分享大纲
Phi模型系列(暂不包含Phi-3):
-
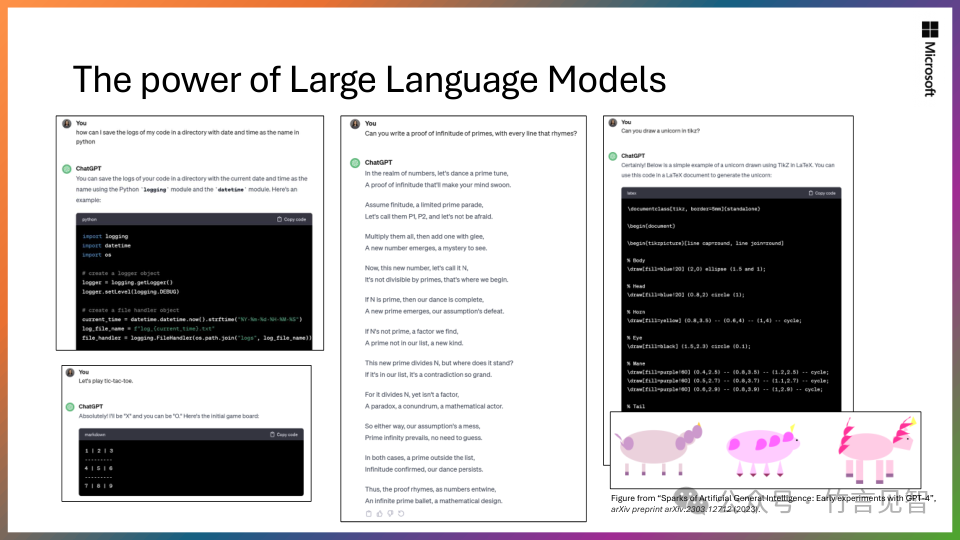
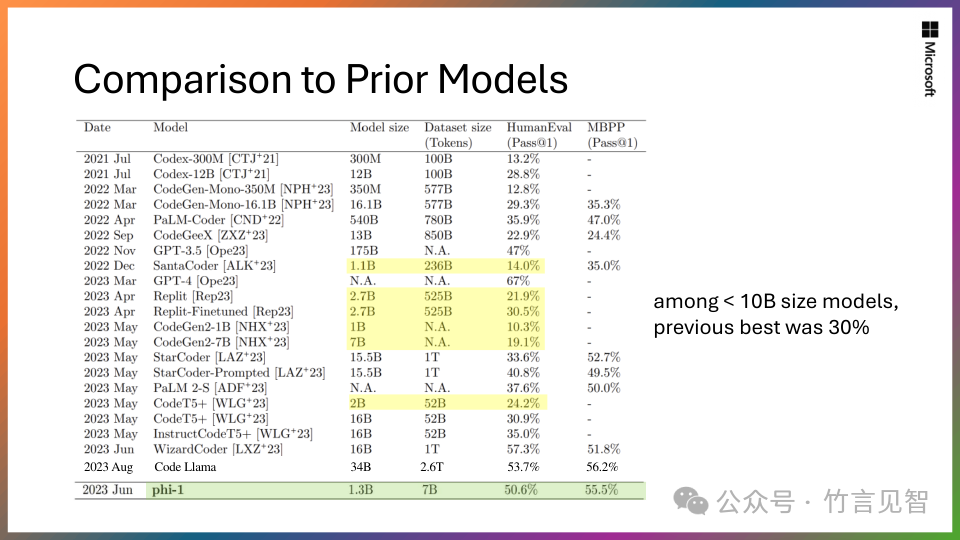
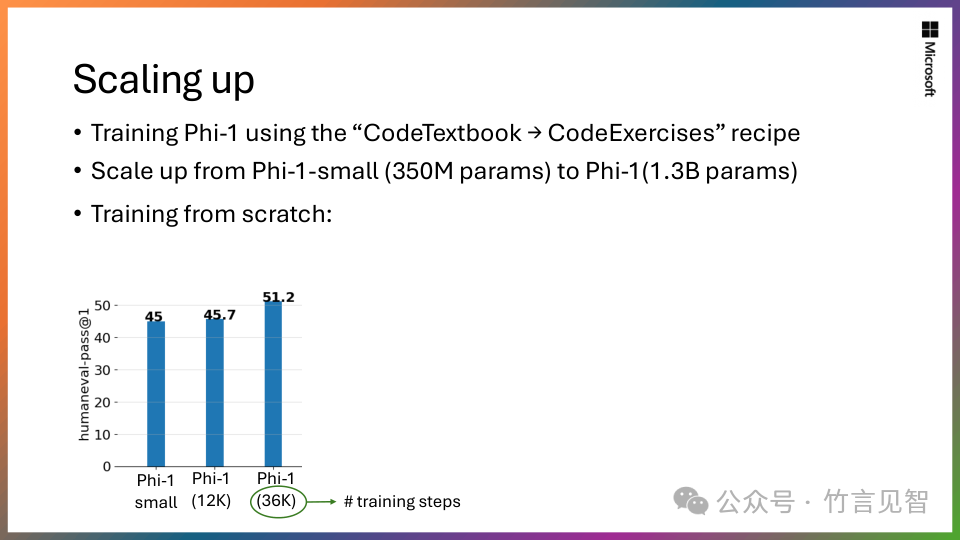
Phi-1:Phi系列第一个模型,拥有13亿参数,在Python编程基准测试中达到同期SLMs中的最先进性能。
