM 应用对网关的需求超越了传统的流量管控功能,承载了更大的 AI 工程化使命。
二、AI 场景下的新场景和新需求
相比传统 Web 应用,LLM 应用在网关层的流量有以下三大特征:
-
长连接。由 AI 场景常见的 Websocket 和 SSE 协议决定,长连接的比例很高,要求网关更新配置操作对长连接无影响,不影响业务。 -
高延时。LLM 推理的响应延时比普通应用要高出很多,使得 AI 应用面向恶意攻击很脆弱,容易被构造慢请求进行异步并发攻击,攻击者的成本低,但服务端的开销很高。 -
大带宽。结合 LLM 上下文来回传输,以及高延时的特性,AI 场景对带宽的消耗远超普通应用,网关如果没有实现较好的流式处理能力和内存回收机制,容易导致内存快速上涨。
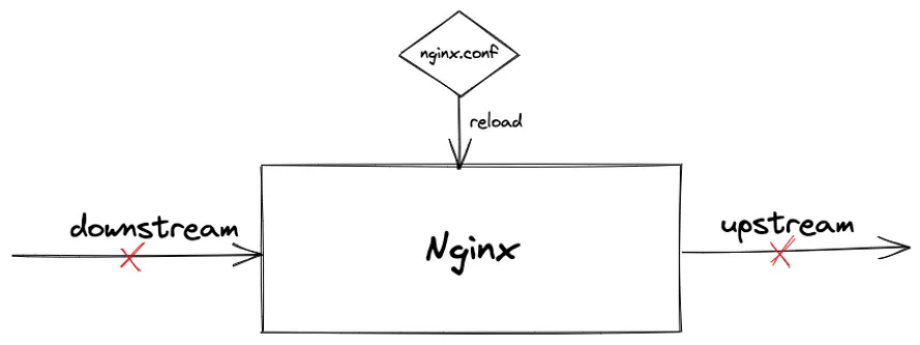
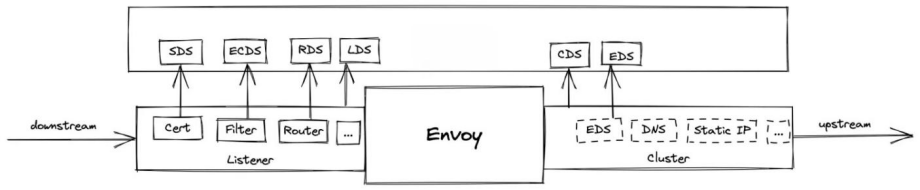
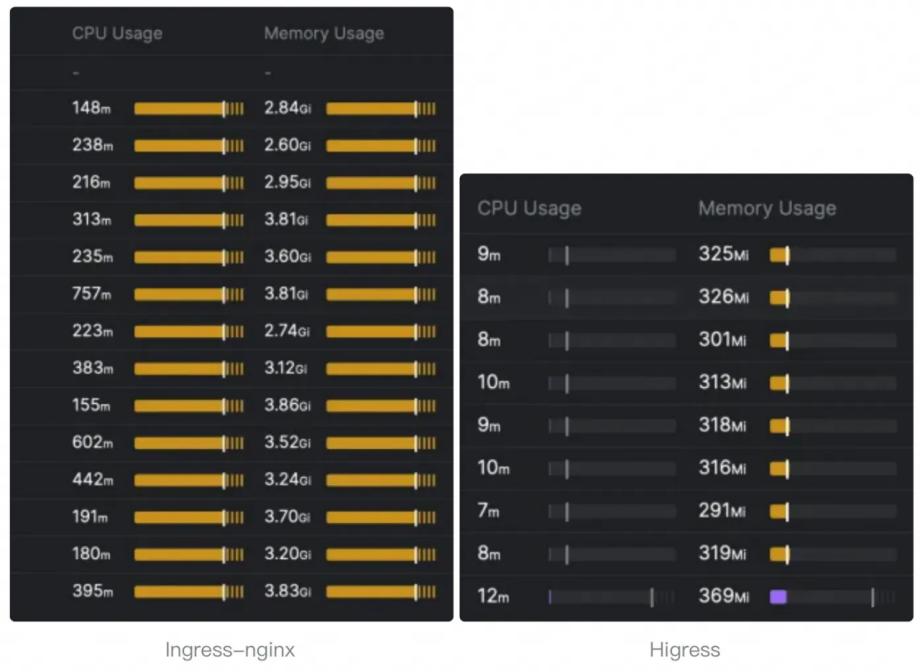
传统 Web 应用中普遍使用的 Nginx 网关难以应对以上新需求,例如变更配置需要 Reload,导致连接断开,不具备安全防护能力等。因此国内外均出现了大量基于 Envoy 为内核的新一代开源网关,本文将以笔者维护的 Higress (https://github.com/alibaba/higress) 为例展开描述。
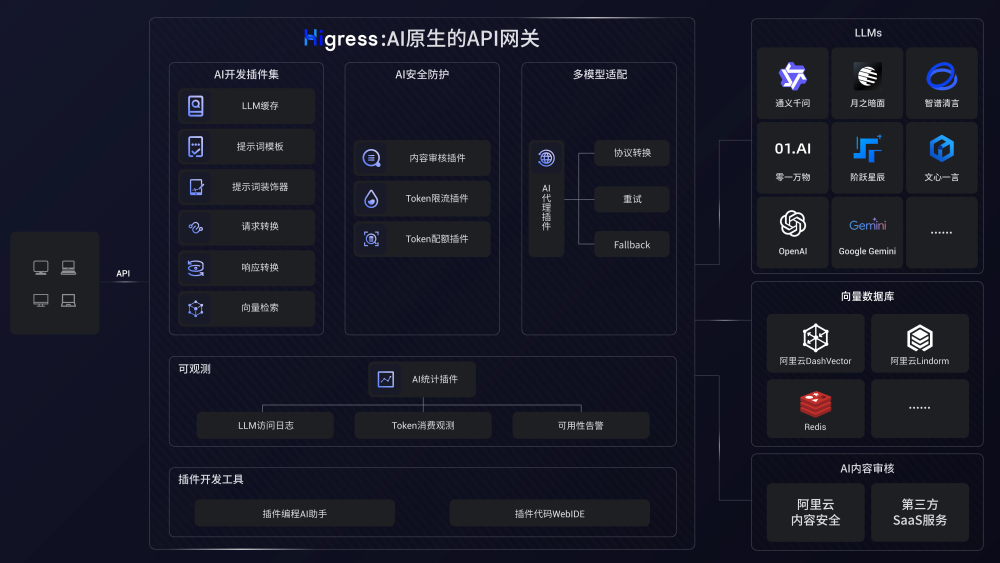
Higress 已经为通义千问 APP、灵积平台 (通义千问 API 服务)、人工智能平台 PAI 提供 AI 业务下的网关流量接入,以及多个头部 AGI 独角兽提供 API 网关。这篇文章详细介绍了 Higress AI 网关的能力:《Higress 发布 v1.4,开放 AI 网关能力,增强云原生能力》
如何实现网关配置的热更新
互联网从 Web 1.0 演进到 Web 2.0 的时代,互联网从静态内容为主,变为动态更新的 UGC 内容为主,大量用户开始高频使用互联网。用户使用形态,以及网站内容形态的改变,催生了大量技术的变革。例如 HTTP 1.0 到 HTTP 1.1 协议的升级,解决了连接复用的问题。又例如以 Nginx 为代表的基于异步非阻塞的事件驱动架构的网关诞生,解决了 C10K 问题。
此外,当大模型未经过适当的过滤和监控就生成回应时,它们可能产生包含有害语言、误导信息、歧视性言论甚至是违反法律法规的内容。正是因为这种潜在的风险,大模型中的内容安全就显得异常重要。在 Higress 中,通过简单的配置即可对接阿里云内容安全服务,为大模型问答的合规性保驾护航。
