

导读
前面提到过pdf文档解析一个很重要的模块就是阅读顺序预测,尽管输出正确的阅读顺序似乎是一个基本要求,但由于文档格式多样(例如表格、多栏等),从文档图像中获取适当的阅读顺序并非易事,大多数OCR引擎也未能提供正确的阅读顺序,通常使用规则来判断阅读顺序,比如按照从上到下、从左到右的顺序输出。无法适用于多栏等复杂文档类型。另外虽然深度学习模型在特定领域表现出色,但需要大量人工标注数据集,在本文之前不存在这种用于阅读顺序预测的数据集
本文提出的LayoutReader,有以下创新之处:
-
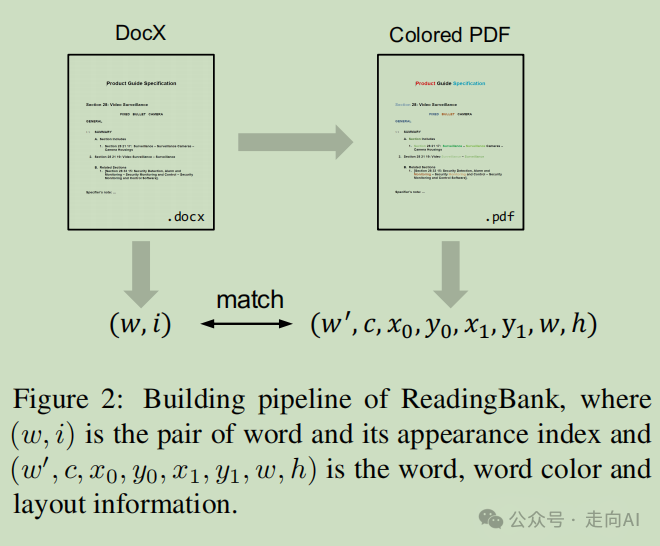
ReadingBank数据集:通过自动化的方式从微软WORD文档的XML格式中提取阅读顺序信息,简化了数据准备过程。得到了一个包含500,000个真实世界文档图像的基准数据集,为阅读顺序检测提供了大规模、高质量的标注数据。
-
LayoutReader模型:提出了一个新的阅读顺序预测模型,使用序列到序列模型编码文本和布局信息,生成阅读顺序索引序列。
-
多模态信息融合:消融研究表明,结合文本和布局信息对于最终性能至关重要,LayoutReader在两种模态下表现卓越。
-
论文名称:LayoutReader: Pre-training of Text and Layout for Reading Order Detection -
论文地址:https://arxiv.org/pdf/2108.11591
-
代码地址:https://github.com/microsoft/unilm/tree/master/layoutreader

Introduction
# 构建ReadingBank
# LayoutReader模型
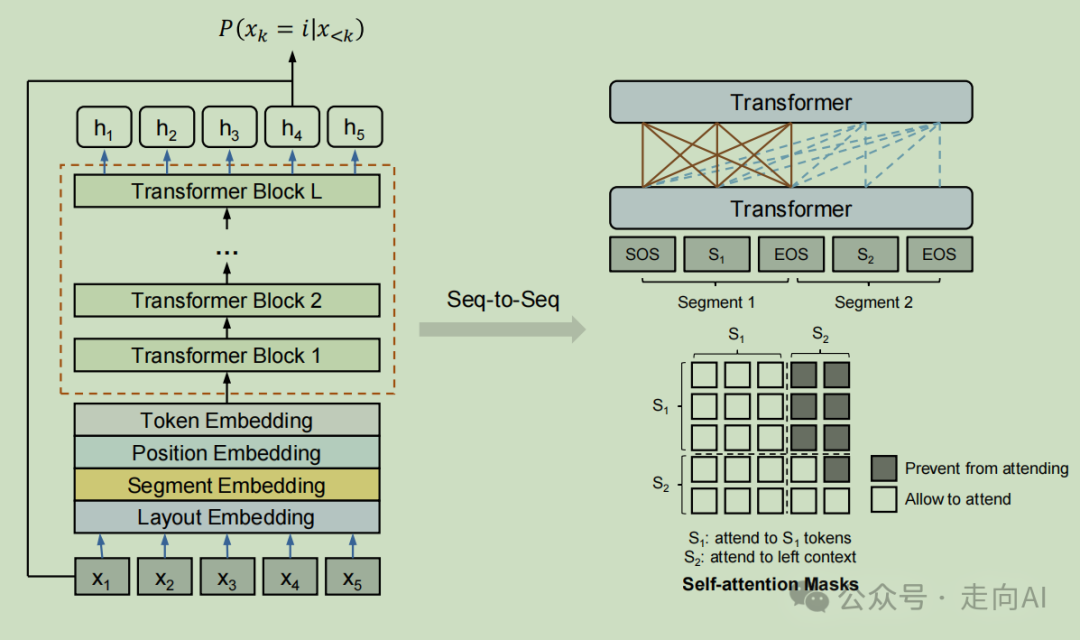
LayoutReader模型结构
优势:
-
文本和布局信息融合:LayoutReader 通过结合文本内容和布局信息,提高了阅读顺序检测的准确性。
-
布局感知编码:使用 LayoutLM 作为编码器,LayoutReader 能够理解文档的布局结构,这对于复杂文档的阅读顺序检测至关重要。
-
精细控制的自注意力机制:通过精心设计的自注意力掩码,LayoutReader 有效地控制了编码阶段的信息流,防止了不正确的阅读顺序信息的干扰。
-
高效的解码策略:在解码阶段,LayoutReader 通过预测源序列中的索引,简化了解码过程,并提高了生成阅读顺序的准确性。
点评
虽然从现在的角度看本文的方案LayoutReader已经过时,但文中提出的提出的一套生成带阅读顺序的文档图像数据pipeline至今仍然是有意义的。
但仍然存在以下缺点:
-
代码中有许多实验性质的代码,组织不够清晰,训练和部署都很困难。
-
seq2seq在生产环境中速度太慢,我们希望一次性完成所有预测 -
预训练模型的输入是英文单词级别,但实际情况并非如此。真正的输入应该是PDF解析器或OCR提取的文本片段(行级别或者段级别)。
-
只支持英文,不支持多语言。
这里推荐其他作者基于HF的Transformers里的LayoutLMV3实现的LayoutReader:
https://github.com/ppaanngggg/layoutreader
-
重构代码,使用
transformers库中的LayoutLMv3ForTokenClassification进行训练和评估。 -
提供一个脚本,将原始的单词级别数据集转换为文本片段级别数据集。
-
实现一个更好的后处理程序,以避免重复预测。
-
发布一个预训练模型,该模型从layoutlmv3-large微调而来,现已在Hugging Face上提供。
根据作者readme的介绍,其改进后的版本仅使用box框,没有使用text信息,也做到了和论文中相当的水平。