-
Phi-1.5:同样拥有13亿参数,专注于常识推理和语言理解,性能与比它大5倍的模型相当。
-
Phi-2:拥有27亿参数,展现出卓越的推理和语言理解能力,在少于130亿参数的基础语言模型中表现最佳。在复杂基准测试中,Phi-2与比它大25倍的模型相匹配或更优。
Phi-2的关键洞察:
-
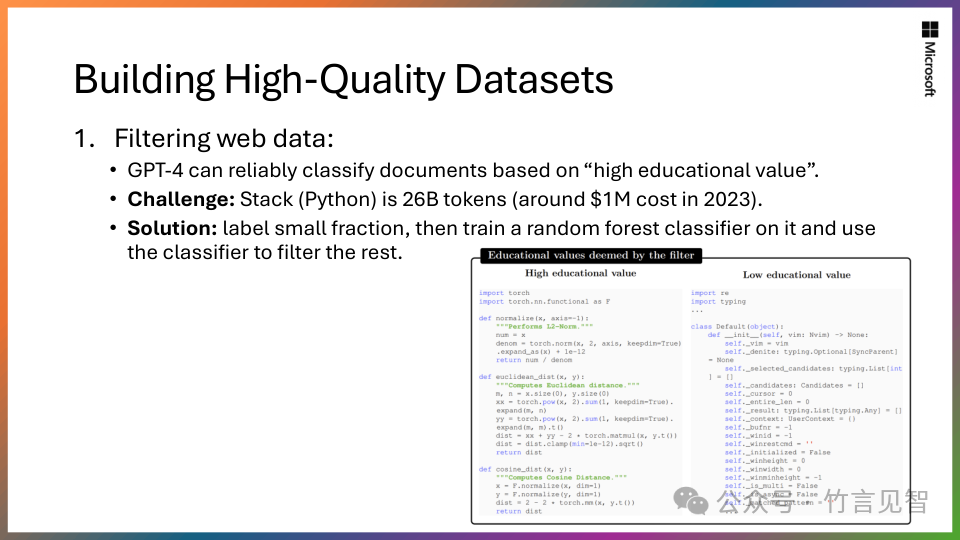