func onHttpRequestBody(ctx wrapper.HttpContext, config Config, chunk []byte, isLastChunk bool, log wrapper.Log) []byte {log.Infof("receive request body chunk:%s, isLastChunk:%v", chunk, isLastChunk)return chunk}
在 AI 场景下,因为大带宽 / 高延时的流量特征,网关是否对请求 / 响应进行真正的流式处理,影响是巨大的。
-
给每个用户 or 每个模型分配一个域名,数量级达到一万规模时,新建路由的生效速度至少要 1 分钟; -
对多个租户域名使用同一本泛域名证书,开启 HTTP2 时,浏览器访问会遇到 404 问题。
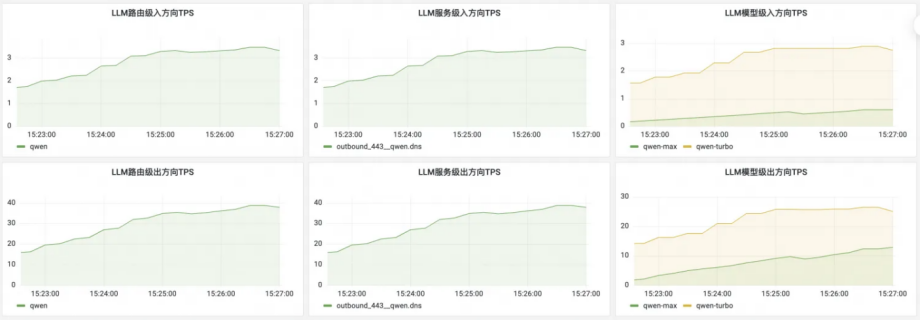
对于第一个问题,其根本原因在于路由规则下发方式不够精细,社区开发者对此进行过分析。与此相比,Higress 可以在域名级别进行分片加载,即使达到一万个域名,新增路由的生效时间也只需三秒。此外,Higress 支持按需加载机制,即只有在接收到特定域名的请求时才加载该域名下的路由配置。在配置了大量域名的环境下,这种策略只加载活跃的路由配置,显著减少了网关的内存使用。
Higress 支撑海量域名的能力,也是众多 MaaS/SaaS 服务用于实现多租的关键。比如智算服务 PAI- 灵骏平台在近期将网关从同样基于 Envoy 实现的 Contour 迁移到了 Higress 之后,新增路由生效的时间从分钟级变为秒级,同时整体消耗的云资源也大幅下降。
三、AI 场景下,网关比我们想象中更能打
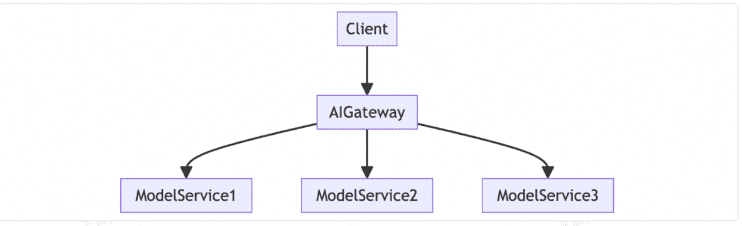
负载均衡:
流量灰度和观测:
AGI 厂商高度依赖 A/B 测试和服务灰度能力来进行模型迭代。作为流量入口,AI 网关需要在流量灰度和观测方面发挥关键作用,包括灰度打标以及入口流量延时和成功率等指标的监测。Higress 凭借其在云原生微服务网关领域的经验,已经积累了强大的能力来满足这些需求。
-
makelogo.ai:AI 生成产品 Logo -
MyMap.ai:AI 辅助规划 Idea -
Gamma:AI 生成 PPT -
Podwise:AI 辅助查看播客
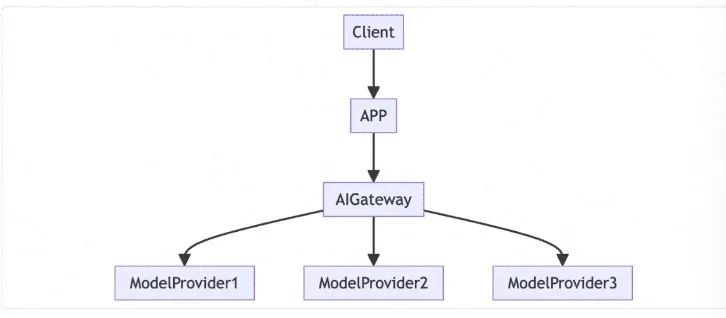