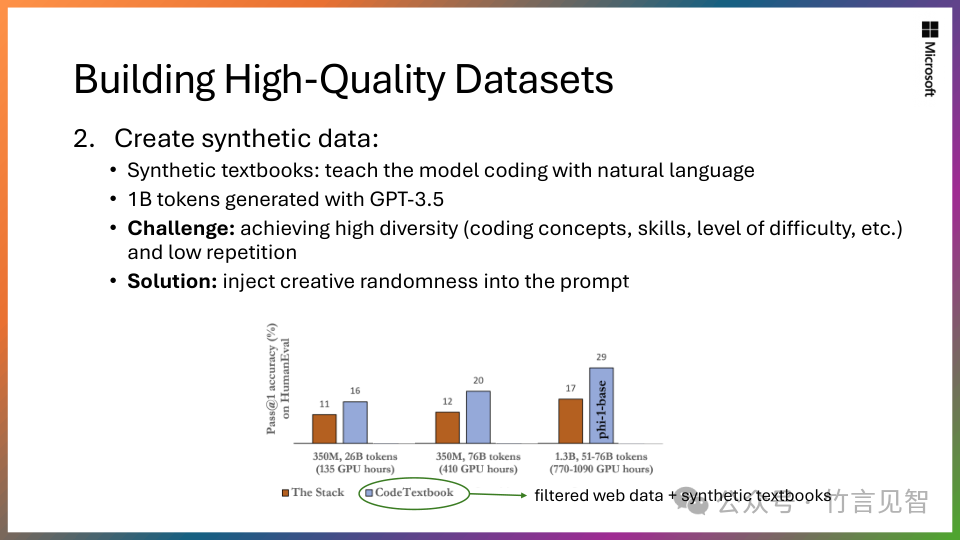
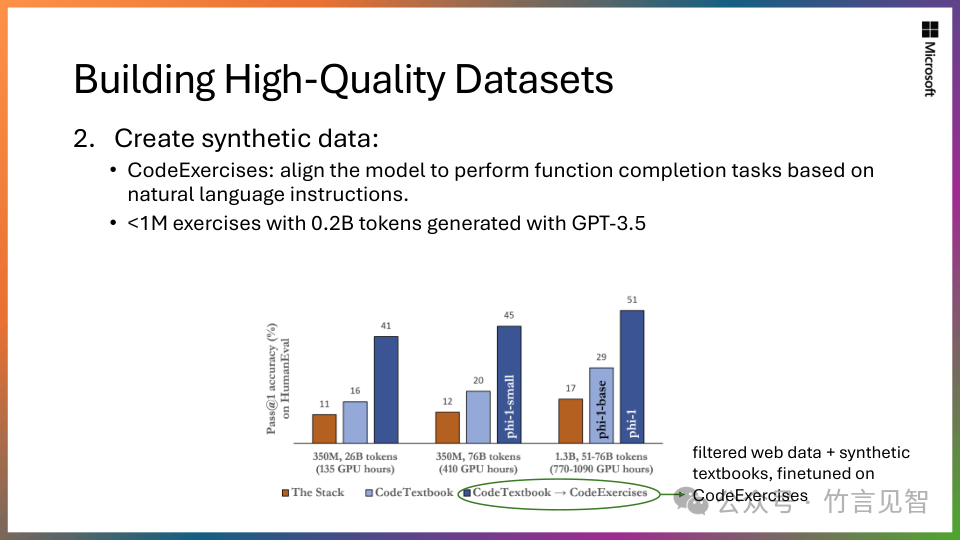
训练数据质量:对模型性能至关重要,Phi-2专注于“教科书级高质量”数据,包括合成数据集,模型常识推理和一般知识。
-
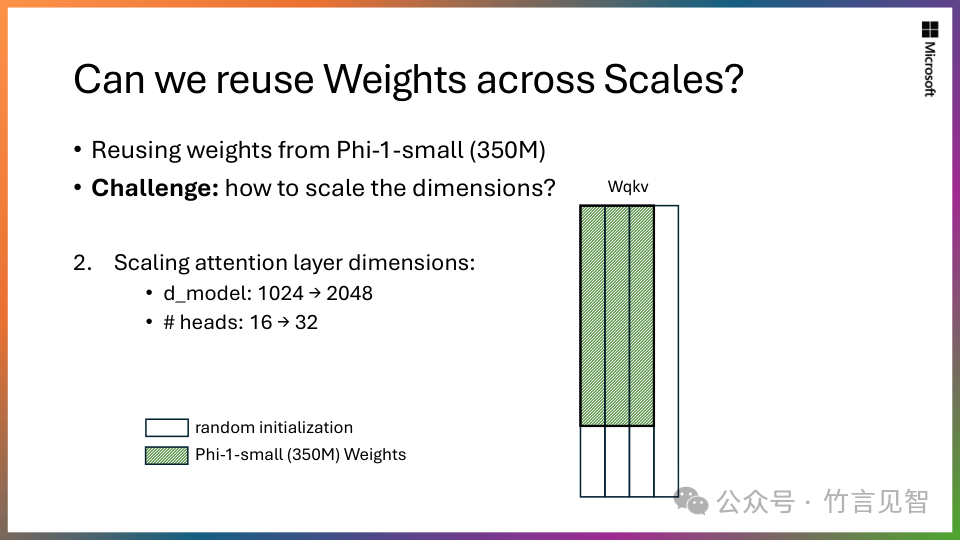
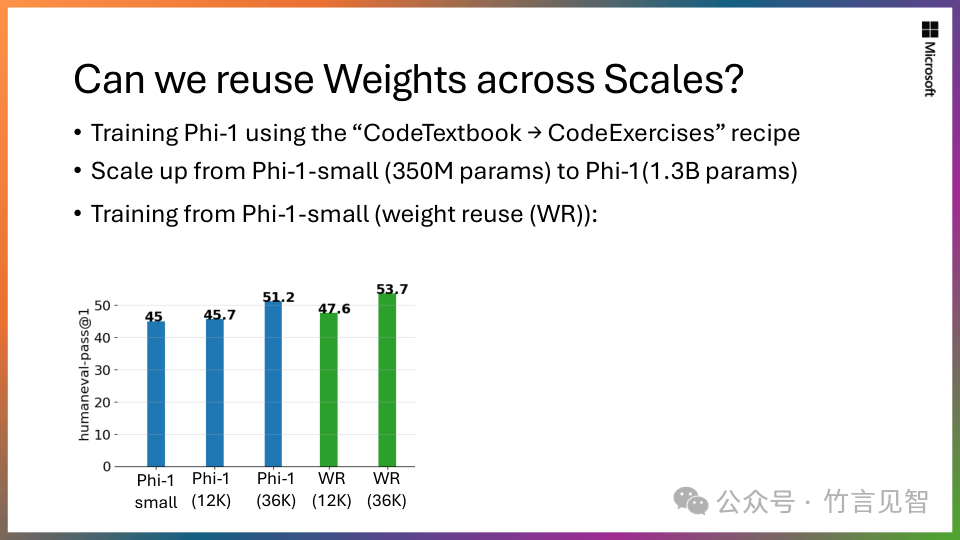
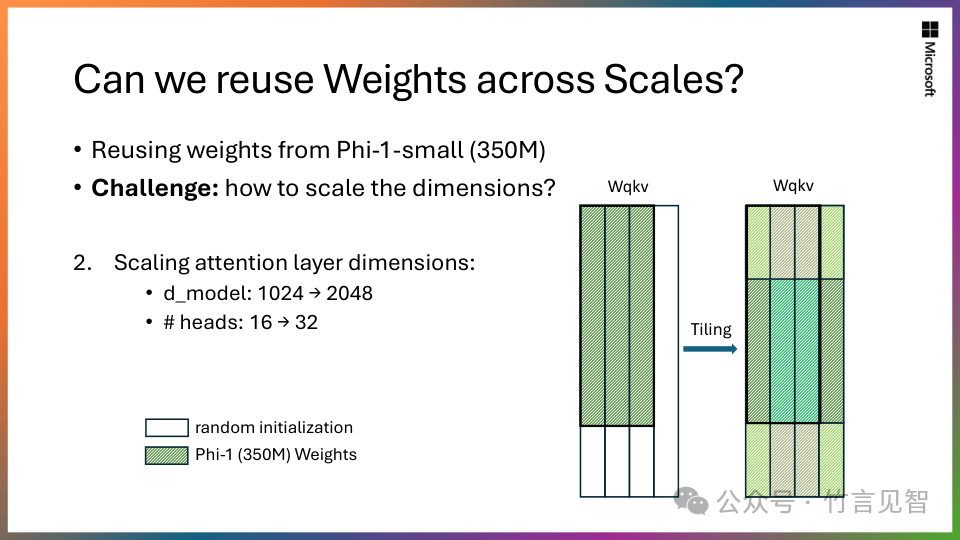
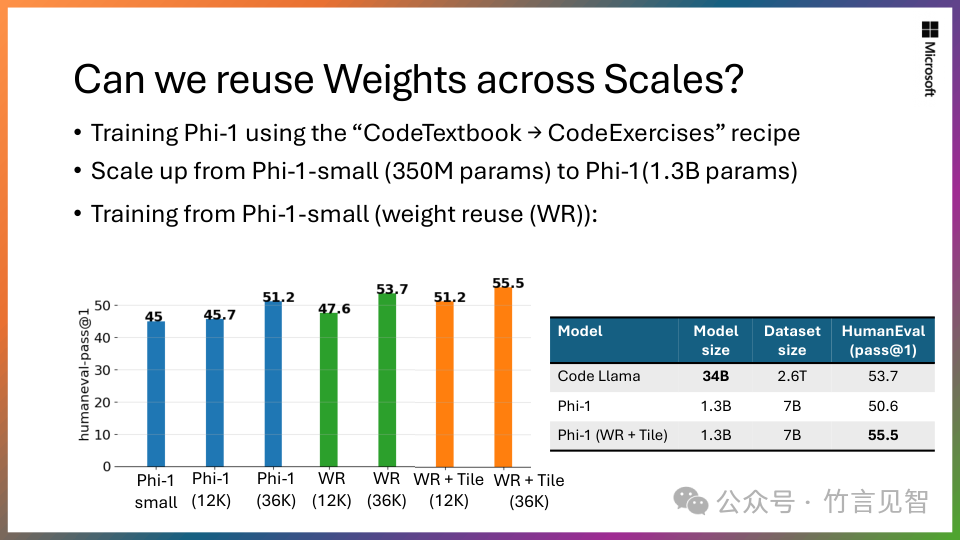
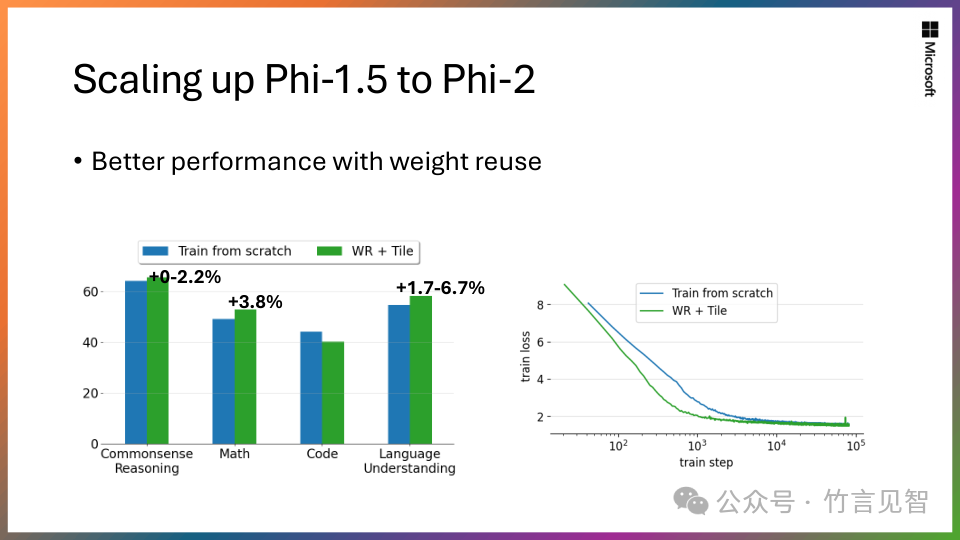
可伸缩知识转移:从拥有13 亿参数模型 Phi-1.5 开始,将其知识嵌入到 27 亿参数 Phi-2 中。这种规模化的知识转移不仅加速了训练收敛,而且显着提高了 Phi-2 基准分数。