许多 AI 应用开发者,尤其是独立开发者,通常不会自己部署模型服务,而是直接利用模型厂商提供的强大 API 来实现创意应用。值得注意的是,许多开发者来自国内。然而,由于底层技术依赖于 OpenAI 等海外 LLM 厂商,这些技术可能不符合国内法规。为了避免潜在的麻烦,这些开发者往往选择将产品推向国际市场,而不是面向国内用户。
-
通过网关的统一协议,屏蔽不同模型厂商 API 的调用差异,降低适配成本。 -
对涉黄涉政等敏感内容进行屏蔽和过滤,更好地符合国内法规要求。 -
切换模型后的 A/B 测试以及效果观察和对比,包括延迟、成本、用户使用频率等因素。
-
成本分摊计算:借助网关的观测能力,可以审计企业内部不同业务部门的 Token 消耗量,用于成本分摊并发现不合理的成本。 -
提高稳定性:基于网关提供的多模型对接能力,当主用模型调用失败时,可以自动切换至备用模型,保障依赖 AI 能力的业务稳定性。 -
降低调用成本:在一些固定业务流程中,LLM 接口的输入输出相似性较高时,可以基于向量相似性进行缓存召回,从而降低企业的 AI 调用成本。 -
认证和限流:通过对企业内员工的 API 调用进行限量控制,管理整体成本。 -
内容安全:实现统一的内容安全管理,禁止发送敏感数据,防止企业敏感数据泄漏。

-
从用户角度看,用户从主动参与互联网转变为通过 AI 帮助参与。 -
从内容角度看,不仅需要服务于真实用户,还要同时服务于 AI。
Perplexity 这样的工具还只是基于静态内容,可以类比为 AI 时代的 Web 1.0。可以预见,AI 时代的 Web 2.0 会是:
-
电商场景下,在用户浏览商品时,AI 将充当导购,根据商品信息与用户对话,并在用户确认后自动下单; -
出行场景下:AI 将根据用户的出行目标地点自动安排旅行计划,了解用户喜好,预订沿途餐厅和酒店; -
OA 场景下:用户需要操作资源时,AI 将自动提交审批申请,查询审批状态,并在获批后完成资源操作。
在这种模式下,AI 需要理解互联网内容,并识别页面中提供的“可操作能力”,从而代替人类执行操作。苹果宣布将在 iOS 18 中 大幅提升 Siri 的能力,未来 Siri 将能够访问应用程序的各种功能,这也需要应用程序为 AI 提供“可操作能力”的声明。HTML 也有相关社区提案,让 AI 可以更方便地识别页面中的可执行任务,明确其输入和输出定义。
对网关来说,应回归本质,在 AI 的加持下,帮助用户做好 API 的设计、管理将成为核心能力。而通过合理设计的 API,网关也可以更深入地了解所处理流量的业务含义,从而实现更智能化的流量治理。