Phi-2训练细节:
-
Phi-2基于Transformer模型,使用了1.4T的token,使用高质量的“教科书质量”数据,以及合成数据集。
-
训练使用96个A100 GPU,耗时14天。
-
作为基础模型,无RLHF进行对齐,也没有指令微调。
Phi-2评估:
-
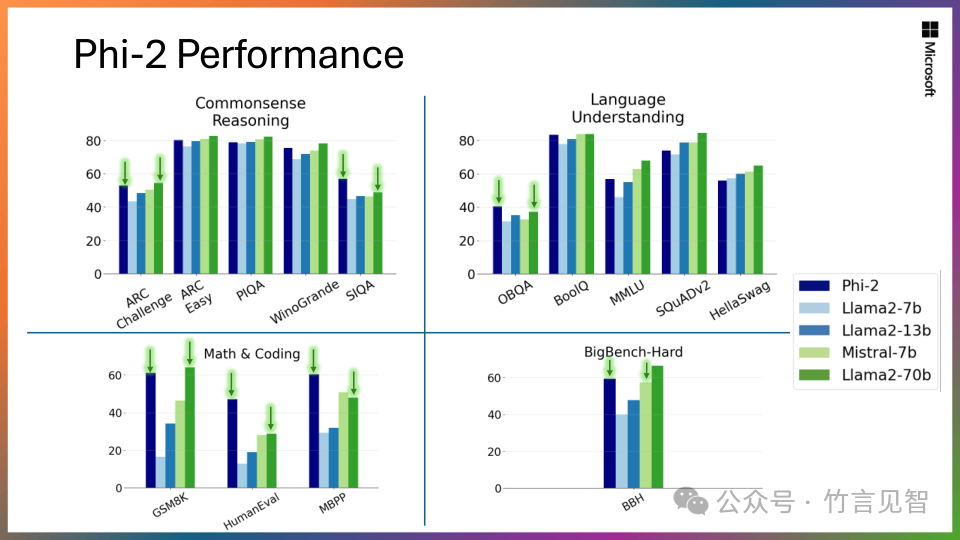
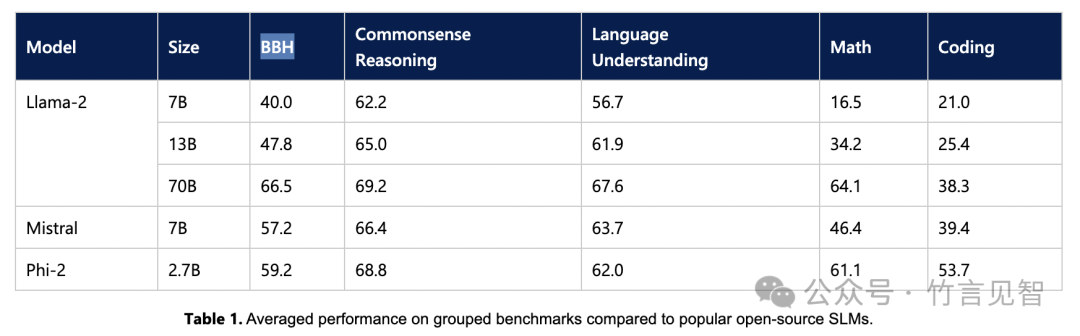
在多个学术基准测试中(包括BBH、常识推理、语言理解、数学和编程等),Phi-2的性能超过了7B和13B参数的Mistral和Llama-2模型。
-
在多步推理任务(即编程和数学)上,Phi-2的性能甚至超过了比它大25倍的Llama-2-70B模型。
-
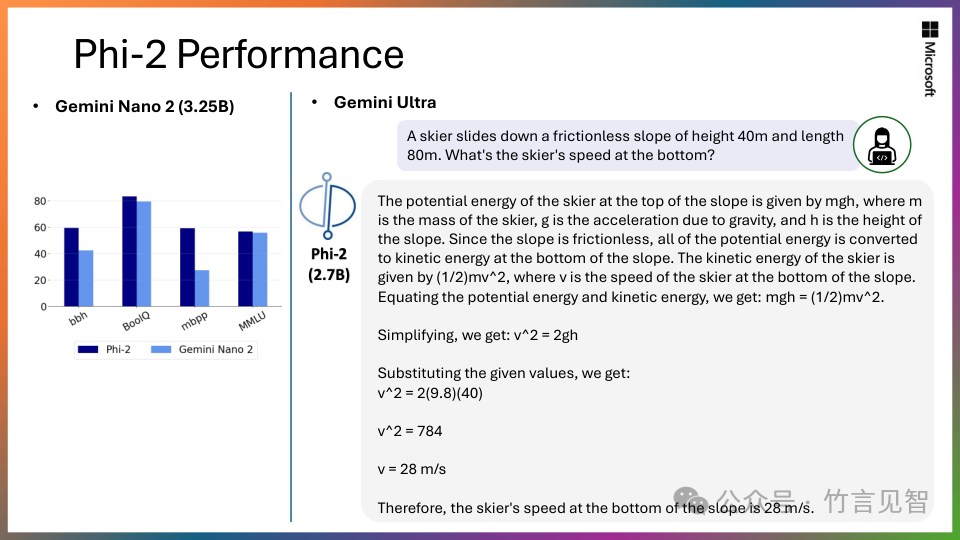
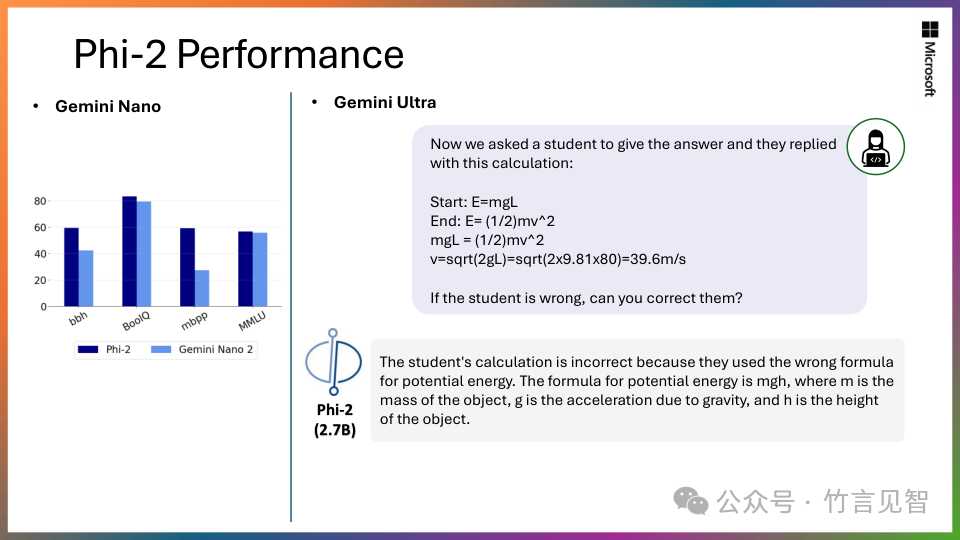
尽管模型大小较小,但Phi-2与Google Gemini Nano 2模型性能相当或更优。

Phi-2安全性和偏见:
-
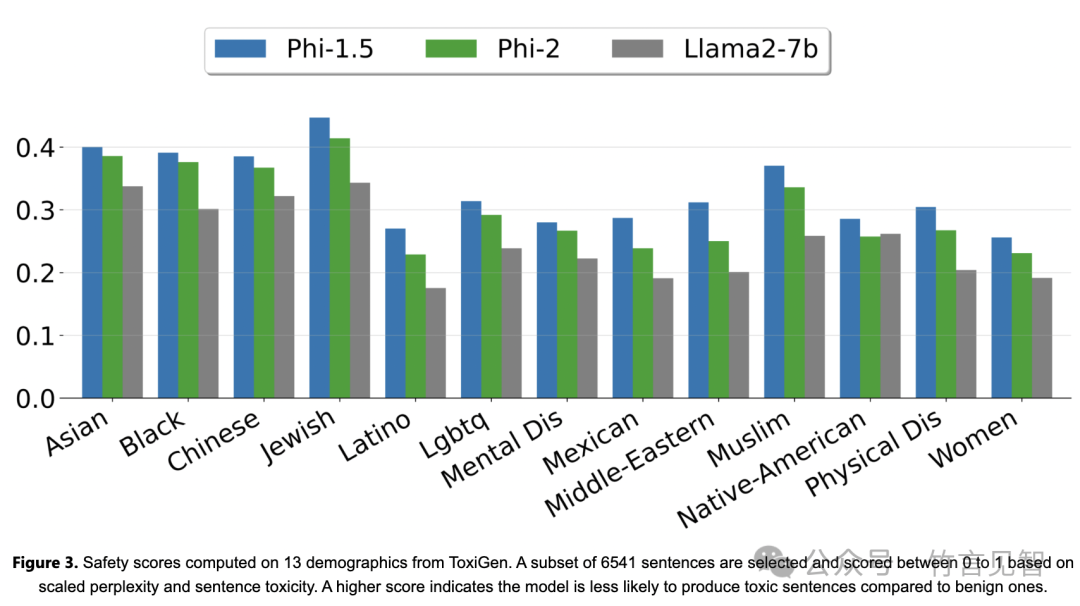
Phi-2在安全性和偏见方面的行为优于经过对齐的现有开源模型,这归功于定制的数据策划技术。
分享的主要内容